赛尔原创@EMNLP 2021 | 多语言和跨语言对话推荐
论文名称:DuRecDial 2.0: A Bilingual Parallel Corpus for Conversational Recommendation 论文作者:柳泽明、王海峰、牛正雨、吴华、车万翔 原创作者:柳泽明 论文链接:https://aclanthology.org/2021.emnlp-main.356/ 转载须标注出处:哈工大SCIR
1. 背景
传统推荐系统虽然可以较好地解决信息过载问题,但也存在一些主要问题:比如,很难准确且高效地建模用户偏好的动态变化;在推荐过程中,很难直接帮助用户决策等。对话推荐为上述问题提供了一个有希望的解决方案,但之前工作通常集中于单一对话类型,没有考虑如何有效融合多个对话类型(闲聊、任务型对话、问答等)。而真实人机对话,涉及多种对话类型(闲聊、任务型对话、问答等),如何自然地融合多种对话是一个重要的挑战。基于以上考虑,我们在之前工作[1]和[2]中提出一个新的对话推荐任务:融合多个对话类型的对话推荐。在这个任务中,我们期望系统主动且自然地把用户从任意对话类型(比如,闲聊、知识对话、问答等)引导到推荐目标,使得对话推荐:(1)不但可以为用户推荐合适的Item(比如,电影、歌曲等),还可以通过自然地融合多种对话类型,主动把用户从非推荐场景引导到推荐场景;(2)不再假设用户在对话前有明确目标,而是在对话过程中,帮助用户决策,并根据用户反馈而动态调整推荐目标;(3)充分利用之前对话收集的用户偏好,在对话结束后,根据用户反馈,实时更新用户偏好,以便于提高后续对话和推荐的效果。为支持这个任务的相关研究,我们构建了首个融合多种对话类型的中文对话推荐数据集DuRecDial。
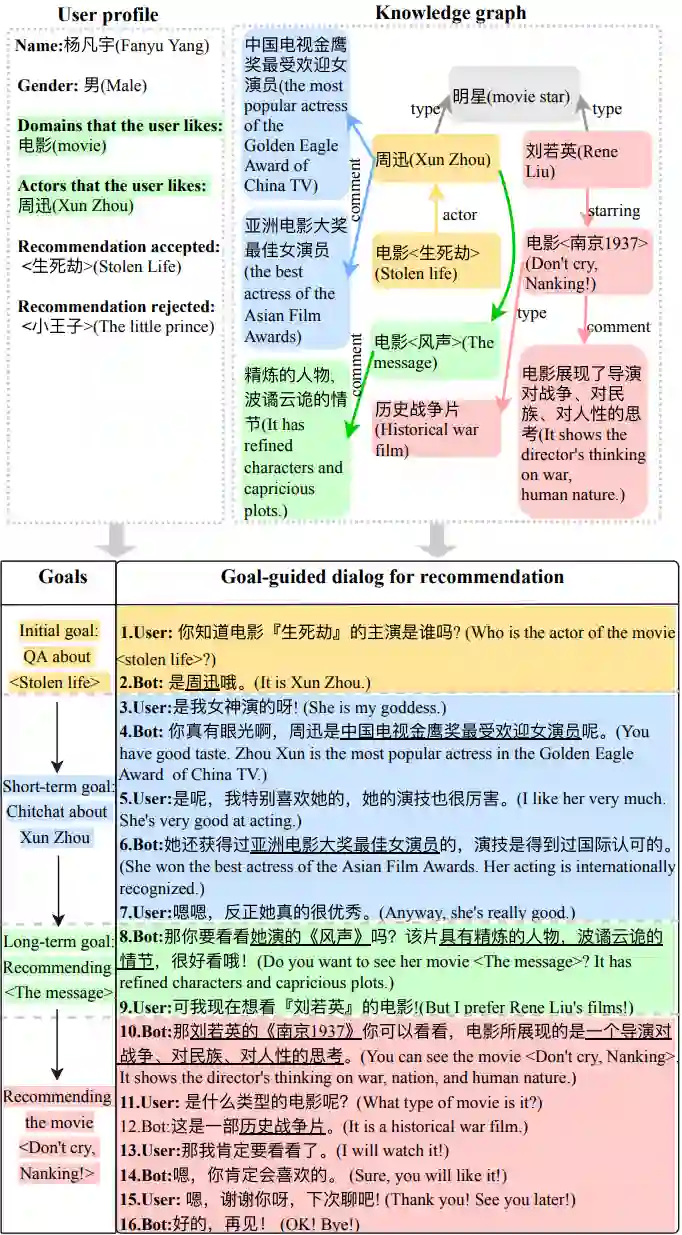
图1 融合多种对话类型的对话推荐样例
2. 简介
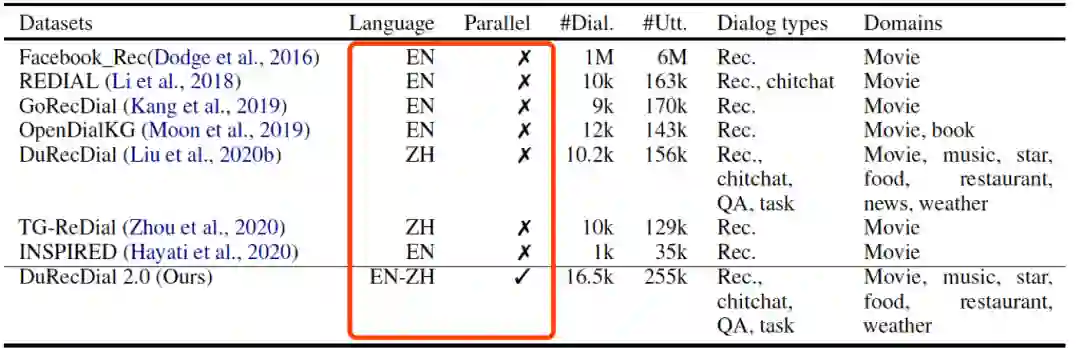
虽然关于对话推荐的研究,在近几年取得长足进步,但是目前的研究都集中在英文或汉语单语设定。先前研究工作表明,在自然语言处理的其他任务中使用多语言可以提升单语言的性能,比如任务对话、语义分析、问答和阅读理解、机器翻译和文本分类等。在对话推荐任务上,多语言设定可能会提升单语言的性能。因此,我们基于DuRecDial,构建了首个中英双语平行的包含多种对话类型、多领域和丰富对话逻辑的human-to-human对话推荐数据集DuRecDial 2.0,使研究人员能够同时探索单语言、多语言和跨语言对话推荐的性能差异,并为多语言对话建模技术的研究提供一个新的基准。DuRecDial 2.0与现有对话推荐数据集的区别在于,DuRecDial 2.0中的数据项(用户Profile(画像)、对话目标、对话所需知识、对话场景、对话上下文、回复)都是中英平行的,而其他数据集都是单语设定。