命名实体识别新SOTA:改进Transformer模型

编辑 | 唐里
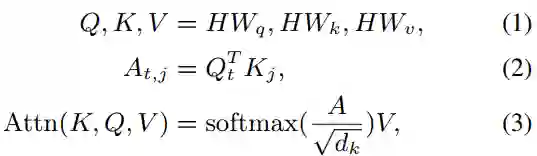
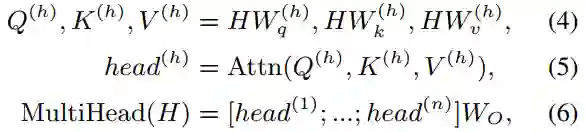

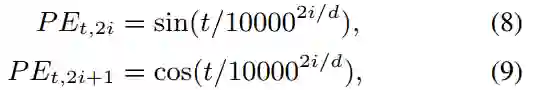
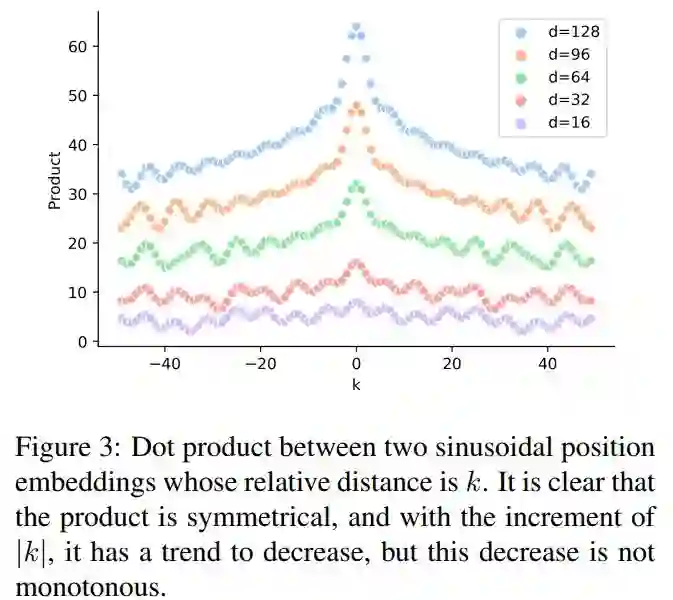
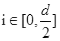 。根据公式,分别计算位置向量中奇数维度和偶数维度的值。
论文指出,根据公式(8)(9)得到的位置向量仅仅带有相对位置信息,而不包括方向信息,证明如下:
。根据公式,分别计算位置向量中奇数维度和偶数维度的值。
论文指出,根据公式(8)(9)得到的位置向量仅仅带有相对位置信息,而不包括方向信息,证明如下:
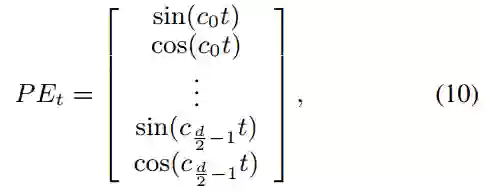
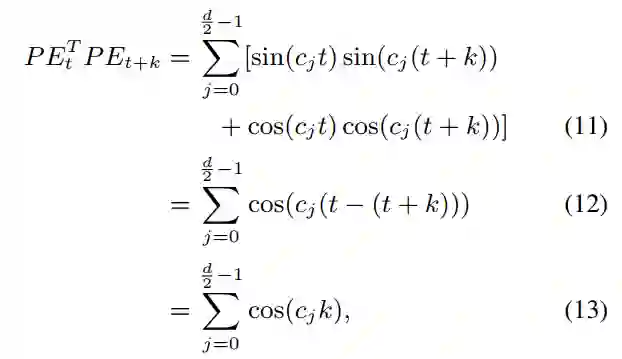
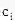 是一个常量
是一个常量
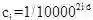 ;公式(11)到公式(12)由公式
;公式(11)到公式(12)由公式
 得到。由公式(13)可知,第t个位置的位置向
得到。由公式(13)可知,第t个位置的位置向
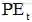 与第t+k个位置的位置向量
与第t+k个位置的位置向量
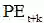 相乘,得到的结果只与相对位置k有关。并且,令
相乘,得到的结果只与相对位置k有关。并且,令
