赛尔原创@ACL 2021 | 基于一致性正则的跨语言微调方法
论文名称:Consistency Regularization for Cross-Lingual Fine-Tuning 论文作者:郑博,董力,黄绍晗,王文辉,迟泽闻,Saksham Singhal,车万翔,刘挺,宋夏,韦福如 原创作者:郑博 论文链接:https://arxiv.org/abs/2106.08226 代码链接:https://github.com/bozheng-hit/xTune 转载须标注出处:哈工大SCIR
1 简介
1.1 研究背景
预训练跨语言模型(Pre-Trained Cross-Lingual Language Model)是通过在大规模多语言语料上进行预训练得到,其展现了在不同语言间优秀的迁移能力。跨语言微调(Cross-Lingual Fine-Tuning)指通过在一种语言的任务标注数据上微调预训练跨语言语言模型,使得该任务的监督信号可以泛化到其他目标语言上。这种泛化能力减少了特定场景下所需人工标注数据的花费,尤其是对于标注成本高昂的低资源语言而言。
1.2 研究动机
前人的一些工作已经证明了在跨语言微调阶段引入数据增广(Data Augmentation)是一种可以有效提升跨语言迁移能力的方法。例如,[1]将源语言训练数据翻译到其他目标语言,[2]通过使用语码转换(Code-Switch)策略,随机替换源语言句子中的词到目标语言,这两种方法都是将增广数据当做额外的训练数据使用,并且取得了一定的效果提升。然而,这些工作并没有考虑到原训练样本与以其生成的增广样本之间的内在联系。直观地说,对于不改变语义的增广策略,原始样本的预测结果应该与其生成的增广样本相似,如在分类任务中,一个英语句子的预测分布和它的翻译应保持一致。
1.3 本文贡献
本文贡献总结如下:
-
提出跨语言微调方法xTune,基于两种一致性正则来更好的利用数据增广提升跨语言微调性能。
-
针对跨语言微调尝试四种不同类型的数据增广方法,分别为子词采样(Subword Sampling)、高斯噪声(Gaussian Noise)、语码转换(Code-Switch)以及机器翻译(Machine Translation)。
-
针对三种不同跨语言自然语言理解任务,分别给出应用xTune的方案,即如何根据任务特性选择两种一致性正则方法中所使用的数据增广策略。
-
通过大量实验表明xTune可以显著地提升跨语言微调的性能。
2 方法
2.1 xTune:基于一致性正则的跨语言微调方法
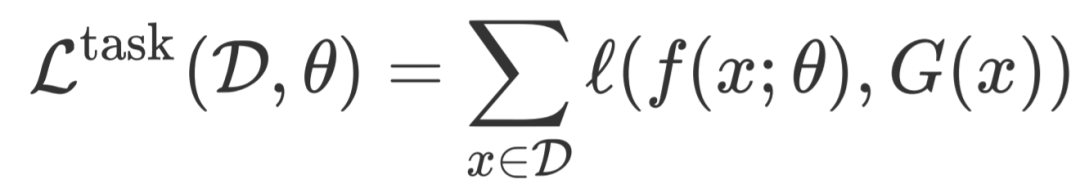
公式中, 表示样本 的真实标签, 是任务相关的损失函数。
