如何可视化BERT?你需要先理解神经网络的语言、树和几何性质
选自GitHub
作者:Andy Coenen等人
机器之心编译
参与:熊猫
BERT 是当前最佳的自然语言处理模型之一,也因此极其复杂。Google AI 的 People + AI Research(PAIR)团队近日发布的论文《Visualizing and Measuring the Geometry of BERT》提出了一种可视化和度量 BERT 的几何性质的方法,可帮助我们理解 BERT 等神经网络语言模型表征信息的方式。该团队在发布论文后还会发布一系列解释说明文章,目前公布的第一篇介绍了神经网络中的语言、树和几何性质。机器之心对该文章进行了编译介绍,更多详情请参阅原论文。
论文:https://arxiv.org/pdf/1906.02715.pdf
博客:https://pair-code.github.io/interpretability/bert-tree/
语言的结构是离散的,而神经网络则基于连续数据运作:高维空间中的向量。成功的语言处理网络必须要能将语言的符号信息转译为某种几何表征——但是这种表征该是怎样的形式呢?词嵌入提供了两种著名的示例:用距离编码语义相似度,特定的方向则对应于极性(比如男性与女性)。
近段时间,一个激动人心的发现带来了一种全新类型的表征方式。关于一个句子的语言信息中,一大关键部分是其句法结构。这种结构可以表示成树,其节点对应于句子的词。Hewitt 和 Manning 在论文《A Structural Probe for Finding Syntax in Word Representations》中表明某些语言处理网络能够构建这种句法树的几何副本。词是通过在一个高维空间的位置给定的,而(遵照一定的变换)这些位置之间的欧几里德距离映射了树距离。
但这一发现还伴随着一个很有趣的谜题。树距离与欧几里德距离之间的映射不是线性的。相反,Hewitt 和 Manning 发现树距离对应于欧几里德距离的平方。他们提出了疑问:为什么必需平方距离,是否存在其它可能的映射。
这篇文章将为这个谜题提供一些潜在的解答。我们将从数学角度表明:树的平方距离映射是尤其自然的。甚至某些随机化的树嵌入也将服从近似的平方距离定律。此外,只是知道平方距离关系,就能让我们简单明确地描述树嵌入的整体形状。
我们会在一个网络(BERT)中分析和可视化真实世界的嵌入以及它们与其数学理想形式(mathematical idealizations)的系统性差异,以对这些几何论点进行补充说明。这些实证研究将提供用于思考神经网络中句法表征的新的定量方法。