DuRecDial 2.0包含8.2k个中英文对齐的对话(总共16.5k个对话和255k个utterance),这些对话都是通过严格的质量控制流程,由众包人员标注而成。然后,我们基于DuRecDial 2.0,设定了5个任务(包含单语言、多语言和跨语言对话推荐),并基于mBART[3]和XNLG[4]构建单语、多语和跨语言对话推荐的基线模型,支持未来研究。实验结果表明,使用英语对话推荐数据可以提高中文对话推荐的性能。
3. 数据构建与评估
为支持多语言和跨语言对话推荐的研究,我们构造了高质量的中英双语平行数据集DuRecDial 2.0。具体构建过程包括:构建双语平行数据项,构建平行对话和为对话标注所用知识。
3.1 构建双语平行数据项
平行数据项包括:对话所需的知识图谱、seeker(用户)的profile、任务模板、对话场景等。为构建双语平行知识图谱,首先从百度百科、时光网、猫眼、网易云音乐、QQ音乐、美团、百度文库等网站抓取DuRecDial中所用明星、电影、音乐、美食、POI(兴趣点)的英文名,然后通过人工校验和修改,得到由16566个节点和254个边构成的双语平行知识图谱。图谱包括123298个知识三元组,我们随机选择100个三元组,人工评估的准确率为97%。为构建双语平行seeker的profile,我们首先把DuRecDial的profile中个人信息和偏好信息拆分,然后翻译,最后再组合为双语profile。为构建双语平行任务模板,我们首先把DuRecDial的任务模板分解为对话目标序列和目标描述,然后基于上述构建的双语平行知识图谱和人工翻译,构建双语平行任务模板。为构建双语平行对话场景,我们首先把DuRecDial的对话场景拆分为对话时间、地点和主题,然后翻译,最后再组合为双语对话场景。
3.2 构建平行对话
为保证数据质量,我们采用严格的质量控制流程。首先,在翻译前,基于上述构建的双语知识图谱,替换所有对话话语中的entity(实体),以便于保证对话的知识准确率。然后,我们随机选择100个对话(约1500个utterance),然后让超过100个翻译人员来翻译。然后3个有翻译经验的数据专员会随机选择大约20%的utterance,审核1-3次。具体的审核包括词级别、话语级别和对话级别。针对词级审核,专员会审核对话所用实体是不是跟知识图谱一致,翻译时选词是否合理,是否有语法错误等;针对话语级审核,专员会审核话语是否翻译准确,是否口语化,是否有冗余等;针对对话级审核,专员会审核整个对话是否翻译的连贯,是否和DuRecDial平行等。最终,我们选出23个翻译员。筛选后的翻译员每次翻译大约1000个utterance,然后数据专员用上述审核方法随机审核10-20%的utterance,只有当翻译员通过审核,才能继续下次的翻译。
3.3 标注对话所用的知识
由于本任务比较复杂,而且每个对话对应较多知识三元组。在做对话目标规划和知识选择时,非常有挑战,我们TKDE的工作[2]也印证了这一点。因此,除了翻译对话utterance,我们还要求为每个utterance标注所用的知识三元组。
