BERT不是“银弹”,它做不到什么?

论文作者| Allyson Ettinger Department of Linguistics University of Chicago
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
基于语言目标建模的预训练的 NLP 模型最近非常流行,甚至已经成为特定任务微调的先驱。预训练模型如 BERT(Devlin et al,2019)和 ELMo(Peters et al,2018a),在各项任务中表现出最佳性能,表明这些预训练的模型在训练过程中获得了有价值的、可泛化的语言能力。然而,尽管我们已经知道预训练语言模型的益处,我们却没有真正了解这些模型在训练过程中是如何学习的。
本文旨在通过引入一套针对人类心理语言学实验中一系列语言能力的诊断方法,来提升我们对语言模型(LM)是如何理解语言的了解。由于它们起源于心理语言学,这些诊断有两个明显的优势:它们被精心地控制,通过询问有针对性的问题来了解语言能力;它们被设计成通过上下文检查单词预测能力来回答这些问题,这使得我们可以仅研究语言模型(LM)而无需进行特定任务的微调工作。
除了这些优点之外,我们的诊断方法与现有的 LM 测试方法有两个主要差异。首先,选择这些测试是因为它们能够揭示预测模型中的不敏感性,这一点可以从它们引发人类大脑反应的模式中得到证明。其次,这些测试的目标都是一组语言能力,这些能力扩展到现有的 LM 诊断中所看到的主要句法重点之外——我们有针对常识 / 语用推理、语义角色和事件知识、类别成员和否定的测试。我们的每一个诊断都支持在好坏的上下文环境中单词预测准确性和敏感性的测试。尽管我们将重点放在 BERT 模型,但是这些诊断方法适用于任何语言模型的测试。
本文有两个主要贡献。首先,我们引入了一套新的有针对性的诊断方法来评估语言模型中的语言能力。其次,我们应用这些测试来揭示 BERT 模型的优缺点。我们发现,BERT 在挑战常识 / 语用推理和基于角色的事件预测方面遇到了困难,它通常对类别内的区别和角色逆转很鲁棒,但比人类敏感度低。它在将名词与其上位词关联方面的能力非常强。然而,最引人注目的是,我们发现 BERT 模型对概括性否定的理解完全失败,进而对学习这种意义的能力提出质疑。
我们诊断的能力来源于心理语言学研究,这些项目是为了研究语言处理的特定方面而精心设计的,每项测试都被证明在人类身上测试时能产生模式信息丰富的结果。在本节中,我们将提供有关人类语言处理的相关背景,并解释如何使用这些信息来选择这里使用的特定测试。
为了研究人类的语言处理机制,心理语言学家经常在语境中测试人类对单词的反应,以便更好地理解我们大脑通常如何产生预测信息。以下是两种与本文相关的人类预测反应:
完形填空概率 人类期望的第一个测量指标是“完形填空”任务的反应。在完形填空任务中,被测者将拿到一个不完整的句子,并被要求在空白处填写对应的单词。“完形填空概率”是一个词 w 在上下文 c 中,选择 w 来完成 c 的人们的比例。我们将把它作为上下文中人类预测的最佳可用标准。人们完成完形填空任务通常没有任何时间压力,因此他们有机会使用上下文中的所有可用信息来进行预测。
N400 振幅 人类期望的第二个测量指标是一种叫做 N400 的大脑反应,它是通过测量头皮的电流活动(通过脑电图)来检测的。与完形填空法一样,N400 也可以用来衡量在上下文 c 中对单词 w 的期望程度。N400 响应的振幅似乎对上下文中单词的匹配很敏感,并且在许多情况下与完形填空相关(Kutas 和 Hillyard,1984)。N400 也被证明与概率语言模型相关(Frank 等人,2013)。然而,N400 不同于完形填空,它是一个实时响应,只在处理一个字的 400 毫秒内发生。因此,N400 中反映的期望有时与未定式完形填空反应中反映的更全面的期望不同。