从理论上解读树嵌入
如果你要将一个树(tree)嵌入到欧几里德空间中,为什么不直接将树距离对应于欧几里德距离呢?一个原因是:如果这个树有分支,则无法实现等距离扩展。

图 1:你无法在保证距离不变的同时将这个树嵌入到欧几里德空间中
事实上,图 1 中的树就是一个标准示例,表明并非所有度量空间都可以等距离地嵌入到 R^n 中。因为 d(A,B)=d(A,X)+d(X,B),所以在任意嵌入中 A、X 和 B 都是共线的。基于同一逻辑,A、X 和 C 也是共线的。但这就意味着 B=C,这是矛盾的。
如果一个树包含分支,则其将包含该配置的一个副本,也无法以等距离的方式嵌入。
毕达哥拉斯嵌入(Pythagorean embeddings)
相反,平方距离嵌入实际上要好得多——它是如此好用以至于有专属名称。这个名字的来由将在后面介绍。
定义:毕达哥拉斯嵌入
令 M 为一个度量空间,其度量为 d。如果对于所有 x,y∈M,我们有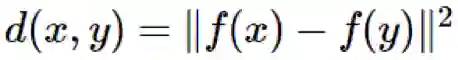
图 1 中的树有毕达哥拉斯嵌入吗?有的:如图 2 所示,我们可以将各个点分配到一个单位正方体的邻近顶点,毕达哥拉斯定理(即勾股定理)就能提供我们想要的结果。
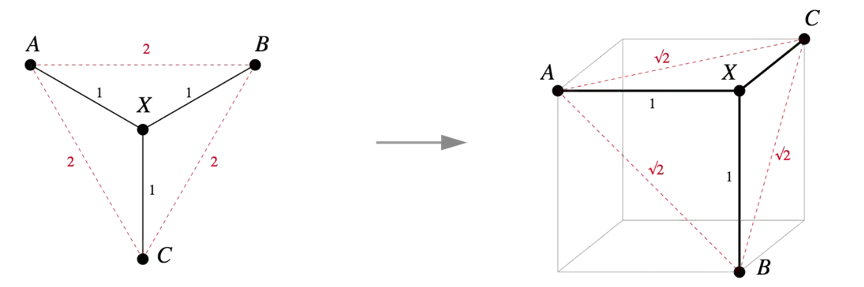
图 2:在单位正方体的顶点上的一个简单毕达哥拉斯嵌入
其它小型的树又如何呢,比如四个顶点构成的链?这也能在正方体的顶点中有很好的毕达哥拉斯嵌入。
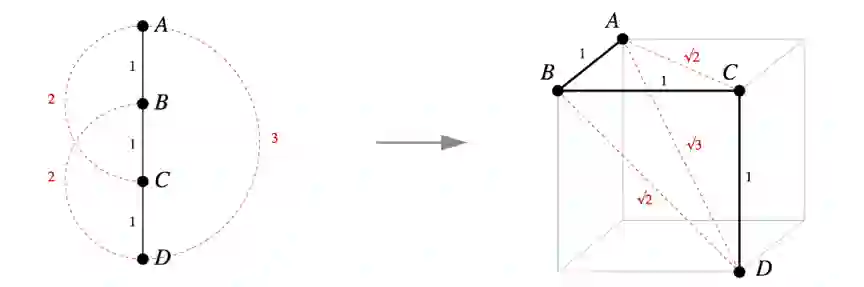
图 3:四个顶点构成的链也有在单位正方体的顶点上的毕达哥拉斯嵌入
这两个示例都不是偶然例外。实际上我们能明确地直接写出任何树在单位超立方体的顶点上的毕达哥拉斯嵌入。
定理 1.1
任何有 n 个节点的树都有在 R^(n-1) 中的毕达哥拉斯嵌入。
证明。
注:我们注意到与定理 1.1 的证明相似的论据也出现在 Hiroshi Maehara 的「有限度量空间的欧几里德嵌入」中:https://doi.org/10.1016/j.disc.2013.08.029
令树 T 的节点为 t_0,...,t_(n−1),其中 t_0 为根节点。令 {e_1,...,e_(n−1)} 为 R^(n-1) 的正交单位基向量。经过归纳,定义一个嵌入 f:T→R^(n−1):
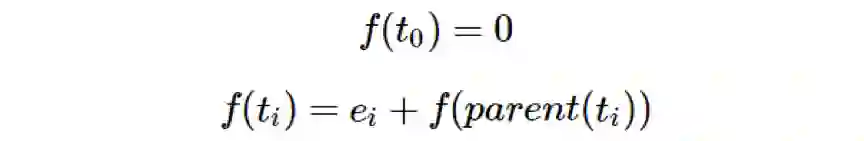
