带你读论文丨 8 篇论文梳理 BERT 相关模型

新智元报道
【新智元导读】BERT 自从在 arXiv 上发表以来获得了很大的成功和关注,打开了 NLP 中 2-Stage 的潘多拉魔盒,随后涌现了一大批类似于 “BERT” 的预训练模型。本文通过8篇论文梳理了BERT相关论文,并分析了BERT在各种任务中的效用。
-
XLNet 及其与 BERT 的对比 -
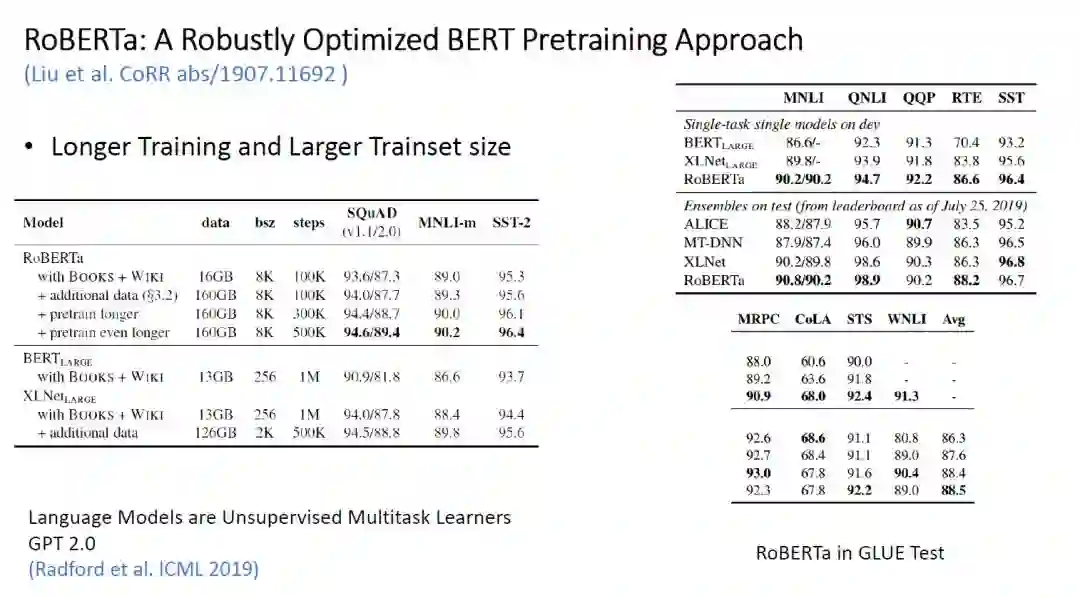
RoBERTa -
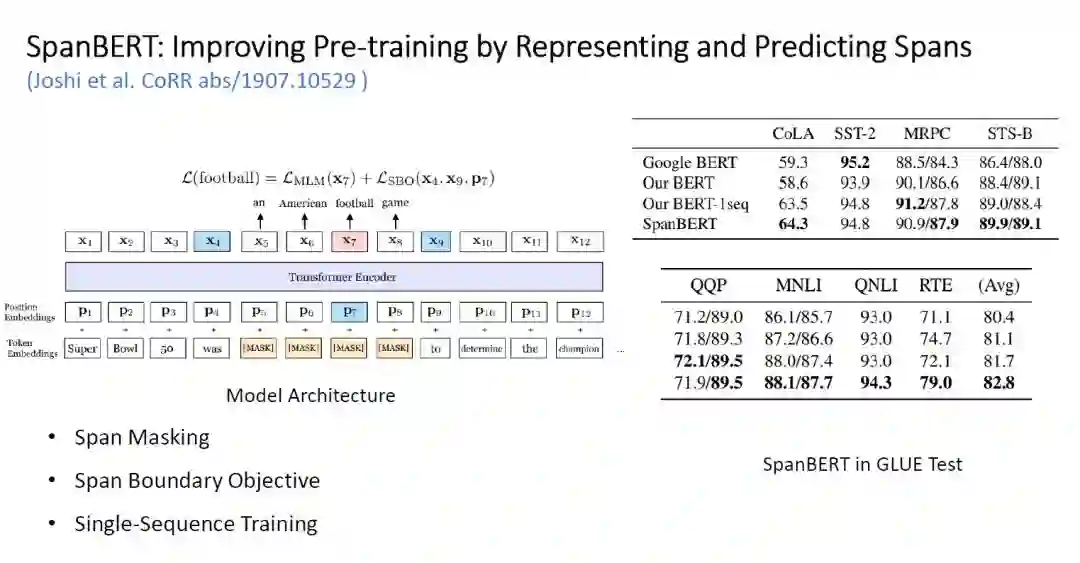
SpanBERT -
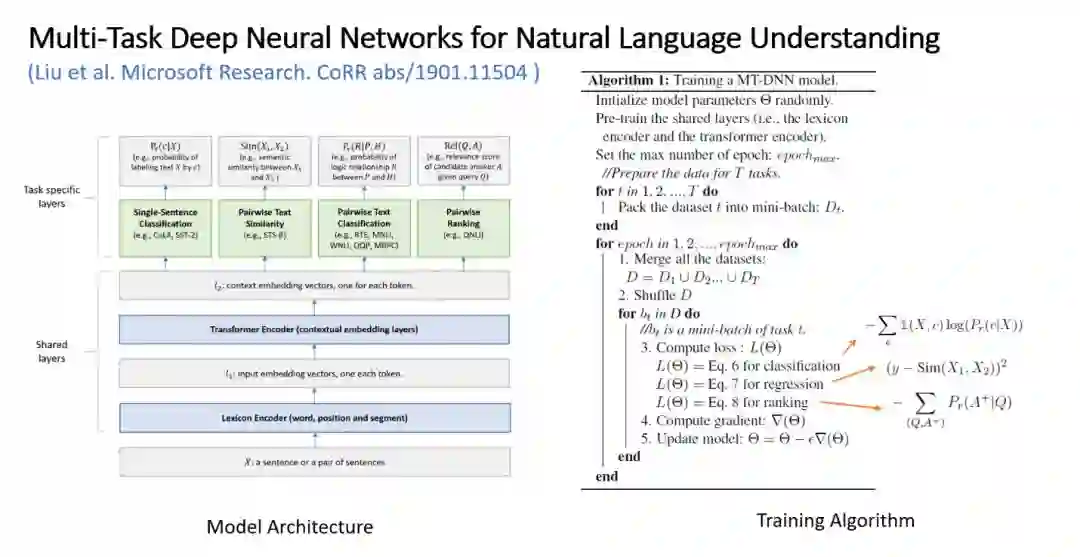
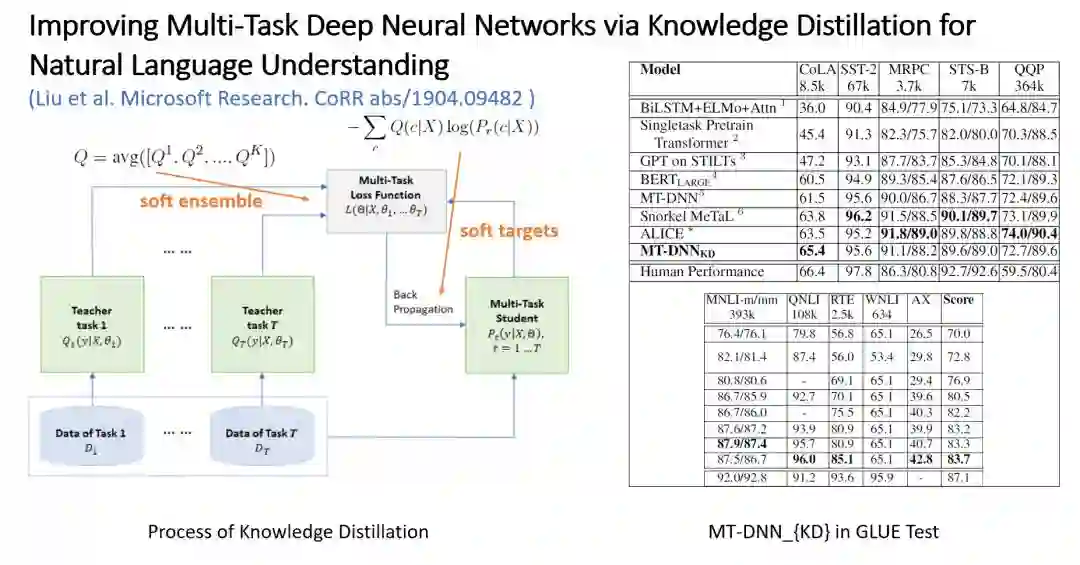
MT-DNN 与知识蒸馏
-