我们在这里使用的测试集都是从人类的研究中得出的,这些研究揭示了完形填空和 N400 之间的差异,也就是说,这些测试中的每一项,N400 的响应表明在计算期望值时,对某些信息的不敏感程度,导致偏离了完全知情的完形预测。我们选择这些作为我们的诊断是因为针对 N400 影响似乎较小的信息类型它们提供内置的敏感度测试方法,并且因为它们可以呈现出特别具有挑战性的预测任务,从而使无法使用全部可用信息的模型陷入困境。
我们的每个诊断都支持三种类型的测试:单词预测准确度、敏感性测试和定性预测分析。由于这些项目旨在得出有关人类处理的结论,因此每个组都经过精心构造,以约束与进行单词预测相关的信息。这允许我们检查 LM 是如何使用这些目标信息的。
对于单词预测的准确性,我们使用人类完形概率中最期望的项作为最佳的完成。这个表明模型在为目标单词生成概率时,如果能够访问和利用所有相关上下文信息时,就应该能够做出更佳的预测。
对于敏感性测试,我们比较了模型概率的好与坏完成。特别是在比较 N400 在人类实验中表现出较低的敏感性。这使我们能够测试 LM 是否会在相关的语言差异方面表现出类似的不敏感性。最后,由于这些项目是以这样一种可控的方式构建的,因此,对模型的 top N 的预测进行定性分析可以提供有关用于预测信息的高度相关信息。我们在下面的实验中利用了这一点。
在所有测试中,要预测的目标词落在所提供上下文的最后位置,这意味着这些测试对于从左到右或者双向 LM 应具有类似的功能。为了测试 BERT 模型,并便于与当前结果进行公平的比较,我们筛选出单词不在 BERT 单词词汇表中的项目,以确保可以预测所有期望单词。
这一点非常重要,要承认这些是小测试集,因为它们起源于心理语言学研究。然而,由于这些集合是由认知科学家手工设计的,用于测试人类的预测处理,因此它们的价值在于它们提供的关于 LM 在预测中使用的信息的有针对性的评估。
我们的第一个数据集是针对常识和语用推理,并测试对语义范畴差异的敏感性。表 1 的左栏显示了这些项目的示例,每个项目由两个句子组成。这些项目来自 Federmeier 和 Kutas(1999) 的一项有影响力的人类研究,该研究测试了大脑对不同类型的上下文完成的反应,如表 1 右栏目所示。

预测所需信息 对这一集合的准确预测需要使用常识来推断第一句中所描述的内容,并使用语言推理来确定与第二句的关系。例如,在表 1 中,常识告诉我们,吻留下的红色表示唇膏,而语用推理告诉我们 stop wearing 与 complained 有关。就像 LAMBADA 一样,最后一句是通用性的,不支持自己的预测。与 LAMBADA 不同,这些项的一致结构允许我们以特定的模型功能为目标,此外,这些项中没有一项包含上下文中的目标词,这迫使模型使用常识性推理而不是引用。人类完形填空概率表明,对这些项适当的完成展示出很高的一致性。期望完成的平均完形概率为 0.74。
敏感性测试Federmeier 和 Kutas(1999) 研究发现,尽管不适当的完成(例如,睫毛膏、手镯)的完形概率几乎为零(平均完形填空,分别为 0.004 和 0.001),但 N400 显示了对完成的一些期望,这些期望与期望完成共享一个语义类别。我们的敏感性测试针对这一区别,测试 LM 是否支持基于共享语义类别的不适当的完成,以及预期的完成。
数据 原始研究的作者提供了 40 个 item,我们筛选出 6 个项目来容纳 BERT 的单词词汇,最后一组 34 个 item。