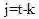 ,可得:
,可得:

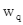 ,
,
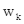 将H(位置向量和词向量的组合)转化到相应的空间。实际上,两个位置向量
,
进行的运算为
将H(位置向量和词向量的组合)转化到相应的空间。实际上,两个位置向量
,
进行的运算为
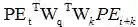 (
(
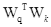 被看成一个矩阵,可得
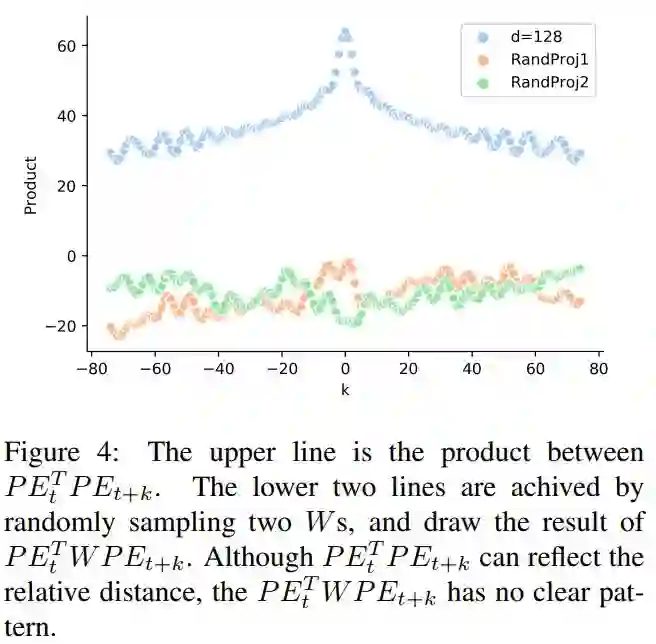
被看成一个矩阵,可得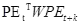 )。随机采样得到两个W,绘出结果图,如fingure4所示,在没有进行矩阵转换时,位置向量可以捕获相对位置信息,经过矩阵转换后,即进行self-attention时,相对位置信息被破坏。
)。随机采样得到两个W,绘出结果图,如fingure4所示,在没有进行矩阵转换时,位置向量可以捕获相对位置信息,经过矩阵转换后,即进行self-attention时,相对位置信息被破坏。
 映射的;t是目标token的索引,j是上下文token的索引,公式(17)在进行位置编码时,引入了相对位置以及方向信息,距离为t(j=0)与距离为-t(j=2t)的两个位置的位置向量在奇数维度上是不同的,偶数维度上是相同的,如公式(20)所示。公式(18)在计算attention权值时,将词向量与位置向量分开计算(位置对NER任务来说时及其重要的),并且加了偏置项。公式(19)相比公式(3)去掉了