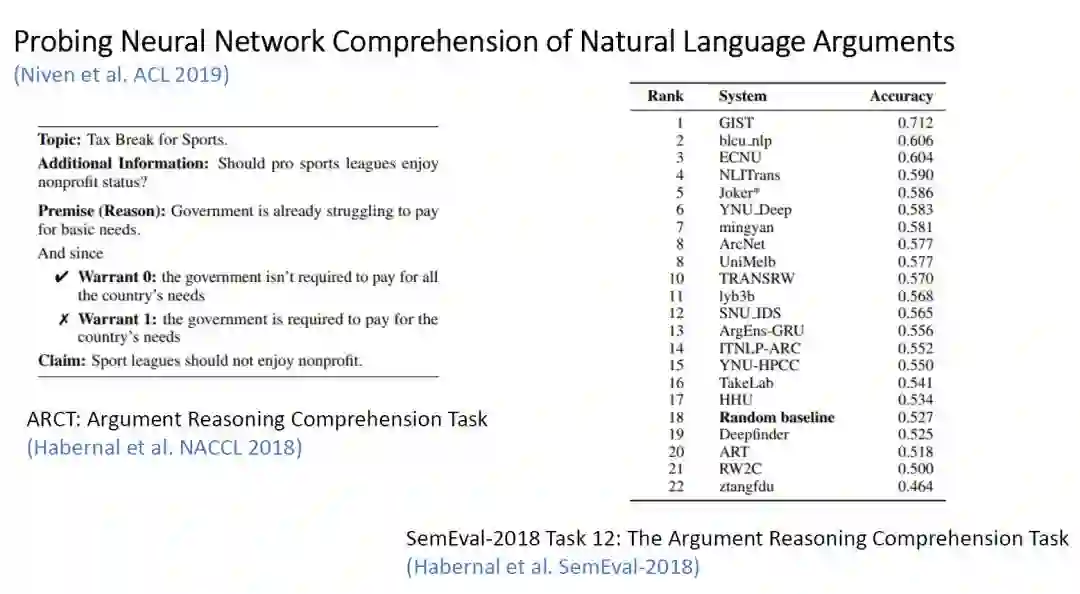
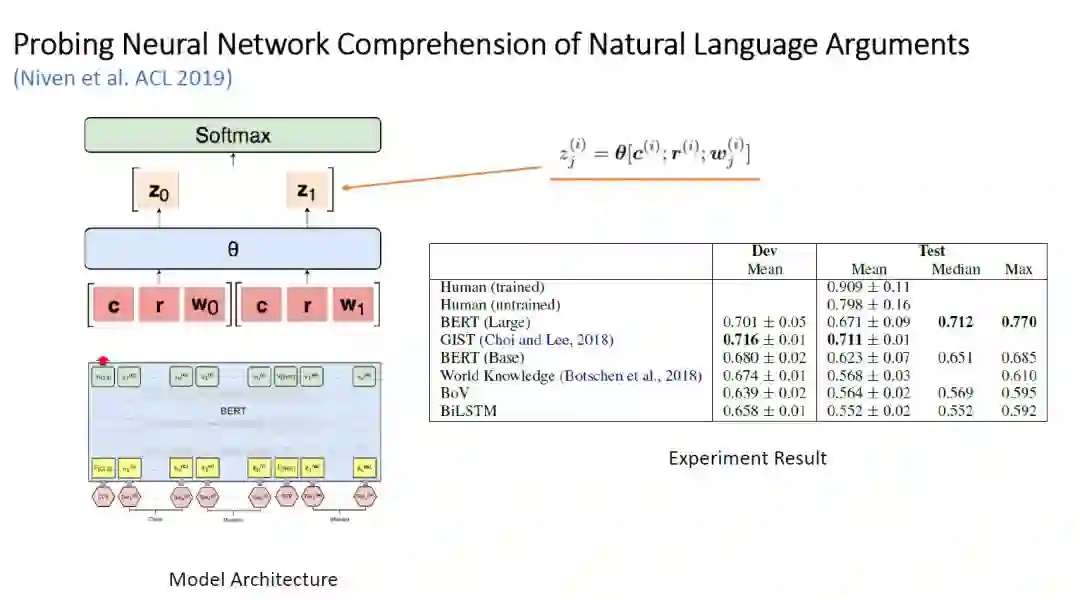
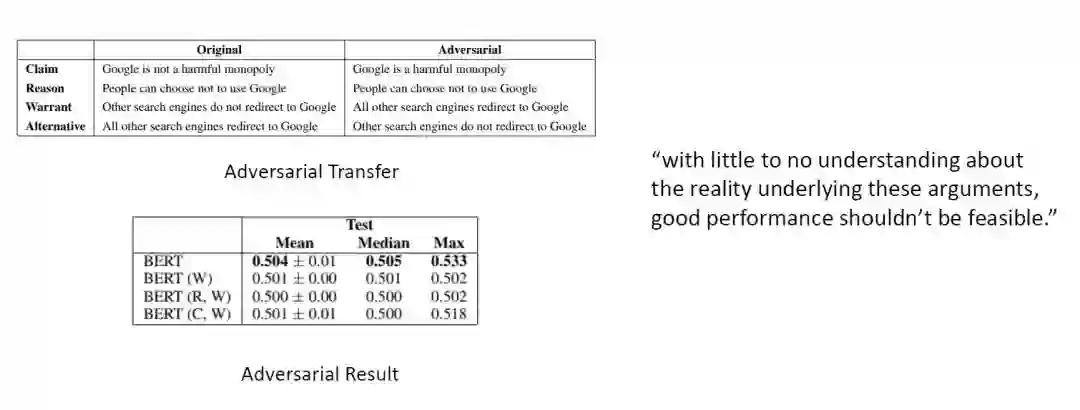
BERT 在 Argument Reasoning Comprehension 任务中的表现 -
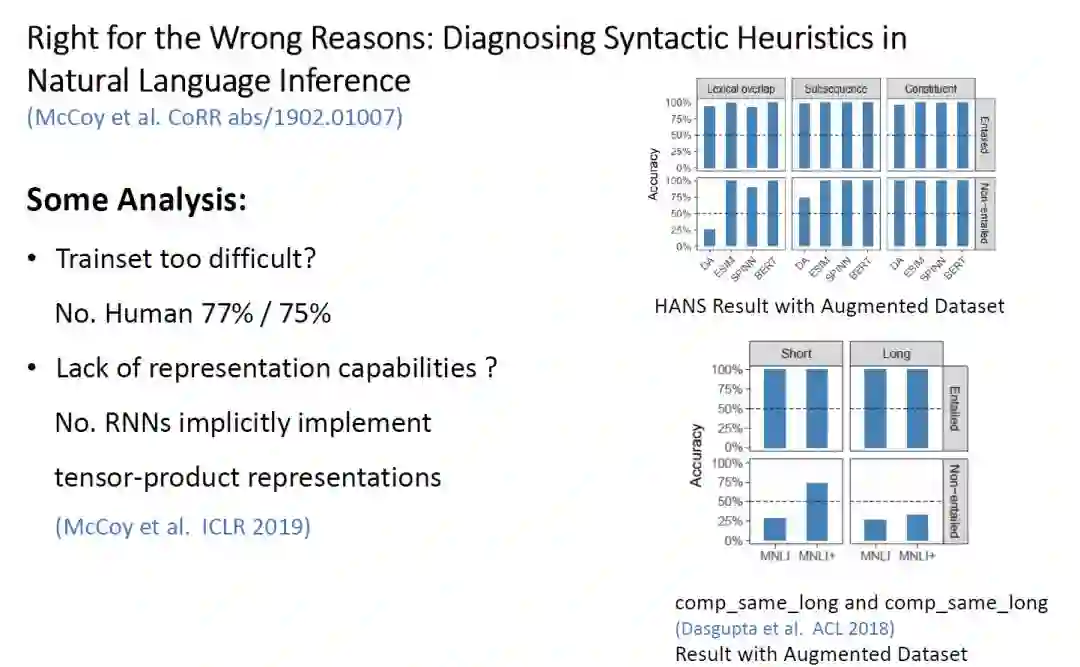
BERT 在 Natural Language Inference 任务中的表现
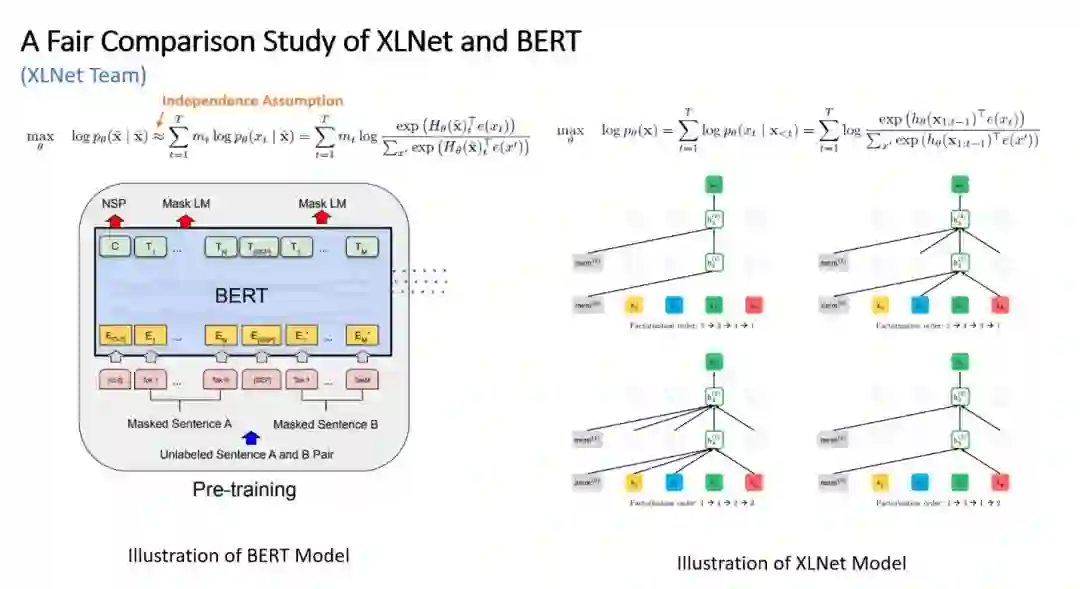
-
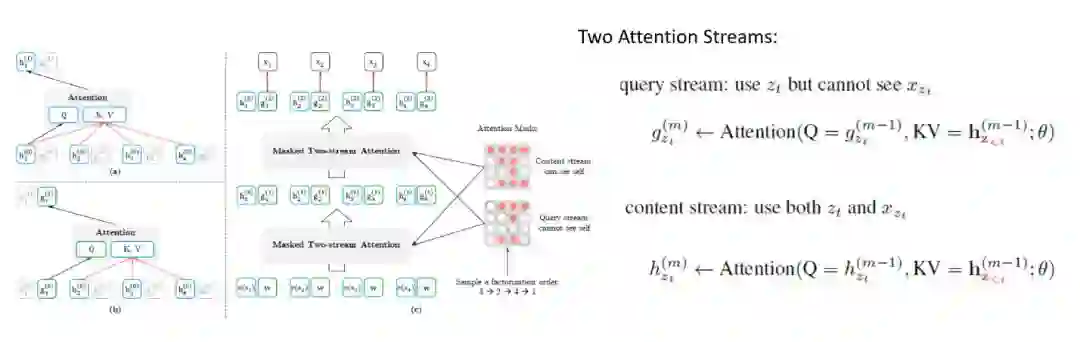
Permutation Language Model -
Two-Stream Self-Attention -