我们的第二个数据集目标是事件知识和语义角色解释,并测试角色反转影响的敏感性。表 2 显示了这个集合中的一个示例。这些项目来自 Chow 等人的人类实验,测试了大脑对角色逆转的敏感性。
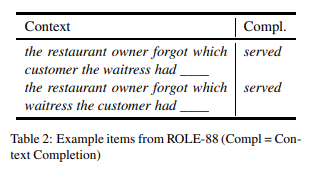
所需信息的预测 对这个集合的预测需要一个模型来解释句子语法中的语义角色,并应用事件知识来了解给定角色中实体类型之间的典型交互。该集合对每个名词对都有倒转(如表 2 所示),因此模型必须区分每个顺序的角色。
灵敏度试验Chow 等人研究发现,尽管每次完成(如,served)仅对顺序的名词有益,而不是反转的,但 N400 显示出对目标完成的预期水平相似,而不管名词顺序如何。我们的敏感性测试针对这一区别,测试 LM 是否会显示出类似的困难,根据词序和语义角色来区分适当的延续。人类完形填空的概率对角色反转表现出强烈的敏感性,对于给定的完成结果,好坏上下文完形之间的平均差异为 0.233。
数据 作者提供了 120 个句子(60 对),我们最后过滤了 88 个 item,删除那些在任何一个上下文的最佳完成都不在 BERT 的单词词汇表 item 对。
我们的第三数据集的目标是理解否定的含义,以及类别成员的知识。表 3 给出了这些测试项目的例子,这些测试项目涉及简单句子否定的缺失或存在,根据否定的不同,有两种不同的完成形式,其真实性也有所不同。这些测试项目来自 Fischler 等人的人类研究,研究了人的期望是如何随着否定的增加而变化的。

所需信息的预测 因为这些项目中的否定上下文是高度不受约束的(A robin is not a _?),因此预测准确度不是衡量否定上下文的有用指标。我们只测试肯定上下文的预测准确性,这使我们能够测试模型对上位词信息的使用(robin=bird)。目标否定出现在敏感性试验中。
灵敏度试验Fischler 等人研究发现,虽然 N400 在肯定句(例如,A robin is a bird)中显示出对肯定完成的偏好,但它不能够适应于否定,而是倾向于否定句(例如,A robin is not a bird)中的否定延续。我们的敏感性测试针对这一区别,测试 LM 是否对否定影响表现出类似的不敏感性。请注意,与前面的部分内容不同,这里我们使用真实性判断而不是完形概率来表示完成的质量。
数据Fischler 等人提供他们在句子中使用的 18 个主语名词和 9 个类别名词的列表,我们使用这些名词生成一个可比较的数据集,共 72 项。我们将这 72 个简单句子称为 NEG-88-SIMP。所有目标词都在 BERT 单字词汇表中。
补充项目 在随后的研究中,Nieuwland 和 Kuperberg 依据 Fischler 等人的实验,创造肯定句和否定句,选择更“natural ... for somebody to say ”,并将这些句子与肯定句和否定句进行对比,选择不那么自然。“Natural”项目包含大多数案例这样的案例,像 Most smokers find that quitting is (not) very (difficult/easy)。而设计为不太自然的案例,像 Vitamins and proteins are (not) very (good/bad)。作者分享 16 个项目,我们将其添加到上面 72 个项目中进行进一步比较。我们将这些旨在测试自然效果的补充 16 项称为 NEG-88-NAT。