3.4 数据质量评估
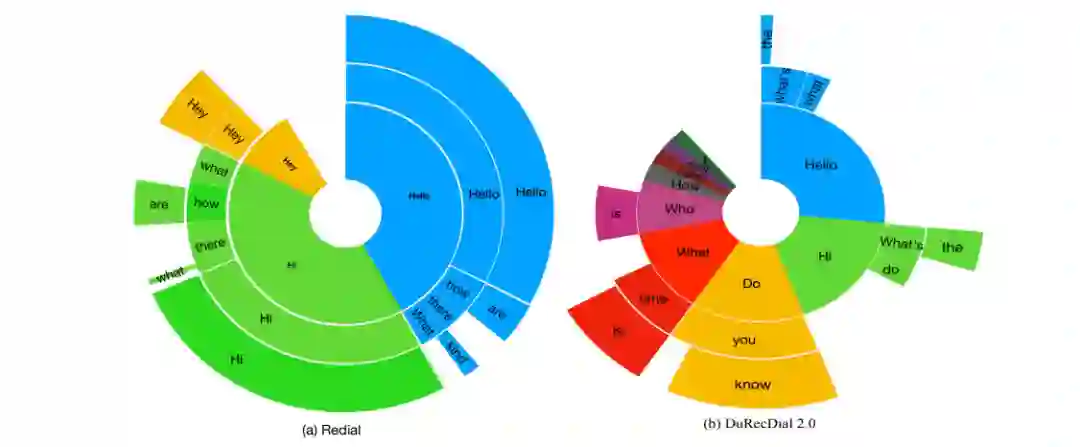
数据标注完成后,我们进行了人工评估。具体来说,我们随机选取200个对话,让3个数据专员为对话打分,如果一个对话完全遵循任务模板中的要求,并且语法正确、流畅,则该对话将被评为“1”,否则为“0”。最终200个对话的平均得分为0.93,表明数据质量较高。此外,我们还分析了DuRecDial 2.0的语言风格。具体来说,通过与REDIAL[5]对比三元前缀的分布(Distribution of trigram prefixes),验证了DuRecDial 2.0的语言风格更灵活多样。
4. 任务设定
基于DuRecDial 2.0,我们设定了包括单语言、多语言、跨语言在内的5个任务。具体任务设计如下:
表示seeker 和reommender 的一组对话, 其中 是对话的数量, 是 seeker 的数量. 每个对话 (比如 ) 都附带有seeker的profile (表示为 ), 知识图谱 , 对话目标序列, 其中 是一些知识三元组, 是对话类型, 是对话主题(topic). 给定由对话 中的话语 组成的对话上下文 , , 和 , 本任务的目标是生成合适的回复 ,从而完成对话目标 。
4.1 单语言对话推荐:
包括Task 1: ( , , , ) 和 Task 2: ( , , , )。基于这两个任务,可以对比同一个模型在不同语言的差距。在本工作中,我们分开训练这两个任务,然后评估模型在中文和英文上的差异。
4.2 多语言对话推荐:
包括Task 3: ( , , , , , , , )。跟多语言机器翻译和多语言阅读理解类似,我们直接将两种语言的训练数据混合到一个训练集中,并训练一个模型来同时处理英语和汉语对话推荐。此任务可以验证使用其他语言的数据是否可以提高当前语言的模型的性能。
4.3 跨语言对话推荐:
包括Task 4: ( , , , ) 和 Task 5: ( , , , )。在这两个任务上,给定对话目标和知识(如英语),模型将一种语言(如汉语)的对话上下文作为输入,然后输出另一种语言(如英语)的回复。理解混合语言对话上下文是端到端对话系统需要的技能,此任务设置有助于评估模型是否有能力执行此类跨语言任务。
5. 实验
5.1 实验设定
数据集: DuRecDial 2.0
评估: 自动评估和人工评估,具体评估指标如图4所示。
 图4 评估指
标
图4 评估指
标
5.2 基线模型
本工作涉及到中文和英文单语言对话推荐、多语言对话推荐和跨语言对话推荐,所以模型需要具备处理多语言的能力。基于此,我们基于两个有影响力的多语言预训练模型XNLG和mBART,在DuRecDial 2.0构建了单语言对话推荐、多语言对话推荐和跨语言对话推荐的基线模型。