Recurrence Mechanism

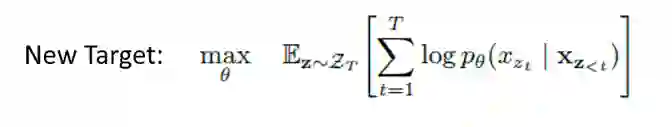
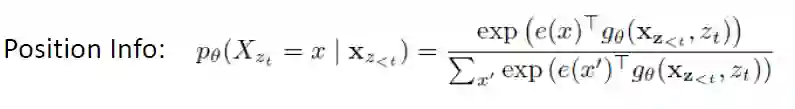
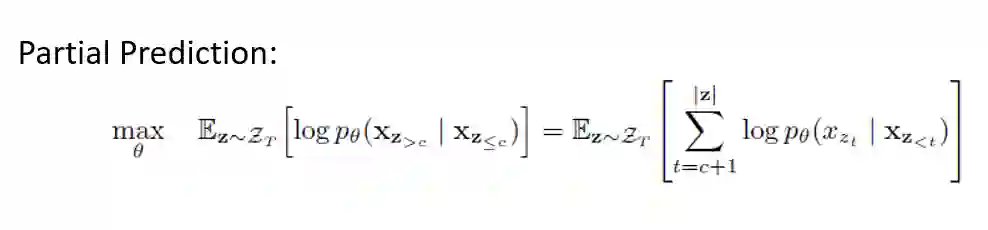



-
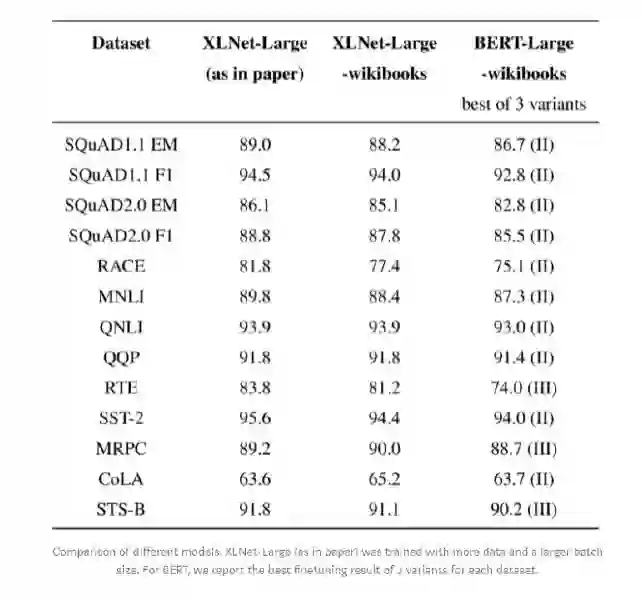
XLNet 在使用 Wikibooks 数据集时,在 MRPC(Microsoft Research Paraphrase Corpus: 句子对来源于对同一条新闻的评论,判断这一对句子在语义上是否相同)和 QQP(Quora Question Pairs: 这是一个二分类数据集。目的是判断两个来自于 Quora 的问题句子在语义上是否是等价的)任务上获得了不弱于原版 XLNet 的表现;
-