作为一个研究案例,我们使用三种诊断方法来检测预训练模型 BERT 的预测能力,它在各项 NLP 任务中都表现出优异的性能。BERT 是一个深度双向 transformer 网络,在掩码语言模型和下一句预测任务中训练得到。我们测试了两个版本的预训练模型:BERT(BASE) 和 BERT(LARGE)。这些版本具有相同的基础架构,但是参数量不同,BERT(BASE) 有 110M 的参数,BERT(LARGE) 有 340M 的参数。我们使用 PyTorch 来实现 BERT 训练。
为了测试,我们使用 [MASK] 标记来处理句子上下文。然后,我们测量 BERT 对这个 [MASK] 标记位置的预测。在 Goldberg 之后,我们还在每个句子的开头添加一个 [CLS] 标记,以模拟 BERT 的训练条件。
BERT 不同于传统的从左到右的语言模型,也不同于人类的实时预测,它是一个双向模型,能够同时使用来自左和右上下文的信息。这种差异会被我们的 item 在左上下文中提供所有信息的事实所抵消,然而,在我们这里的实验中,我们确实为 BERT 的双向性提供了一个优势:我们在每个 [MASK] 标记后包含一个句子和一个 [SEP] 标记,以指示目标位置后面是句尾。我们这样做是为了给 BERT 最可能的成功机会,最大限度地预测一个词而不是一个短语的开头。这些实验的中出现的项目类似如下格式:
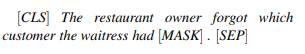
语言模型经过 softmax 转换后生成目标位置的 logit,是为了获得与这些目标位置的人类完形概率值相当的概率值。
首先,我们报告 BERT 在针对常识、语用推理和语义类别敏感度的 CPRAG-34 测试中的结果。
词预测精确度 我们将精确度定义为“期望”完成在 top k 预测中 item 所占的比例,这里 k=1 和 k=5。
表 4(“Orig”)显示了 BERT(BASE) 和 BERT(LARGE) 的精确度。对于 k=1 的精确度,BERT(BASE) 在略超过三分之一的 item 上预测时,准确度明显优于 BERT(LARGE)。当我们扩展到 k=5 时,模型收敛于相同的精度,大约一半的 item 识别出期望的结果。
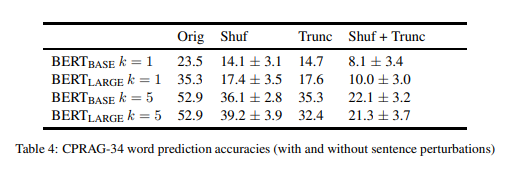
因为常识和语用推理是不常用的概念,所以值得探索 BERT 能在多大程度上基于简单的线索(如单词恒等式或 n-gram 上下文)实现这种性能。为了测试词序的重要性,我们对每个 item 的第一句中的单词进行无序排列,使信息混乱,但保留了所有单个单词的完整性(表 4 中的“shuf”)。
为了测试截断上下文的充分性,我们删除了第二句中的所有单词,但目标单词(“trunc”)前面的两个单词除外。这通常提供足够的句法上下文来识别词性部分,以及一些语义类别的含义,但是要从第二句中删除了其他信息。我们还同时测试了两种扰动(“Shuf+Trunc”)。因为不同的无序排列会产生不同的结果,对于“Shuf”和“Shuf+Trunc”设置,我们展示了 100 次运行的均值和标准偏差。
表 4 显示了这些干扰造成的精确度。有一点很明显,BERT 模型确实利用了第一句的词序和第二句较远的内容所提供的信息,因为每一个单独的干扰都会导致准确性显著下降。然而,值得注意的是,每个扰动都有一个子集,BERT 的精度保持不变。不出所料,其中许多项目都包含与目标相关的特别独特的词语,例如,checkmate(国际象棋)、touchdown(足球) 和 stone-washed(牛仔裤)。这表明 BERT 在这些项目上的一些成功可能归因于更简单的词汇或者 n-gram 信息。