除了仅在源语言训练数据上微调之外,近期工作也表明了使用增广数据对提升目标语言性能有帮助,如将翻译样本加入训练集以增强跨语言迁移能力。使 为一种跨语言数据增广策略(如语码转换),为增广后的训练语料,那么其微调的损失函数为 。注意,对于细粒度任务,某些增广策略得到的数据无法直接用于微调训练。例如,在词性标注中,由于缺乏显式对齐,源语言样本的标签不能映射到翻译样本。
2.1.1 样本一致性正则(Example Consistency Regularization)
为了鼓励任一样本与其等同语义的增广样本产生一致的预测分布,本文首先引入样本一致性正则,定义如下:
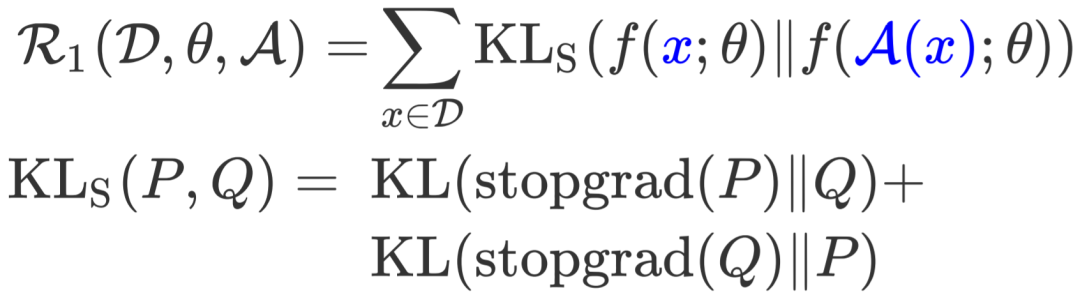
其中 为对称KL散度(Symmertrical Kullback-Leibler Divergence),因此正则鼓励两个预测分布 和 相互一致。 操作用于截断回传梯度,这项操作也在[3] [4]中被使用。在实验部分会有消融实验表明该操作可以提升最终微调效果。
2.1.2 模型一致性正则(Model Consistency Regularization)
上一小节中的样本一致性正则在样本级别约束模型训练,本文进一步提出模型一致性正则在语料级别约束模型训练。模型一致性正则分为两个阶段执行:首先,第一阶段在语料 上微调得到模型参数 :
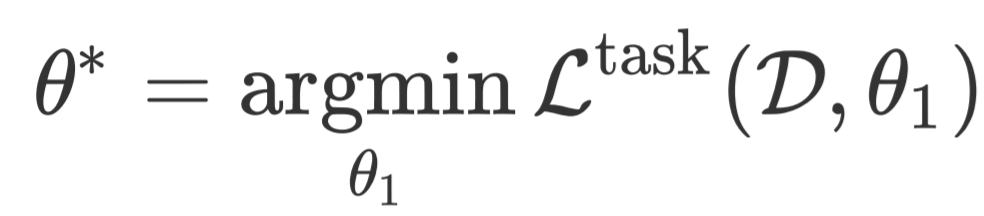
在第二阶段,我们保持模型参数 不变,模型一致性正则的损失函数定义如下:

上式中 是增广过的训练语料, 为KL散度。对于 中的每一个样本 ,模型一致性正则鼓励预测分布 与 一致,该正则项加强了两个模型学习到的分布之间的语料级一致性。
2.1.3 xTune跨语言微调方法
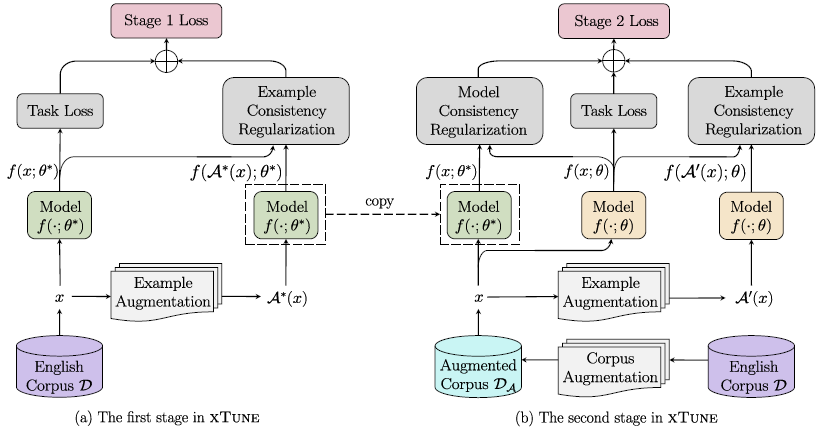
如图1所示,本文结合上述两个正则方法得到两阶段跨语言微调方法xTune。首先,在第一阶段使用样本一致性正则 微调模型:
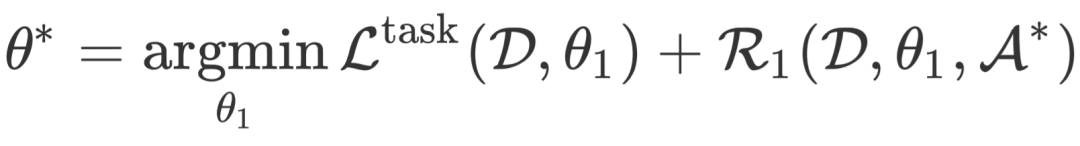
将得到的模型参数 用于第二阶段中的模型一致性正则 ,并保持 不变。最终的损失函数如下:
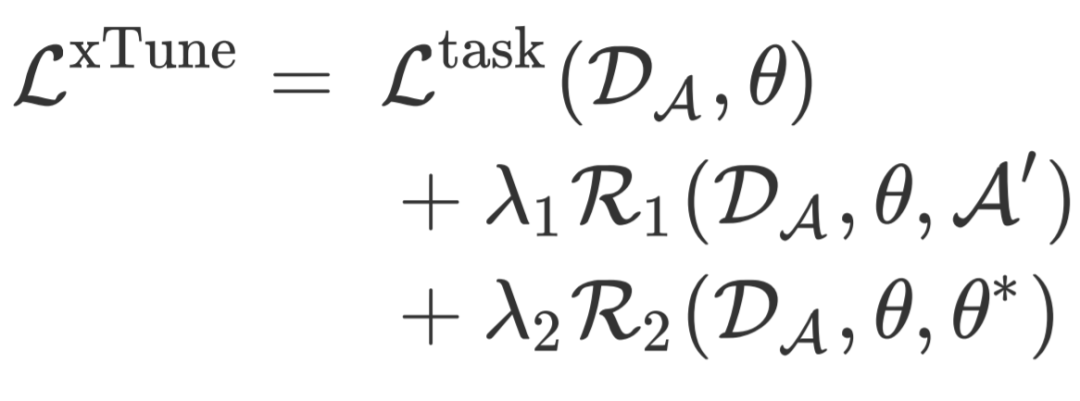
和 为两个正则化方法对应的权重。注意数据增广策略 、 、以及 可以不同或相同,本文将其视为在实验阶段可调整的超参数。
2.2 数据增广方法
为了研究不同数据增广方法对跨语言迁移能力的影响,本文一共尝试使用四种不同的数据增广方法(如何为xTune中两个一致性正则选择数据增广方法请参考原文附录):
-
子词采样:本文所使用的预训练模型XLM-R采用SentencePiece中的unigram language model进行子词切分操作,本文通过其自带的动态子词采样算法,将生成的多个子词序列作为增广数据。 -
高斯噪声:通过将高斯噪声加在模型的Embedding层的输出上作为额外的增广数据。 -