映射的;t是目标token的索引,j是上下文token的索引,公式(17)在进行位置编码时,引入了相对位置以及方向信息,距离为t(j=0)与距离为-t(j=2t)的两个位置的位置向量在奇数维度上是不同的,偶数维度上是相同的,如公式(20)所示。公式(18)在计算attention权值时,将词向量与位置向量分开计算(位置对NER任务来说时及其重要的),并且加了偏置项。公式(19)相比公式(3)去掉了
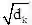 。
。
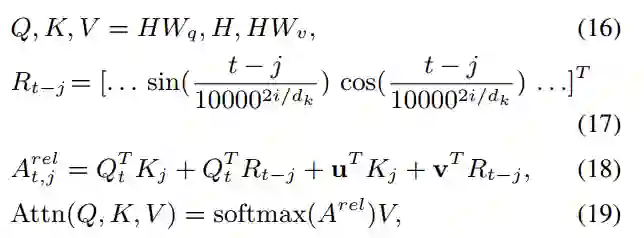
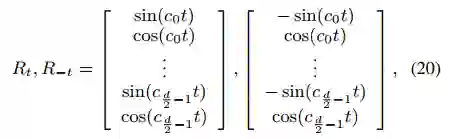 映射的,所以K的维度是和词向量维度一样为d,是无法与
映射的,所以K的维度是和词向量维度一样为d,是无法与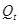 (维度为
(维度为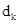 )进行矩阵相乘的运算的。论文作者也表示,这里存在一些笔误,想要表达的意思是,计算每一个attention head从K(也就是H)依次选取0到
)进行矩阵相乘的运算的。论文作者也表示,这里存在一些笔误,想要表达的意思是,计算每一个attention head从K(也就是H)依次选取0到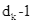 维度, 到
维度, 到
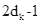 维度,依此类推。
维度,依此类推。
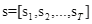 ,以及标注
,以及标注
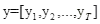 。
。