完成灵敏度 接下来,我们测试 BERT 是否有能力偏向期望的完成而不是相同语义类别的不适当的完成。我们首先通过简单地测量 BERT 指定期望完成(例如,表 1 的口红)比不合适的完成(例如,睫毛膏、手镯)更高概率的 item 的百分比。结果如表 5 所示,我们发现 BERT(BASE) 在 73.5% 的 item 中未在期望完成中分配最高的概率得分,而 BERT(LARGE) 在 79.4% 的 item 中为期望完成分配最高的概率得分,大多数情况是这样,但是对于一个不合适的、语义相关的目标来说,显然有一部分 item 的结果概率高于合适的词。
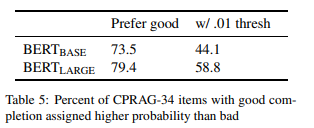
如果我们引入概率差的阈值,可以使我们的标准稍微更严格一些。根据这些项目的数据,好的和坏的完成之间的平均完形填空概率差约为 0.74,反映出人类对完成质量差异的强烈敏感性。为了测试 BERT 分配更多实质性不同概率的 item 比例,我们将筛选出良好完成概率高于 0.01 的 item。
考虑到显著的平均完形差,我们选择松散的阈值。在这个阈值下,敏感度明显下降,BERT(BASE) 仅在 44.1% 的 item 中显示敏感度,BERT(LARGE) 仅在 58.8% 的 item 中显示敏感度。这些结果告诉我们,尽管在大多数这些 item 中,模型能够选择好的结果比相同类别的坏的结果,但在许多情况下差异非常小,表明这种敏感性低于我们在人类完形填空反应中看到的。
预测检查的定性实验 上面我们看到,BERT 模型能够在大约一半的 CPRAG-34 项目中识别正确的单词补全,并且模型能够在大多数项目中选择好的补全,而不是语义相关的不适当的补全,尽管其敏感度明显低于人类。为了更好地理解模型的弱点,在本节中,我们将研究当模型失败时所做的预测。
表 6 显示了三个示例项目以及 BERT(LARGE) 的前五个预测。在每一种情况下,BERT 都会提供了在第二句话的上下文中合理的结果词,但没有考虑到第一句话提供的上下文,特别是,预测显示没有证据表明它能够推断出有关场景的相关信息或第一句中描述的对象。例如,我们在第一个例子中看到,BERT 正确地将注意力集中在人们可以接到的东西上,但是它没有推断出要借的东西是用来切割木材的东西。同样,BERT 没有发现第二个项目的铲雪主题,这使得推理出一组奇怪的完成。最后,第三个例子表明,BERT 已经确定了一个动物主题(毫不奇怪,给出了“动物园”和“动物”),但它并没有应用黑色和白色条纹这一短语来确定斑马这一合适结果。总之,这些例子说明,在常识推理和语用推理的目标能力方面,BERT 在这些更具挑战性的案例中失败了。

接下来,我们将讨论语义角色敏感性和事件知识的角色 ROLE-88 测试结果。
BERT 预测精确度 我们再次通过模型的 top k 预测完形项来定义精确度。表 8(“Orig”)显示了 BERT(LARGE) 和 BERT(BASE) 的精确度。对于 k=1,精确度很低,BERT(BASE) 的表现略优于 BERT(LARGE)。当我们扩大到 k=5 时,准确度可以预见地增加,现在 BERT(LARGE) 以一个可观的 margin 超过 BERT(BASE)。
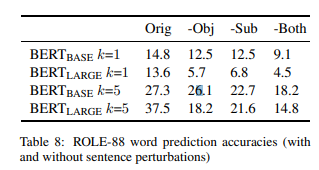
为了测试 BERT 在上下文中对单个名词的依赖程度,我们尝试了上下文的两种不同的扰动:从对象中删除信息(which customer the waitree....)和从主题中删除信息(which customer the waitress ...),在每种情况下,用一个通用的替代词替换名词。为了使名词具有高度的通用性,我们分别选择一个和另一个作为宾语和主语的替换词。
