论文笔记 | VAIN: Attentional Multi-agent Predictive Modeling

Hoshen Y. VAIN: Attentional Multi-agent Predictive Modeling[J]. arXiv preprint arXiv:1706.06122, 2017.
原文:https://arxiv.org/pdf/1706.06122.pdf
简介:
这篇文章来自多agent领域,主要讲述在其它agent的影响下,当前agent的状态如何进行更新。在本文中,作者提出了一种attention模型,每个agent的状态预测是由所有agent信息的加权整合和自身状态信息的交互完成的。
这种思想与两篇ICLR 2018 submissions,即GCN with attention mechanism,非常相近且发布较早(2017年6月)。
背景:
在多agent系统中,信息是极其不规则的,多个agent之间既无固定的空间结构,也没有自然的顺序关系。因此,成熟的深度学习方法CNN、RNN等不能直接应用于多agent系统的建模。已有工作IN(Interaction Networks)最早提出使用深度学习模型解决多agent系统中每个agent状态预测问题,其关键步骤是计算agent之间两两的交互特征,然后再与agent自身的非交互特征相融合。
不难看出其复杂度是agent数量的平方,大大限制了应用场景。之后,CommNet提出了一种线性的方法,去掉了计算两两交互特征,取而代之的是为每个agent计算一个服务于其它agent的特征,这个特征是独立计算的,不依赖与其它agent。因此,CommNet的复杂度降为线性。
模型:
总结IN和CommNet两种算法,一种充分利用了agent之间的交互信息但复杂度较高,一种降低复杂度的同时弱化了agent之间的交互。
本文可以看作是在CommNet的基础上,增加了attention模型。在保持线性复杂度的同时,对agent之间的交互更好地建模。
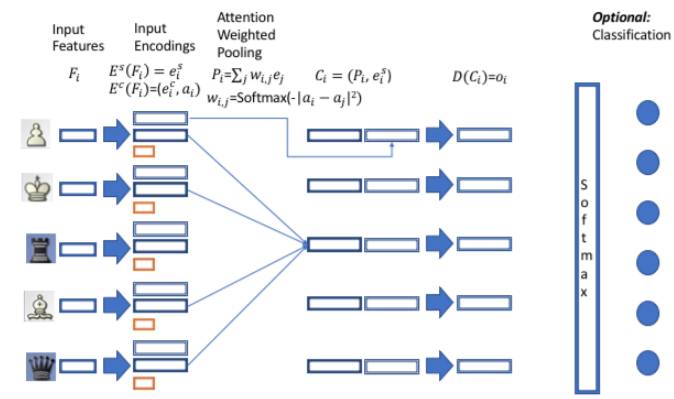
模型框架如上图。在输入层,F_i代表agent i的原始特征,如类型、位置等信息。第二部包涵两个编码器:编码器E_s将F_i转化为 agent的自身特征,编码器E_c通过F_i生成agent用来交互的特征及attention向量。在第三部,以加权平均的方式将所有agent( 不包含自身)的交互特征进行组合,计算公式如下:
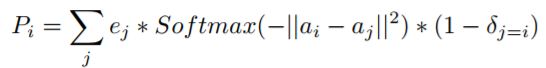
第四部,作者使用拼接方式将交互特征P_i和自身特征e_i进行融合,得到中间表示C_i。然后设计了一个解码器D(全连接网络),将中间表示C_i映射为标量(回归任务)或向量(分类任务)o_i.对于分类任务,将输出o_i做softmax即可。
思考:
本文的工作与GCN with attention极其相关。个人认为,主要区别有:
1)GCN是以图作为输入的,每个节点并非从其它所有节点接受信息而是邻居节点。
2) Attention的计算方式不同,本文的attention score计算方式区别于传统计算方法,相当于衡量两个agent的attention vector之间的欧式距离。
作者:宋卫平,北京大学在读博士,研究方向为深度学习,推荐系统,网络表示学习。