XNLG 是一个跨语言预训练模型,其跨语言共享相同的序列到序列模型。在预训练时,通过自动编码和自回归任务更新编码器和解码器的参数。微调时,当目标语言与训练数据的语言相同时,我们对编码器和解码器的参数进行微调;当目标语言与训练数据语言不同时,我们只对编码器的参数进行微调。微调编码器的目标是最小化:

其中
和
均跟原始XNLG模型保持一致,
表示双语平行数据,
表示单语数据。
微调解码器的目标是最小化:

其中 和 跟原始XNLG模型保持一致。
mBART 是一个基于CC25数据训练的多语言序列到序列(Seq2Seq)去噪自动编码预训练模型。它支持在CC25中的任何语言对(包括英语和汉语)之间进行微调。使用mBART初始化模型,可以提升很多单语/多语/跨语任务的性能。我们将5个任务均建模为机器翻译任务。具体来说,我们把对话上下文、对话所用的背景知识和对话目标拼接起来作为源语言输入,这个源语言输入可以是单语言、多语言或跨语言文本,然后生成目标语言的回复。由于生成的回复可以是不同的语言,因此我们还需要将回复的语言标识符拼接到源语言输入。具体地说,如果需要生成的回复是英文的,则标识符为EN,否则为ZH,无论源输入是哪种语言。最后,我们分别在5个任务上对mBART模型进行了微调。
5.3 实验结果
我们在上述五个任务上,评估了XNLG和mBART的效果,实验结果如表1和表2所示。
表1 自动评估结果

表2 人工评估结果
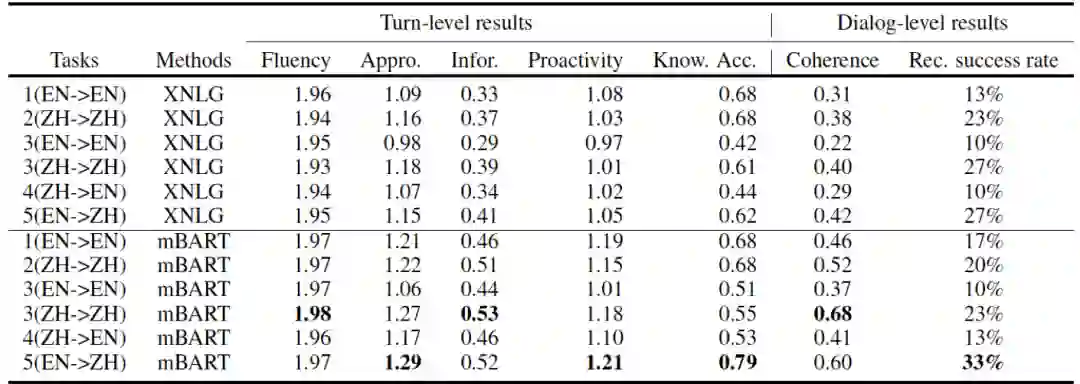
English vs. Chinese: 如表1和表2所示, 在汉语相关任务(任务2、3(ZH)和5)上,除了F1和DIST1/DIST2,在几乎所有指标上都优于英语相关任务(任务1、3(EN)和4)。可能的原因是:英文数据的实体名是基于中文实体翻译的,这与XNLG和mBART使用的英语预训练语料库中的实体集有很大不同,导致预训练模型无法很好地建模这些实体,所以回答中出现知识错误较多(例如,可能在回答中提到与当前主题无关的错误实体),而回复中实体的准确性对 Knowledge P/R/F1、LS、UTC、Know.Acc.、Coherence和Rec.success rate的影响很大。
Monolingual vs. Multilingual: 基于表1和表2的结果可知,在任务3(ZH)上,除了DISTINCT和Knowledge accurity,几乎所有指标都优于任务2。这表明,使用双语语料库可以略微提高汉语对话推荐模型的性能。可能的原因是,使用额外的英语数据隐式地扩大了汉语相关任务的训练数据量,从而增强了为给定对话上下文生成正确实体的能力,从而提高模型性能。但任务3(EN),几乎所有指标都不如任务1。可能的原因是预训练模型不能很好地对对话话语中的实体进行建模,导致模型性能较差。