表 8 显示了这些扰动单独和一起的结果。我们观察到几个显著的模式。首先,删除对象(“-Obj”)或者主题(“-Subj”)对 BERT(BASE)k=1 或者 k=5 的精确度影响相对较小。这与我们在 BERT(LARGE) 中看到的情况大不相同,当对象或主题信息被删除时,其准确性会大幅下降。这些模式表明,BERT(BASE) 不太依赖主语 - 宾语结构的完整细节,而是主要依赖于参与动词预测的名词中的一个或另一个。另一方面,BERT(LARGE) 似乎对这两个名词都做了大量的使用,这样一来,任何一个名词的丢失都会对预测的准确性造成非平凡的破坏。
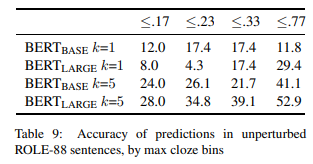
应该注意的是,这个集合中的项目总体上没有第 6 节中的项目那么具有约束性 -,人类在相同的预测上的收敛不太明显,从而导致最佳结果的平均完形值较低。为了研究约束级的影响,我们将每个句子的 top 完形值分为四个分桶。结果如表 9 所示,除了 k=1 的 BERT(BASE) 外,对所有的分桶精度都相对低的情况下,很明显最高得分的完形分桶比其他三个分桶有更高的精度,这表明人类的约束环境和对 BERT 的约束环境之间存在某种一致性。然而,当至少三分之一的人聚集在同一个完成时,即使最高的完形分桶,k=5 的 BERT(LARGE) 也只在一半的情况下是正确的,这表明有很大的改进空间。
完成灵敏度 接下来,在适当的和角色逆转的上下文下,我们通过比较模型的特定完成概率来测试 BERT 对角色逆转的敏感性。,在 BERT 为合适的完成分配了比不合适的完成更高的概率的情况下,我们再次测试 item 的百分比。如表 10 所示,BERT(BASE) 倾向于在 75% 的 item 中保持良好的连续性,而 BERT(LARGE) 的持续性为 86.4%,与 CPRAG-34 的比例相当。然而,当我们应用 0.001 的阈值时,平均完形差异为 0.233,敏感性下降比 CPRAG-34 显著,分别为 31.8% 和 43.2%。
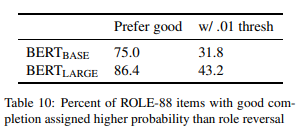
总的来说,这些结构表明,在大多数这种情况下,BERT 能够用名词位置来表示好的动词补语而不是坏的动词补语。然而,它对这些区别又不如人类敏感,而且在大多数情况下,它无法与人类的词汇预测相匹配。该模型选择好的完成而不是角色倒转(尽管敏感性较弱)的能力表明,单词预测准确性的失败不是由于无法区分单词顺序决定,而是由于事件知识或理解语义角色含义的弱点引起的。
预测检查的定性分析 表 7 显示了 BERT(BASE) 和 BERT(LARGE) 对一些示例的预测。对于“girl/bear”项目,我们看到 BERT(BASE) 倾向于以“bear”为主题的“killed”和“bitten”等的延续,但也包含以“girl”为主题的这些延续。相比之下,BERT(LARGE) 排除了以 girl 为主题的延续。
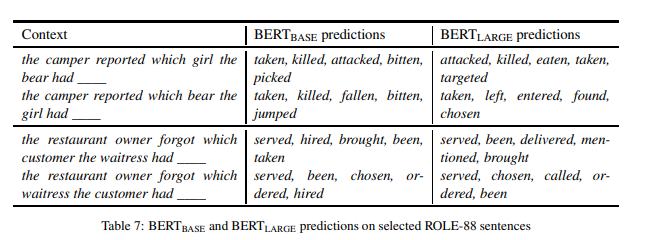
在第二个句子对中,我们看到模型在两个词序下选择“served”作为 top 延续,尽管对于第二个词序,这产生了一个不太可能的场景。在这两种情况下,对合适的词序,模型为“served”分配的概率要比不合适的高得多。对于 BERT(LARGE), 差异为 0.6;对于 BERT(BASE), 差异为 0.37;但是,值得注意的是,对于“which waitress the customer had _”,没有任何一种模式可以识别出语义上更合适的延续。
作为一个最终的注释,虽然延续性一般来说是印象深刻的语法,但我们在第二个“bear/girl”的句子中看到了例外。
最后,我们看看否定和类别成员的 NEG-88 的测试结果。