给定两个不同的树节点 x 和 y,m 是它们的树距离 d(x,y),则我们可使用 m 个互相垂直的单位步从 f(x) 移动到 f(y),因此:
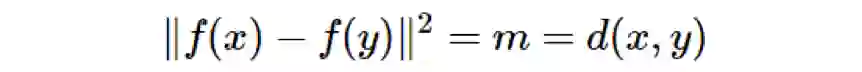
看待这种构建方式的一个角度是:我们为每条边分配了一个基向量。为了得到节点的嵌入,我们走回到根并将我们经过的边的所有向量加起来。见下图。
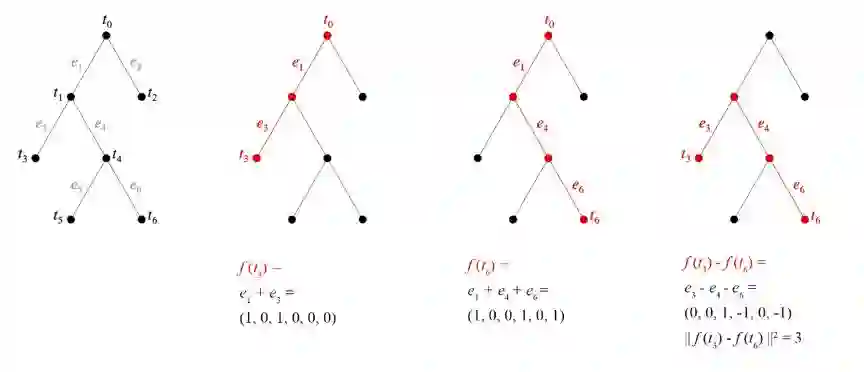
图 4:左:将基向量分配给边。中:两个示例嵌入。右:平方的距离等于树距离。
备注
这个证明的价值不只是证明存在这个结果,而且是在明确的几何构建中存在这个结果。同一个树的任何两个毕达哥拉斯嵌入都是等距离的——而且通过旋转或反射而存在关联,因为两者之中所有点对之间的距离都一样。所以我们说对于树的毕达哥拉斯嵌入,该定理向我们说明了其确切模样。
此外,定理 1.1 中的嵌入也有一个清晰的非形式化的描述:在图的每个嵌入顶点,所有连接邻近顶点的线段都是单位长度的线段,且与彼此和其它每条边线段正交。看一下图 1 和图 2 就能发现它们满足这种描述。
也可以轻松地看到,证明中构建的特定嵌入是一个 ℓ1 度量的树等距映射(tree isometry),尽管这非常依赖于轴对齐。
我们也可以对定理 1.1 进行略微的泛化。考虑边有权重的树,两个节点之间的距离是它们之间的最短路径上边的权重的和。在这种情况下,我们也总是可以创建毕达哥拉斯嵌入。
定理 1.2
任何有 n 个节点的加权的树都有在 R^(n-1) 中的毕达哥拉斯嵌入。
证明。
和前面一样,令树 T 的节点为 t_0,...,t_(n−1),其中 t_0 为根节点。令 {e_1,...,e_(n−1)} 为 R^(n-1) 的正交单位基向量。现在令 w_i=d(t_i,parent(t_i))。经过归纳,定义嵌入 f 为:
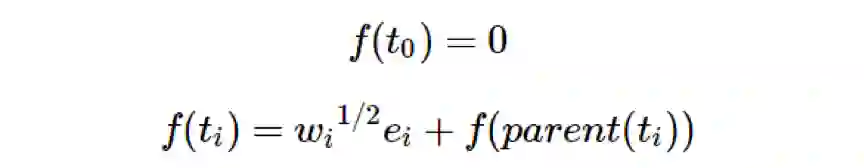
注:定理 1.2 的嵌入不再位于单位超立方体上,而是在其一个压扁的版本中:边长为
我们可以索引这个树的边,其中每条边的索引都与在该边上的子节点一样。令 P 为 x 与 y 之间的最短路径上边的索引的集合,则
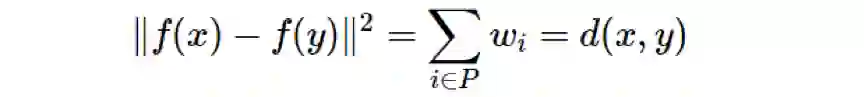
定理 1.2 中嵌入虽然是轴对齐的,但在 ℓ1 度量方面不再是等距离映射。但是,如果我们使用向量 w_ie_i 而不是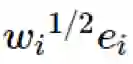
其它嵌入和缺乏嵌入的情况
