如何缓解非自回归翻译的多峰问题?试试微信AI 的RecoverSAT模型

本文基于ACL 2020论文《Learning to Recover from Multi-Modality Errors for Non-Autoregressive Neural Machine Translation》撰写。
导语
背景

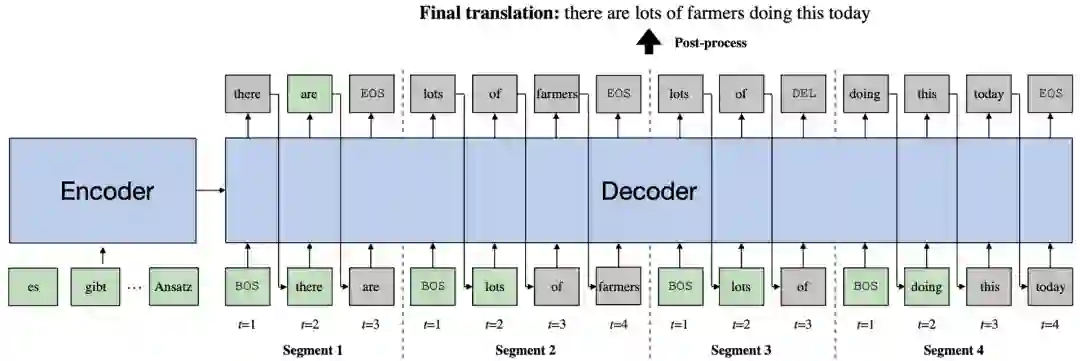
模型结构
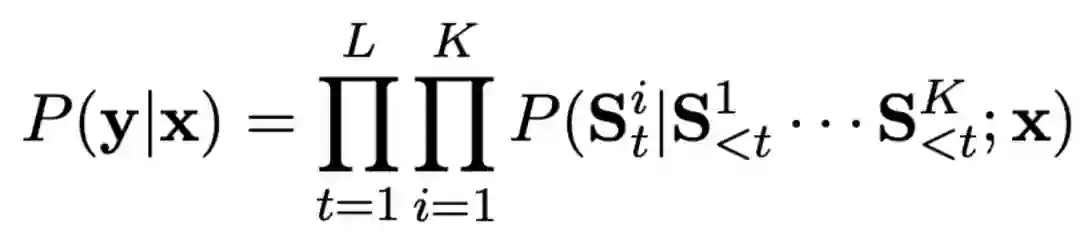
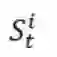 表示第i个片段的第t个词,
表示第i个片段的第t个词,
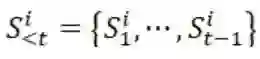 表示第i个片段的历史信息,L表示片段长度,K表示片段数目。
表示第i个片段的历史信息,L表示片段长度,K表示片段数目。
1、对于每个片段,其开头几个词的选择可以更加灵活。以图2为例,对于第2个片段(Segment 2),如果模型将其第一个词选为“of”而不是“lots”,那么模型只需在第1个片段(Segment 1)的结尾处多生成出词“lots”即可避免漏译错误。同理,如果第2个片段的第1个词被选择为“are”,那么第1个片段只需不生成“are”即可避免重复翻译错误。
2、如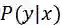
实验效果
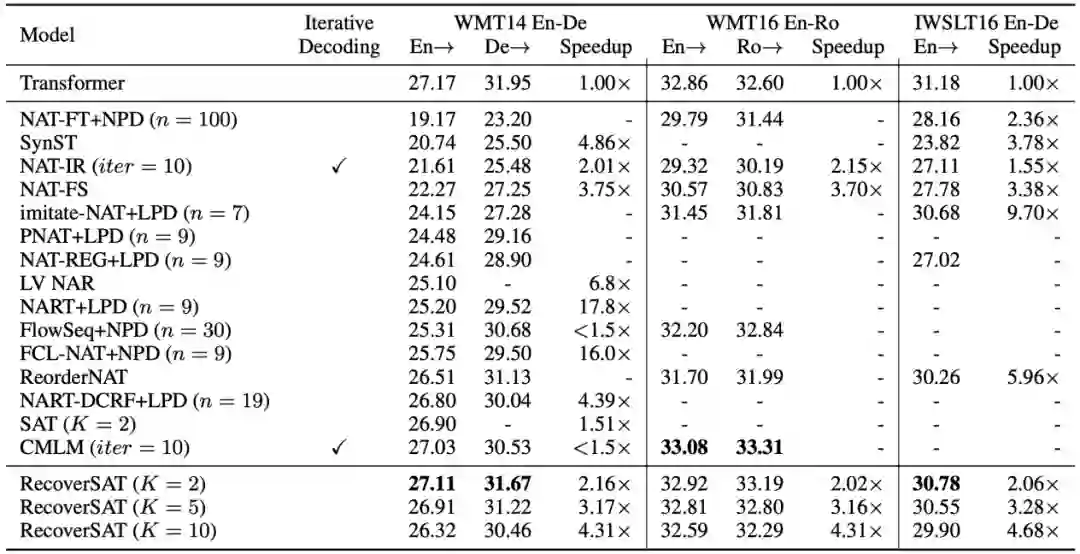

结语
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月15日





相关VIP内容
相关资讯