BERT 的预测准确性 我们首先测试 BERT 在 NEG-88-SIMP 中预测肯定上下文的正确类别延续的能力。表 11 显示了这些肯定句的准确度结果。
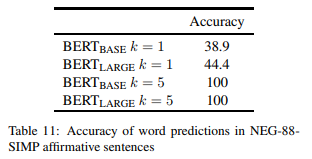
我们看到,对于 k=5,100% 肯定项的正确类别是可以预测的,这表明两个 BERT 模型都有很强的能力将名词与其正确的直接上位词联系起来。我们还发现,当 k=1 时,精度大幅下降。对预测的检测表明,这些错误只包括 BERT 用主语名词的重复来完成句子的情况,例如,A daisy is a daisy ,这当然是正确的,但它不是一个可能的或者信息丰富的句子。
完整灵敏度 接下来,我们通过测量 item 的比例来评估 BERT 对否定含义的敏感性,在这些 item 中,模型将更高的概率分配给真正的完成,而不是错误的完成。
表 12 显示了结果,并且模式是鲜明的。当声明是肯定的(A robin is a __),100% 的 items 模型会分配更高的概率给正确的完成。即使阈值为 0.01,消除了对 CPRAG-34 和 ROLE-88 的许多比较,除了一个 item(对于 BERT(BASE)),其他 item 都通过了,这表明对正确的完成有着强烈的倾向。
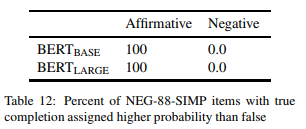
然而,在否定语句中(A robin is not a _),BERT 没有一个 item 倾向于正确的完成,在每种情况下都将较高的概率分配给错误的结果。这显示出对于否定意义的强烈不敏感,BERT 宁愿每次都完成类别匹配,尽管它是错误的。
预测检验的定性分析 表 13 显示了 BERT(LARGE) 在肯定、否定两种情况下的预测示例。我们可以清楚地看到上述结果所显示的现象:对于肯定句,BERT 通常会产生正确的补语(至少在前两个),但这些补语在加上否定后基本上保持不变,导致许多明显不正确的补语。
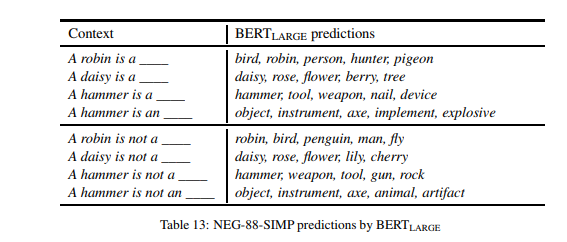
表 13 中我们可以观察到的另一个有趣的现象是 BERT 对掩码词前面的限定词(a 或 an)的性质的敏感性。根据即将到来的目标是以一个元音还是辅音开始(例如,我们与 hammer 不匹配的类别是 insect), 因此模型可以潜在地使用这个提示来过滤那些以元音或者辅音开头的预测。BERT 如何有效地使用这个提示?预测表明,BERT 在很大程度上非常擅长使用这个提示来限制以正确的字母开头的单词。有一些例外(例如,An ant is not a ant ),但这些都是少数。
自然度提高 互补的 NEG-88-NAT item 允许我们进一步检查模型对否定的处理,这些 item 项旨在测试“自然性”的效果。当我们用这组新的句子呈现 BERT 时,模型确实显示了对否定的敏感性的明显变化。BERT(BASE) 为 75% 的自然句(“NT”)指定了比“FALSE”更高的真实陈述概率,BERT(LARGE) 为 87.5% 的自然句指定了这样的概率。相比之下,每个模型仅在设计为不太自然的 item("LN") 中的 37.5% 中显示出对真实陈述的偏好。表 14 显示了通过肯定和否定条件分解的这些敏感性。在这里我们看到,在自然句中,BERT 对肯定句和否定句都喜欢真实陈述,相反,不自然的句子显示了 NEG-88-SIMP 中的模式,在 NEG-88-SIMP 中,BERT 对肯定句的偏好比例很高,这意味着 BERT 默认与主题类别的匹配。
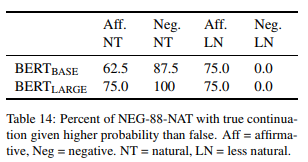
