EMNLP 2021 | 学习改写非自回归机器翻译的翻译结果
论文名称:Learning to Rewrite forNon-Autoregressive Neural Machine Translation 论文作者: 耿昕伟,冯骁骋,秦兵 原创作者: 耿昕伟 论文链接: https://aclanthology.org/2021.emnlp-main.265.pdf 转载须标注出处:哈工大SCIR
1. 简介
非自回归机器翻译[1]由于其解码过程不依赖于之前翻译结果从而获得很高的推理速度,但是其翻译质量相对较差。近期许多工作将迭代式[2,3]的解码策略引入非自回归机器翻译中,其通过多次优化先前的翻译结果从而提升最终翻译质量。但是,其中一个显著问题是在迭代式解码过程中这些方法并不能显示区分翻译结果中的错误。在本工作中,我们提出一个新的非自回归机器翻译架构RewriteNAT,其可以学习改写翻译结果的错误内容。该架构使用一个定位模块识别翻译中的错误,而后使用另一个改写模块将其改写成正确翻译内容。此外,为了保证训练和迭代式解码过程中输入数据分布的一致性,我们采用迭代式的训练方法进一步提升模型的改写错误能力。在多个广泛使用的翻译数据上的实验结果显示,相比多个传统的迭代式非自回归方法,我们提出方法可以获得更好的翻译性能,同时显著的减少解码时间。
2. 模型结构
我们提出的RewriteNAT主要有三个模块组成,即编码器、错误修改器以及错误定位器。本文使用的编码器与传统的TRANSFORMER[4]编码器类似,将输入的源语言编码成连续的向量表示。而本文的解码器,其主要由错误修改器和错误定位器组成,其主要负责修改和识别生成的翻译结果中的错误信息。本文提出的RewriteNAT的框架如图 1所示。
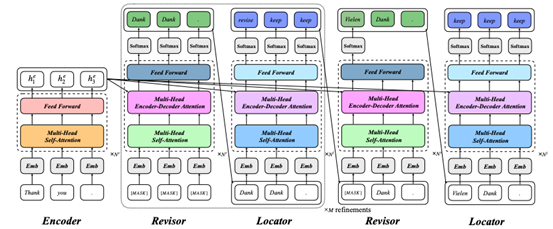
图 1 基于显式改写机制的非自回归机器翻译框架
2.1 错误修改器
给定错误定位器标注过的翻译结果Y^r,错误修改器主要负责将错误的翻译片段修改其对应的正确形式。具体来说,我们期望错误修改器在给定源语言的向量表示以及翻译中的正确的内容条件下,在翻译中被标注为[MASK]的错误位置上重新生成正确的翻译内容。给定的错误定位器的标注结果 ,本文使用多个与传统非自回归翻译解码器类似的TRANSFORMER[4]块生成其相应的表示 :其中代表由 个Transformer块构成错误修改器。此后,翻译中被标注为[MASK]的错误位置对应的表示将被输入到一个分类器 从而重新生成目标语言的翻译:其中 和 是可训练的参数。错误分类器 重新生成的翻译结果将替换翻译中被标注为[MASK]的错误翻译内容,从而获得新的翻译结果 :

而 被输入到错误定位器中。
2.2 错误定位器
给定错误修改器生成的翻译结果,本文使用错误定位器对翻译结果的每个词语正确性进行判断。对于翻译中的每个词语,其可以被分类成两个类别即修改(revise)和保持(keep)。根据定位器的分类结果,本文对输入的翻译结果进行修改而后作为错位修改器的输入修改其中的错误信息。具体来说,本文将翻译中被标注为revise的词语替换成特殊的符号即[MASK],其他的保持不变。给定生成的翻译结果 ,本文使用多个与传统非自回归翻译解码器类似的TRANSFORMER块将翻译 转化成隐含层表示 :其中表示由 个Transformer块构成错误定位器。而后,错误定位器以其为输入对于翻译的词语进行分类。根据分类的结果,翻译 修改成 :

其中 被作为错误修改器的输入。
3. 实验结果
3.1 翻译结果
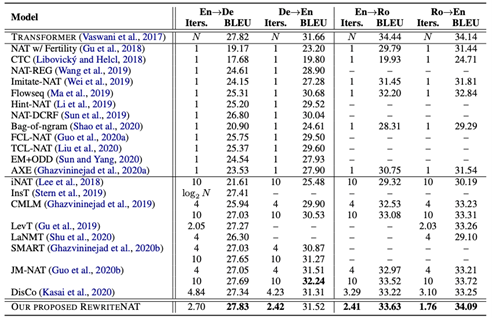
本文在四个标注机器翻译数据集上评价本文提出的RewriteNAT的性能,即WMT14英-德(4.5M)和英-法(36M)、WMT16英-罗马尼亚(610K)以及WMT17英-中(20M)。我们使用知识蒸馏构建新的数据集从而缓解多模式的问题,其中对于英-德、英-法以及英-中本文使用TRANSFORMER-BIG[4]模型生层蒸馏数据,而对于英-罗马尼亚使用TRANSFORMER-BASE[4]模型。本文使用BLEU评价翻译的模型的质量。如表 1所示,在WMT14英=>德(27.83 vs. 27.82)、德=>英(31.52 vs. 31.66)以及罗马尼亚=>英(34.09 vs. 34.14)翻译数据上,本文提出的RewriteNAT可以获得和传统的自回归机器翻译模型取得可比翻译性能。
表 1 基于显式改写机制的非自回归机器翻译模型在WMT14英-德和英-法上结果
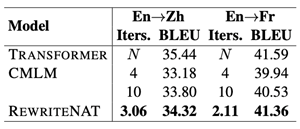