BERT-WWM 模型普遍表现都优于原 BERT;
-
去掉 NSP(Next Sentence Prediction)的 BERT 在某些任务中表现会更好;
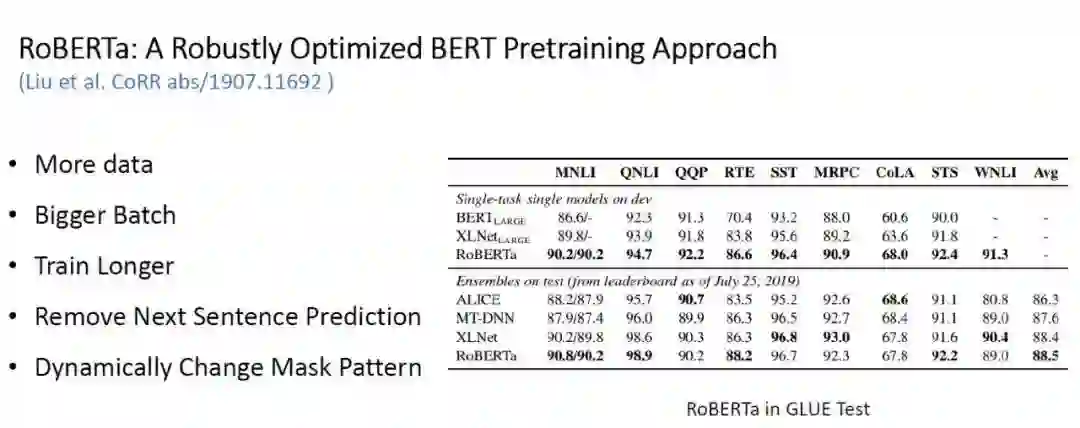
 表 3:RoBERTa 各个机制的效果比较实验
表 3:RoBERTa 各个机制的效果比较实验
-
Sentence-Pair+NSP Loss:与原 BERT 相同; -
Segment-Pair+NSP Loss:输入完整的一对包含多个句子的片段,这些片段可以来自同一个文档,也可以来自不同的文档;
-
Full-Sentences:输入是一系列完整的句子,可以是来自同一个文档也可以是不同的文档;
-
Doc-Sentences:输入是一系列完整的句子,来自同一个文档;
-