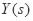 代表所有可能的标注序列。标注y的概率计算如下公式:
代表所有可能的标注序列。标注y的概率计算如下公式:
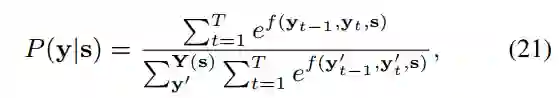
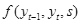 计算从标注
计算从标注
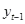 到标注
到标注
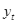 的转移分数以及的分数,优化的目标是最大化
的转移分数以及的分数,优化的目标是最大化
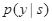 。解码时,使用维特比算法,选择概率最大的y。
。解码时,使用维特比算法,选择概率最大的y。
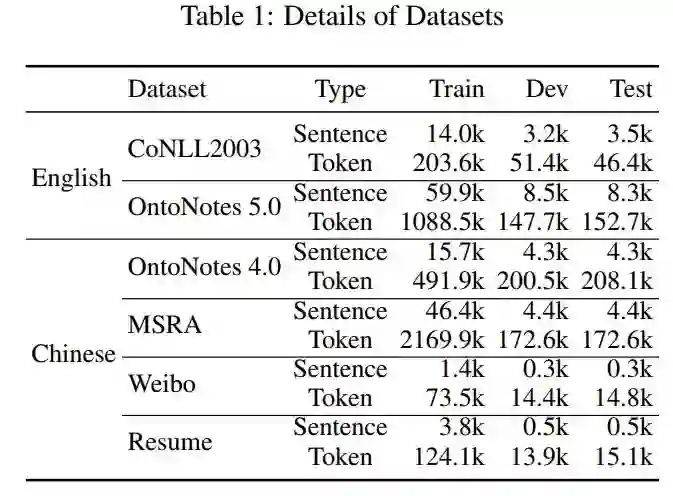
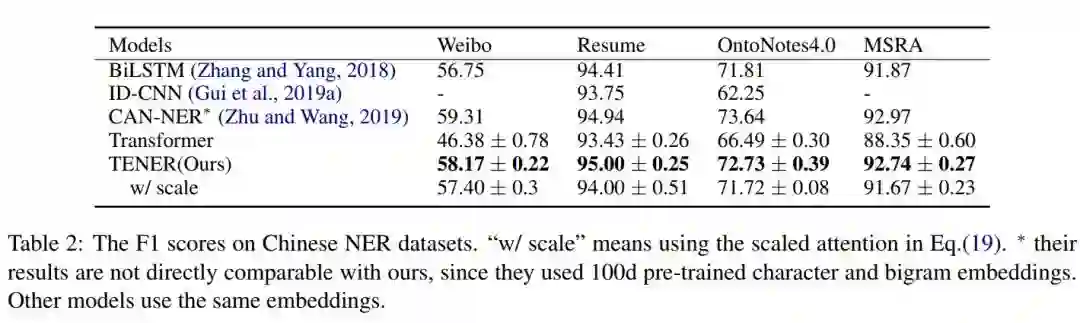
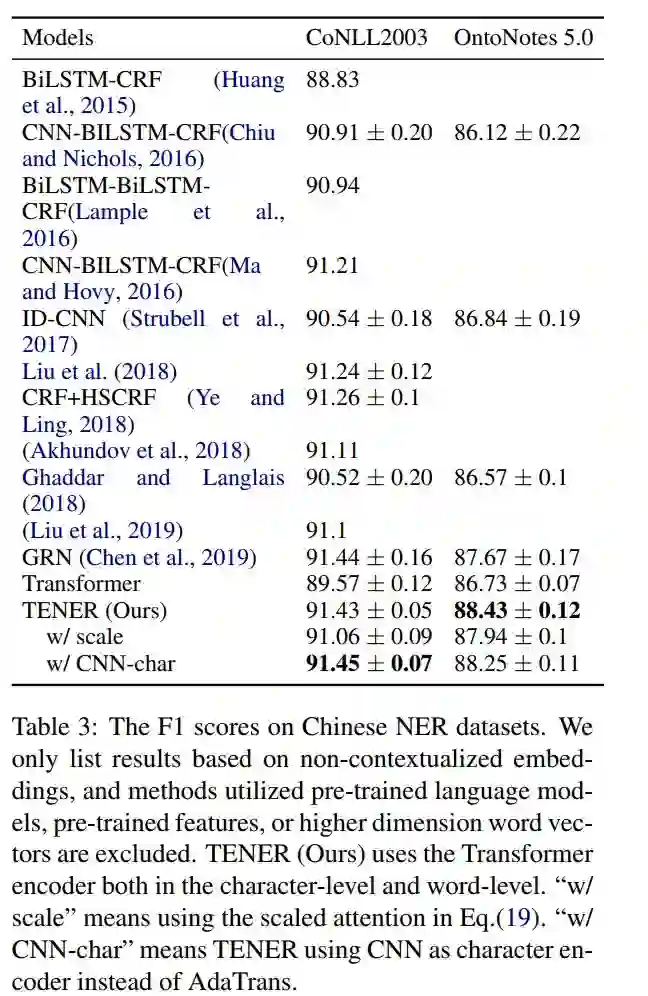
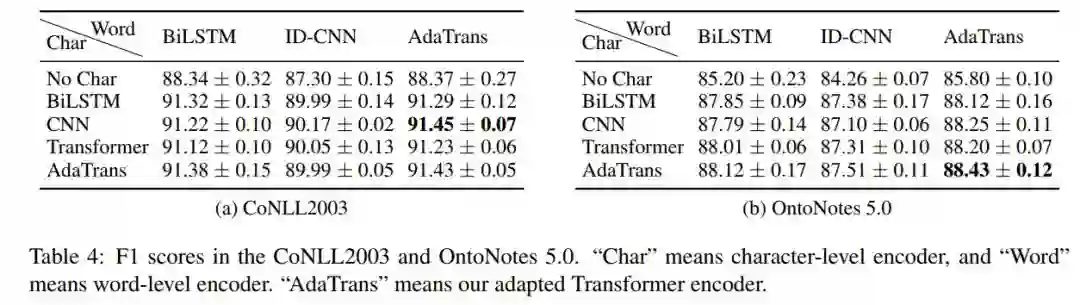
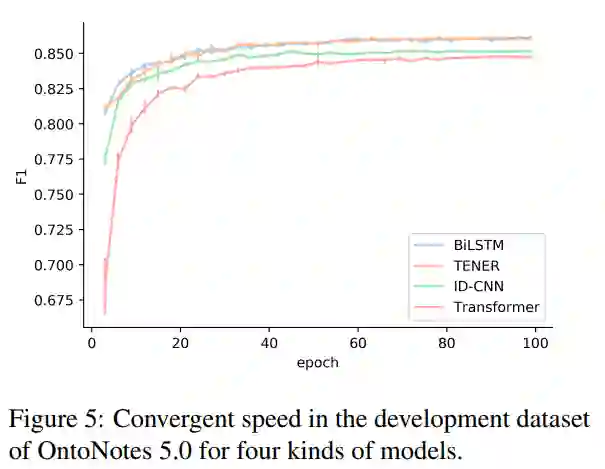


 点击“阅读原文”查看 Github项目推荐 | 命名实体识别或文本分类模型生成数据集!
点击“阅读原文”查看 Github项目推荐 | 命名实体识别或文本分类模型生成数据集!
登录查看更多
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
专知会员服务
52+阅读 · 2019年12月28日




相关VIP内容
专知会员服务
52+阅读 · 2019年12月28日
相关资讯
相关论文