Hewitt 和 Manning 问是否还有其它有效的树嵌入类型,也许是基于欧几里德度量的其它幂。我们可以提供一些有关这些嵌入的部分结论。
定义
令 M 为一个度量空间,其度量为 d。设如果对于所有的 x,y∈M,都有
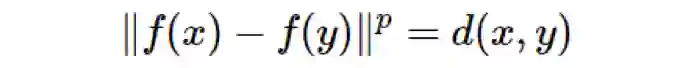
,则我们说 f:M→R^n 是幂为 p 的嵌入。
注:对于欧几里德空间中的嵌入的一般性问题的更多解释,请参阅这篇漂亮的概述:https://arxiv.org/pdf/1502.02816.pdf 和这个有用的书籍章节:http://www.csun.edu/~ctoth/Handbook/chap8.pdf
虽然使用的名字各不相同,但一般度量空间的幂为 p 的嵌入已被研究了数十年。这方面的奠基工作是 Schoenberg 1937 年的论文:https://www.jstor.org/stable/1968835。该论文的一个关键结果用我们的术语说来就是:如果一个度量空间 X 有在 R^n 中的幂为 p 的嵌入,那么对于任意 q>p,它也有幂为 q 的嵌入。因此当 p>2 时,任意树都总是有幂为 p 的嵌入。而 p=2 的情况则很不一样,我们还没有一种用于描述这种嵌入的几何性质的简单方法。
另一方面,当 p<2 时,事实证明幂为 p 的树嵌入甚至不一定存在。
定理 2
对于任意 p<2,存在「没有幂为 p 的嵌入」的树。
证明过程请参阅我们的论文(这里也有另一个证明:https://www.sciencedirect.com/science/article/pii/S0012365X13003841)。总结来说,对于任意给定的 p<2,没有足够的「空间」来嵌入带有足够多子节点的节点。
随机分支的嵌入近似为毕达哥拉斯嵌入
毕达哥拉斯嵌入的性质非常稳健,至少在维度远大于树规模的空间中是这样。(举个例子,这就是我们的语言处理神经网络的激励示例的情况。)在上面的证明中,除了使用基向量 e_1,...,e_(n−1) ∈R^(n−1),我们本可以从 R^m 的单元高斯分布中完全随机地选出 n 个向量。如果 m≫n,那么结果有很高的可能性会是近似的毕达哥拉斯嵌入。
原因是在高维空间中,(1)来自单位高斯分布的向量的长度有很高的可能性非常接近于 1;(2)当 m≫n 时,一组 n 个单位高斯向量将很有可能接近于彼此正交。
换句话说,在足够高维度的空间中,树的随机分支的嵌入(其中每个子节点都与其父节点偏移一个随机的单位高斯向量)将接近于毕达哥拉斯嵌入。