此外,为了证明提出的模型在大规模数据上的鲁棒性,我们在英=>法和英=>中任务上验证模型的性能。如表 2所示,本文提出的RewriteNAT模型相比高性能CMLM[3]在翻译质量和速度上取得一致的提升。特别地,RewriteNAT在英=>法翻译任务上取得与自回归机器翻译上取得可比的结果,但是平均仅需要较少的迭代次数。
表 2 基于显示改写机制的非自回归机器翻译模型在英=>中和英=>法任务上的结果
3.2 解码速度
相比传统的典型的迭代式的非自回归机器翻译模型,本文提出RewriteNAT可以获得一致的提升,但是需要更少的迭代次数。如图 2所示,本文提出的RewriteNAT获得同样翻译性能,但是拥有更快的解码速度。当最大的迭代次数为2时,RewriteNAT可以获得和CMLM以及基于贪心算法的TRANSFORMER同样的性能,但是其加速比可以达到7.02x。随着最大迭代次数的增加,RewriteNAT性能可以获得进一步的提升,直到最大的迭代次数达到4。特别的,当最大迭代次数为4时,RewriteNAT可以获得与基于柱搜索的自回归机器翻译(27.77 vs. 27.82, 3.86x)达到相同的结果。
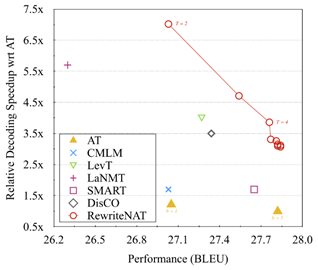
图 2 在WMT14英=>德翻译上RewriteNAT相对自回归翻译模型的加速比
4. 实验分析
4.1 词汇重复率
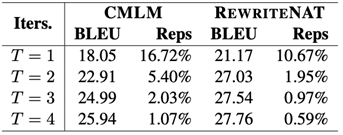
非自回归机器翻译模型由于无法显示的建模上下文依存关系从而导致其无法很好的处理多模式的问题[5]。为了评价提出的模型多模式的问题程度,本文通过计算翻译结果中连续的重复词的比例,从而间接的评价提出模型多模式问题程度。如表 3所示,RewriteNAT模型中的词汇重复率明显小于采用同样迭代次数的CMLM模型。
表 3 WMT14英=>德任务上翻译性能和词汇重复率随着迭代次数变化
4.2 词性分析
除了比较提出的模型相比传统的非自回归模型的性能提升,本文还分析词汇生成需要的迭代次数与其相应的词性的关系。如图 3所示,RewriteNAT倾向于在解码的早期生成标点符号。而后,名词是仅次于标点符号的容易生成词性。而其他主要作为修饰性成分的词性比如形容词、副词以及介词等,经常在标点符号以及名词之后生成。最后,对于提出的RewriteNAT,动词以及助词是最难预测的,经常在解码的后期生成。
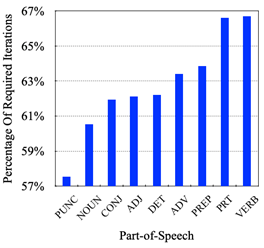
图 3 WMT14德=>英翻译任务上不同词性生成所需要的平均迭代比例
5. 结论
本文提出一个新的迭代式机器翻译框架RewriteNAT,其显式学习改写翻译中的错误信息。实验结果证明相比传统的迭代式非自回归机器翻译模型,本文提出的方法可以获得明显的提升但是仅需要很少的迭代次数。实验分析显示RewriteNAT的词语生成顺序符合easy-first策略。
参考文献
[1] Gu J, Bradbury J, Xiong C, et al. Non-autoregressive neural machine translation[J]. arXiv preprint arXiv:1711.02281, 2017.
[2] Lee J, Mansimov E, Cho K. Deterministic non-autoregressive neural sequence modeling by iterative refinement[J]. arXiv preprint arXiv:1802.06901, 2018.
[3] Ghazvininejad M, Levy O, Liu Y, et al. Mask-predict: Parallel decoding of conditional masked language models[J]. arXiv preprint arXiv:1904.09324, 2019.
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[5] Wang Y, Tian F, He D, et al. Non-autoregressive machine translation with auxiliary regularization[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 5377-5384.
本期责任编辑:赵森栋
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NAMT” 就可以获取《EMNLP 2021 | 学习改写非自回归机器翻译的翻译结果》专知下载链接