Monolingual vs. Cross-lingual: 如表1和表2所示, 任务5明显好过任务2,这表明使用英文数据当上下文,能明显提高英文对话推荐的性能。一个可能的原因是XNLG和mBART可以充分利用双语数据集,从而提高生成正确实体的能力。此外,我们注意到,跨语言设定比多语言设定的效果更好,这一结果的原因将在未来的工作中进行研究。但是,在任务4上,模型效果并不如任务1,这与多语言设置的实验结果一致。
XNLG vs. mBART: 根据表1和表2的评估结果, mBART几乎在所有任务的所有指标都超过XNLG。可能的原因是mBART所用的参数和训练数据都比XNLG多。
6. 结论
为促进多语言和跨语言对话推荐的研究,我们构建第一个中英双语并行对话推荐数据集DuRecDial 2.0,并定义了5个任务。然后,我们基于XNLG和mBART构建了单语、多语和跨语言对话推荐的基线模型。自动评估和人工评估结果表明,使用英文对话推荐数据可以提高中文对话推荐的性能。
参考文献
[1] Zeming Liu, Haifeng Wang, Zheng-Yu Niu, Hua Wu, Wanxiang Che, Ting Liu. 2020. Towards Conversational Recommendation over Multi-Type Dialogs. In ACL.
[2] Zeming Liu, Ding Zhou, Hao Liu, Haifeng Wang, Zheng-Yu Niu, Hua Wu, Wanxiang Che, Ting Liu, Hui Xiong. Graph-Grounded Goal Planning for Conversational Recommendation. In TKDE.
[3] Yinhan Liu, Jiatao Gu, Naman Goyal, X. Li, Sergey Edunov, Marjan Ghazvininejad, M. Lewis, and Luke Zettlemoyer. 2020. Multilingual denoising pretraining for neural machine translation. In TACL.
[4] Zewen Chi, Li Dong, Furu Wei, Wenhui Wang, XianLing Mao, and He yan Huang. 2020. Cross-lingual natural language generation via pre-training. ArXiv, abs/1909.10481.
[5] Raymond Li, Samira Ebrahimi Kahou, Hannes Schulz, Vincent Michalski, Laurent Charlin, and Chris Pal. 2018. Towards deep conversational recommendations. In NIPS.
本期责任编辑:丁 效
理解语言,认知社会
以中文技术,助民族复兴