这种构建甚至可以通过一个迭代过程完成,仅需「局部」信息。使用完全随机的树嵌入进行初始化,再为每个顶点选取一个特殊的随机向量;然后在每个步骤移动每个子节点,使其更靠近其父节点加该子节点的特殊向量。其结果会是近似的毕达哥拉斯嵌入。
毕达哥拉斯嵌入很简洁,而且它们源自局部随机模型,这说明它们在表征树方面可能是普遍有效的。要注意,树的大小受场景的维度所控制,它们也许是基于双曲几何的方法的低技术替代方法。
注:更多有关双曲树表征的知识请参阅《Hyperbolic Embeddings with a Hopefully Right Amount of Hyperbole》:https://dawn.cs.stanford.edu/2018/03/19/hyperbolics/ 或 Nickel & Kiela 的《Poincaré Embeddings for Learning Hierarchical Representations》:https://arxiv.org/abs/1705.08039
实践中的树嵌入
我们已描述了树嵌入的数学理想形式,现在回到神经网络世界。
我们研究的对象是 BERT 模型,这是近期一种针对自然语言处理的成功模型。我们对这一模型感兴趣的一大原因是其在很多不同任务上都表现优良,这说明其能够提取出普遍有用的语言特征。BERT 基于 Transformer 架构。
注:BERT 背景:这是谷歌博客的介绍:https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html ;这里还有一篇很棒的总结:https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270。还有很多论文分析了这些网络,比如《BERT Rediscovers the Classical NLP Pipeline》:https://arxiv.org/abs/1905.05950。
我们这里不会详细描述 BERT 架构,只是简单说一下该网络的输入是词序列,经过一系列层之后能为其中每个词得到一系列嵌入。因为这些嵌入考虑了上下文,所以它们常被称为上下文嵌入(context embedding)。
人们已经提出了很多描述句法结构的方法。在依存语法中,每个词都是树的一个节点,如下图所示。
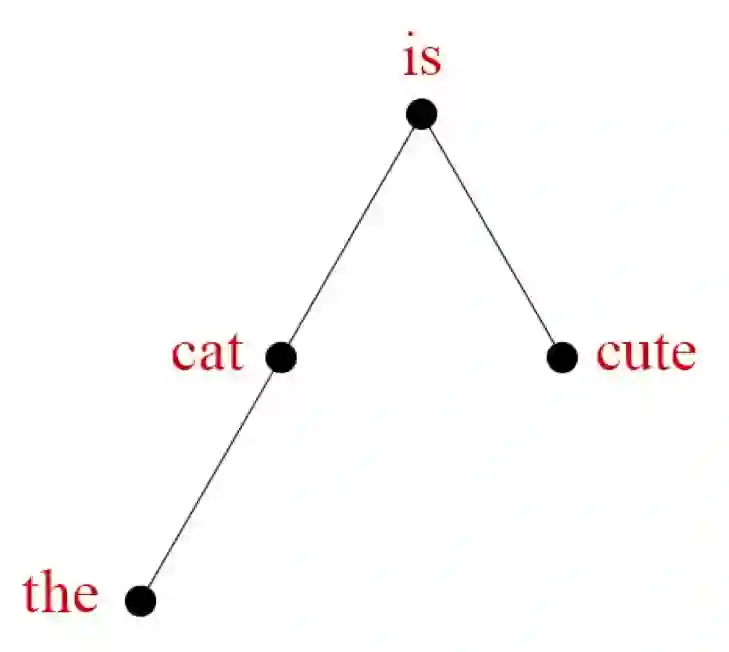