表 15 包含了 BERT(LARGE) 对“Natural”句子集中两对句子的预测。值得注意的是,即使 BERT 的第一个预测在上下文中是适当的,最优秀的候选项往往互相矛盾(例如,difficult/easy)。我们也看到,即使有了这些自然的 item,有时否定也不足以逆转结果,就像第二对句子一样,在第二对句子中,哪顿快餐晚餐既浪漫又不浪漫。
我们的三种诊断方法允许通过预训练的 BERT 模型对预测所用的信息类型进行清晰的描述。在 CPRAG-34 数据集中,我们发现两个模型大约一半的时间(k=5)可以预测最佳完成,并且两个模型都非常依赖于单词顺序和完整的句子上下文。然而,面对干扰的成功预测也表明,当我们研究对具有挑战性的项目的预测时,BERT 在这些项目上的一些成功可能会利用某些漏洞,我们可以看到这个集合针对常识和语用推理的明显弱点。敏感性测试显示,在大多数项目中,BERT 也可以选择好的完成方式而不是坏的语义相关的完成,但是这些概率差异很多都很小,这表明模型敏感性比人类低得多。
在 ROLE-88 数据集中,BERT 在匹配人类最高预测方面的准确度要低得多,而 BERT 得准确度仅为 37.5%,即使在有限制的上下文下,也仅为 53%。扰动揭示了有趣的模型差异,这表明 BERT(LARGE) 比 BERT(BASE) 对主语和宾语名词之间的相互作用更为敏感。敏感性测试表明,两种模型都能使用名词位置来选择好的补语,而不是角色倒转,但平均差异甚至小于 CPRAG-34,这再次表明模型区分的敏感性远远低于人类。该模型区分角色倒转的通用能力表明,较低的单词预测准确度不是由于词序不敏感,而是由事件知识或对语义角色含义理解的弱点决定的。
最后,NEG-88 允许我们特别清楚地将 BERT 的预测行为与使用所有可用信息的模型的期望值之前的差异归零,模型使用了关于词义和真 / 假的所有可用信息。当用描述类别成员关系的简单句子呈现时,BERT 完全不能在否定句中偏向正确的完成。这个模型显示了一种令人印象深刻的能力,可以将主语名词与它们的上位词联系起来,但是当否定颠倒了这些上位词的真实性时,BERT 仍然继续预测它们。相比之下,当有更“自然”的句子出现时,不管是否是“否定”,BERT 确实更喜欢肯定的完成。尽管后一句的设计初衷不同,但很有可能不是自然本身推动了模型在这些句子上的相对成功,而是更高频率的训练数据中的这些类型的陈述。
后一个结果特别突出了,对这些经过预训练的语言模型所带来的结果的一个明显的但最终并不令人惊讶的观察。人类语言处理的功能是计算含义和判断真相,而语言模型被训练为预测模型,它们将简单地利用最可靠的线索来优化预测能力。对于一个像否定这样的现象,这通常不利于清晰的预测,这样的模型可能不具备学习这个词意义的含义的能力。
在本文中,为了通过更好地理解通过语言建模的预先训练获得的语言能力,我们介绍了一套语言模型的诊断测试。我们的测试来源于心理语言学研究中,通过测试单词预测准确性和模型概率对语言差异的敏感性,使我们能够衡量一系列语言能力。作为一个研究案例,我们运用这些测试来分析流行的 BERT 模型的优点和缺点,研究发现,它对角色反转和同一类区分(尽管比人类小)具有敏感性,并成功地使用名词的上位词,但它在具有挑战性的推理和基于角色的事件预测方面表现不好,并且在否定含义方面的表现很失败。
这些测试集的能力并不全面,未来的工作可以建立在这些数据集的基础之上,以扩展到语言处理的其他方面。因为这些集合很小,我们也必须保守我们的结论,将来的工作可以扩展来验证这些结果的普遍性。同时,我们希望这些诊断所发现的弱点能够有助于确定需要建立健全和可推广的语言理解模型的领域。
论文原文链接:
https://arxiv.org/pdf/1907.13528.pdf

你也「在看」吗?👇