Span Masking:这个方法与之前 BERT 团队放出 WWM(Whole Word Masking)类似,即在 mask 时 mask 一整个单词的 token 而非原来单个 token。每次 mask 前,从一个几何分布中采样得到需要 mask 的 span 的长度,并等概率地对输入中为该长度的 span 进行 mask,直到 mask 完 15% 的输入。
-
Span Boundary Object:使用 span 前一个 token 和末尾后一个 token 以及 token 位置的 fixed-representation 表示 span 内部的一个 token。并以此来预测该 token,使用交叉熵作为新的 loss 加入到最终的 loss 函数中。该机制使得模型在 Span-Level 的任务种能获得更好的表现。
-
Single-Sequence Training:直接输入一整段连续的 sequence,这样可以使得模型获得更长的上下文信息。


-
A Cue's Applicability:在某个数据点 i,label 为 j 的 warrant 中出现但在另一个 warrant 中不出现的 cue 的个数。
-
A Cue's Productivity:在某个数据点 i,label 为 j 的 warrant 中出现但在另一个 warrant 中不出现,且这个数据点的正确 label 是 j,占所有上一种 cue 的比例。直观来说就是这个 cue 能被模型利用的价值,只要这个数据大于 50%,那么我们就可以认为模型使用这个 cue 是有价值的。
-
A Cue's Coverage:这个 cue 在所有数据点中出现的次数。

-
Lexical Overlap:对应的 Hypothesis 是 Premise 的子序列
-
Subsequence:对应的 Hypothesis 是 Premise 的子串
-
Constituent:Premise 的语法树会覆盖所有的 Hypothesis
-
HANS 数据集太难了?不。作者让人类进行测试,发现人类在两种类型的数据中准确率分别为 77% 和 75%,远高于模型。 -
是模型缺乏足够的表示能力吗?不。ICLR 2019《RNNs implicitly implement tensor-product representations》给出了一定的证据,表示 RNN 足够在 SNLI 任务中已经学到一定的关于结构的信息。
-
那就是 MNLI 数据集并不好,缺乏足够的信号让模型学会 NLI。

登录查看更多
相关内容

Arxiv
15+阅读 · 2018年10月11日

相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日