很多人都研究过这些嵌入,以了解它们可能包含什么信息。概括来说,我们研究树嵌入的动机是 Hewitt 和 Manning 的近期成果。他们的论文《A Structural Probe for Finding Syntax in Word Representations》表明上下文嵌入似乎以几何方式编码了依存解析树。
但有一点要注意:首先你需要通过一个特定的矩阵 B(即所谓的结构探针(structural probe))对这个上下文嵌入进行变换。但在此之后,两个词的上下文嵌入之间的欧几里德距离的平方接近两个词之间的解析树距离。这就是前一节的数学计算发挥功效的地方。用我们的术语说,这个上下文嵌入接近一个句子的依存解析树的毕达哥拉斯嵌入。这意味我们对树嵌入整体形状有很好的认知——就是简单地源自平方距离性质和定理 1.1。
可视化和测量解析树表征
当然,我们并不确切知晓其形状,因为该嵌入只是近似的毕达哥拉斯嵌入。但理想形状和实际形状之间的差异可能非常有趣。实验中的嵌入和它们的数学理想形式之间的系统性差异可能能为 BERT 处理语言的方式提供进一步的线索。
注:PCA 能得到比 t-SNE 或 UMAP 更可读的可视化。当点在一个低维流形上聚类或分散时,非线性方法的效果可能最好——基本上与 n-立方体的顶点相反。
为了研究这些差异,我们创造了一种可视化工具。我们的论文给出了详细情况,这里只提供些概述。该工具的输入是带有相关的依存解析树的句子。该软件会从 BERT 提取出该句子的上下文嵌入,经过 Hewitt 和 Manning 的「结构探针」矩阵的变换,得到一个在 1024 维空间中的点集。
然后,我们通过 PCA 将这些点映射到二维。为了展现其底层的树结构,我们连接了表示有依存关系的词的点对。下图 5 展示了一个样本句子的结果。为了比较,还给出了一个精确毕达哥拉斯嵌入、随机分支的嵌入、节点坐标完全随机的嵌入的相同数据的 PCA 投影。
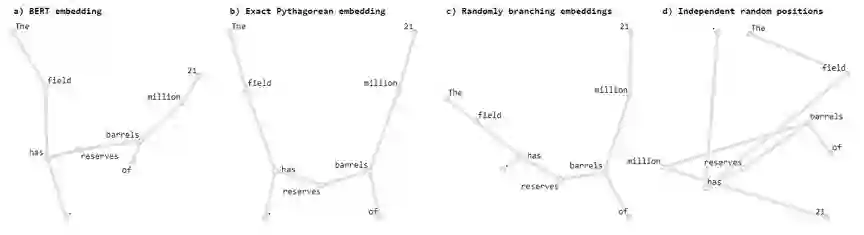
图 5:PCA 视图。a)BERT 解析树嵌入。b)精确毕达哥拉斯嵌入。c)不同的随机分支嵌入。d)节点位置是随机地独立选择的不同嵌入。该图的交互式版本请访问原文。
PCA 投影已经很有趣了——BERT 嵌入和理想形式之间有明显的相似性。图 5c 展示了一系列随机分支的嵌入,也类似于 BERT 嵌入。图 5d 是基线,展示了一系列词是随机地独立放置的嵌入。
但我们还可以更进一步,展示嵌入不同于理想模型的方式。在下面的图 6 中,每条边的颜色表示欧几里德距离与树距离之间的差。我们也用虚线连接了没有依存关系但位置(在 PCA 之前)比预期的近得多的词对。