语码转换:我们在双语词典中随机选取源语言原文中的词,并将其替换为目标语词,从而获得语码转换数据。直观地看,这种类型的数据增强明确地帮助预训练跨语言模型通过替换的锚点对齐多语言向量空间。 -
机器翻译:将源语言数据翻译到目标语言作为增广数据。然而对于细粒度的任务来说,翻译数据的真实标签通常难以获取,比如序列标注任务中无法得到翻译数据的标签,这也导致了不能直接将这些数据当做额外的训练数据使用。在这种情况下,本文提出的模型一致性正则不仅仅可以作为正则使用,而且可以激活在这些未标注数据上的半监督学习(Semi-Supervised Training)。
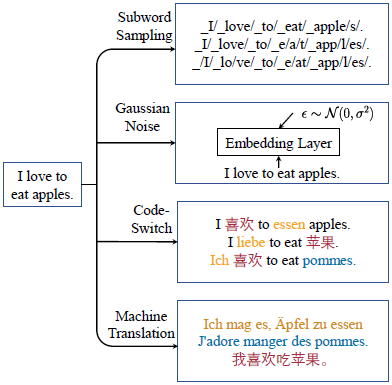
图2 本文中使用的四种数据增广方法
2.3 如何将xTune应用到不同下游任务中
本节将给出如何应用xTune到下游任务中,以分类,片段抽取以及序列标注为例。由于模型一致性正则的使用不受数据增广策略的影响(因为模型预测的概率分布总是可以对齐),本节主要针对样本一致性正则给出方案。
2.3.1 分类(Classification)
对于分类任务,模型对于每一个样本应根据标签种类 输出一个概率分布 。由于不同数据增广策略的不影响模型输出概率分布的对齐(即两个分布中的概率值可以一一对应),所以分类任务中对于本文中的四种数据增广策略都可以直接应用样本一致性正则。
2.3.2 片段抽取(Span Extraction)
对于片段抽取任务,模型对于每一样本应根据切分文本后的子词序列长度 输出两个概率分布 ,分别代表答案片段的开始和结束位置的概率。由于高斯噪声不影响切分序列的结果,所以不影响样本一致性正则的使用。而子词采样以及语码转换会改变 ,所以我们控制改变切分方式的词的比例,仅在未修改位置使用样本一致性正则。我们不使用机器翻译作为该任务中样本一致性正则的数据增广策略,因为对于片段抽取任务,原文本和翻译文本的概率分布不能对齐。
2.3.3 序列标注(Sequence Labeling)
由于预训练语言模型生成的表示是子词级别的,对于序列标注任务,模型在每个词切分后的第一个子词位置预测该词标签。因此模型对于每一个样本应输出 个 类别的概率分布。与片段抽取任务不同,子词采样、高斯噪声以及语码转换均不会改变 ,所以这三种数据增广方式不影响样本一致性正则的使用。但对于机器翻译而言,同样没有办法对齐原句子和翻译句子的输出分布,所以对于序列标注,我们也不使用机器翻译作为样本一致性正则中的数据增广策略。
3 实验
3.1 实验设置
3.1.1 数据集
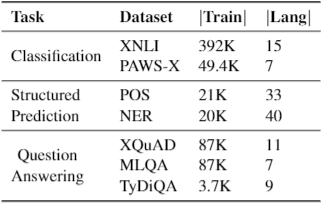
表1 XTREME benchmark中所使用七个数据的统计信息
3.1.2 微调设置
本文考虑跨语言理解任务中的两个典型设置[6]:
(1)Cross-lingual transfer:模型在英语数据上微调,其他目标语言机器翻译数据不可用,直接在不同目标语言上进行测试。
(2)Translate-train-all:可以采用机器翻译作为数据增广策略,模型在英语及其他语言机器翻译上进行微调。由于XTREME官方并没有提供POS和NER的翻译数据,本文使用谷歌翻译得到这两个数据集的翻译文本。
3.2 实验结果
表2 XTREME benchmark上的测试结果
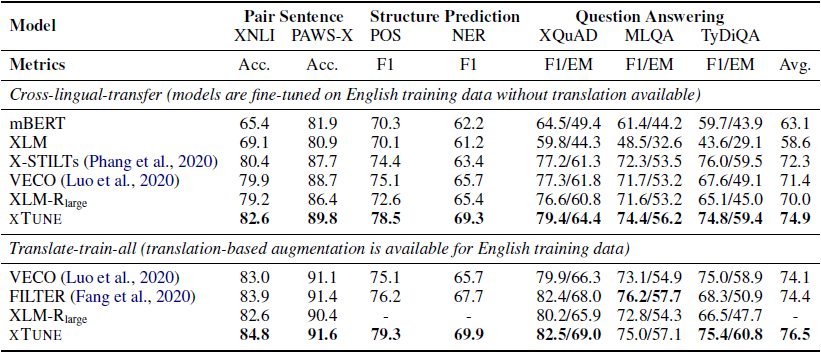
表3 XTREME benchmark上的消融实验结果
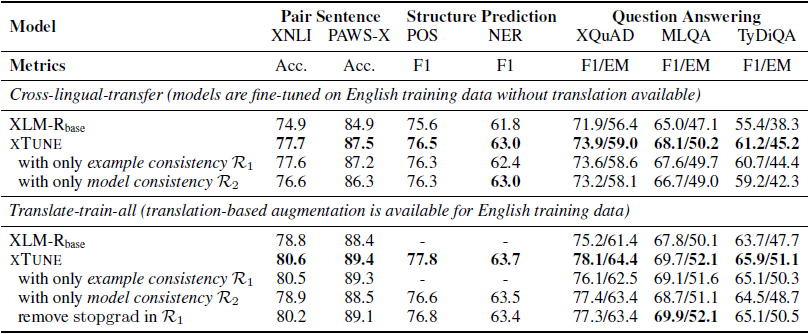
表4 XNLI数据集上每种语言的测试结果
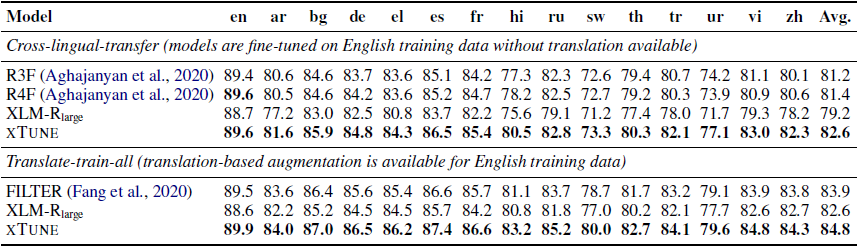
表4给出了XNLI数据集上每种语言的结果。在cross-lingual transfer设置下,xTune对两种正则均使用语码转换作为数据增广策略。语码转换使用MUSE中的双语词典,由于MUSE不提供斯瓦西里语(sw)和乌尔都语(ur)词典,我们使用除了这两种语言之外的12种目标语言到英语的双语词典。结果表明我们的方法在所有语言上都相比基线有提升,甚至在两种没有双语词典的语言上,这表明即使没有该语言的机器翻译或双语词典,我们的方法仍可以增强到低资源语言的泛化能力。对于translate-train-all设置,我们对两种正则均使用机器翻译作为数据增广策略,我们在 基线的基础上平均提升了2.2个百分点,并且相比之前最好系统FILTER中的结果也有0.9个百分点的提升。
3.3 实验分析
表5 不同数据增广策略在三种下游任务上的比较实验结果,Data Aug.指将增广数据当做额外训练数据进行微调
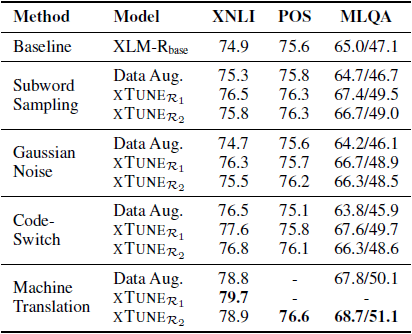
表6 XNLI上微调过后的模型在跨语言检索数据集上的结果


xTune改进了模型对于不同标签的决策边界以及生成语言不变表示的能力。 如图3所示,我们展示了在三种不同设置下来自XNLI开发集的示例的t-SNE可视化。我们观察到用xTune微调的模型显著改善了不同标签的决策边界。此外,对于一个英语示例及其在其他语言中的翻译,与两个基线模型相比,使用xTune进行微调的模型生成了更相似的表示。这个观察结果也与表6中的跨语言检索结果一致。
4 总结
本文提出了一个跨语言微调框架xTune来更好的利用跨语言增广数据,通过两个一致性正则来鼓励模型对任一样本及其同等语义增广样本产生一致的预测输出。本文探索了四种类型的跨语言数据增广策略。实验结果表明,与直接在增广数据上进行微调相比,两种一致性正则分别显著提高了下游任务的性能。同时,模型一致性正则可以在未标记的目标语言翻译上进行半监督训练。xTune结合了两种正则化方法,并且在XTREME benchmark上大幅提升了性能。
5 参考文献
[1] Jasdeep Singh, Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, and Richard Socher. 2019. XLDA: cross-lingual data augmentation for natural language inference and question answering. CoRR, abs/1905.11471.
[2] Libo Qin, Minheng Ni, Yue Zhang, and Wanxiang Che. CoSDA-ML: Multi-lingual code-switching data augmentation for zero-shot cross-lingual NLP. IJCAI 2020.
[3] Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Tuo Zhao. SMART: Robust and efficient fine-tuning for pretrained natural language models through principled regularized optimization. ACL 2020.
[4] Xiaodong Liu, Hao Cheng, Pengcheng He, Weizhu Chen, Yu Wang, Hoifung Poon, and Jianfeng Gao. 2020. Adversarial training for large neural language models. CoRR, abs/2004.08994.
[5] Junjie Hu, Sebastian Ruder, Aditya Siddhant, Graham Neubig, Orhan Firat, and Melvin Johnson. XTREME: A massively multilingual multitask benchmark for evaluating cross-lingual generalisation. ICML 2020.
[6] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzman, Edouard Grave, Myle Ott, Luke Zettle- ´ moyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. ACL 2020.
长按下图即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号『哈工大SCIR』。