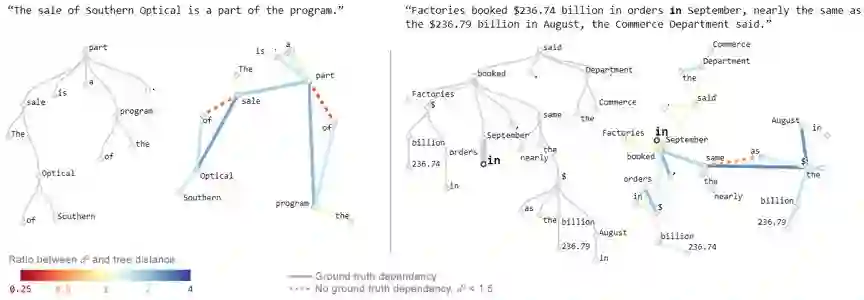
图 6:在应用了 Hewitt-Manning 探针后两个句子的嵌入的可视化。在每一对图像中,左图是传统的解析树试图,但每个分支的竖直长度表示嵌入距离。右图是上下文嵌入的 PCA 投影,其中的颜色表示偏离预期距离的程度。该图的交互式版本请访问原文。
所得到的图像既能让我们看到树嵌入的整体形状,也能让我们看到离真实毕达哥拉斯嵌入的偏离程度的细粒度信息。图 6 给出了两个示例。它们都是典型的情况,展示了一些常见的主题。图中,橙色虚线连接了 part/of、same/as、sale/of。这个效果很有特点,可以看到介词嵌入的位置与它们所相关的词出乎意料地近。我们还可以看到蓝色标示的两个名词之间的连接,这说明它们比预期的更远——另一个常见模式。
文末的图 8 展示了这些可视化的更多示例,你可以进一步查看这些模式。
基于这些观察,我们决定更系统地研究不同的依存关系将可能如何影响嵌入距离。回答这一问题的一种方式是考虑一个大型句子集并测试词对之间的平均距离是否与它们的句法关系存在任何关联。我们使用一个 Penn Treebank 句子集以及派生的解析树执行了这个实验。

图 7:给定的依存关系下,两个词之间的平方边长的平均
图 7 展示了这一实验的结果。结果表明每个依存关系的平均嵌入距离的变化范围很大:从大约 1.2(compound : prt, advcl)到 2.5(mwe, parataxis, auxpass)。研究这些系统性差异的含义是很有趣的。或许也许使用加权的树,BERT 的句法表征有优于普通依存语法的其它定量方面。
总结
神经网络表征语言信息的确切方式依然还是一个谜。但我们已经开始看到了有吸引力的线索。Hewitt 和 Manning 的近期研究为解析树的直接的几何表征提供了证据。他们发现了一种有趣的平方距离效应,我们认为这反映了一种数学上自然的嵌入类型——这能为我们提供一种惊人完整的嵌入几何思想。与此同时,对 BERT 中解析树嵌入的实验研究表明可能还有更多知识有待发掘,还有在解析树表征的更多定量方面有待探索。
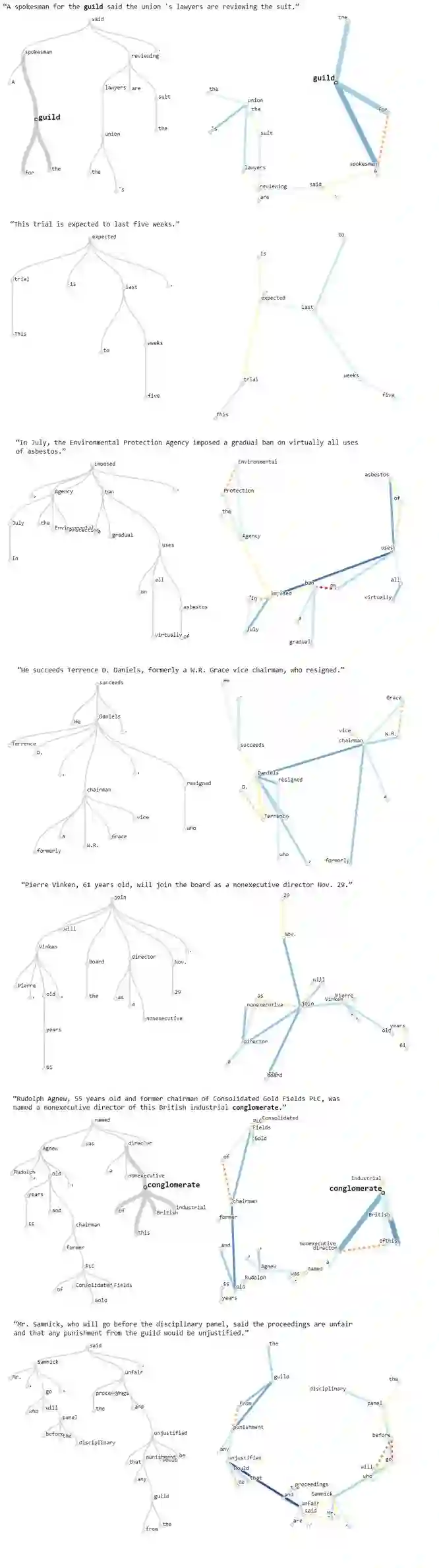
图 8:其它解析树示例;说明见图 6。该图的交互式版本请访问原文。
原文链接:https://pair-code.github.io/interpretability/bert-tree/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




