来源:微软研究院AI头条
【新智元导读】近日,国际计算语言学协会 ACL 举办的 WMT 2021 国际机器翻译比赛的评测结果揭晓。由微软亚洲研究院、微软翻译产品团队及微软图灵团队联合发布的 Microsoft ZCode-DeltaLM 模型获得了 WMT 2021 「大规模多语言翻译」赛道的冠军。该模型基于微软亚洲研究院机器翻译研究团队打造的能支持上百种语言的多语言预训练模型 DeltaLM,在微软 ZCode 的多任务学习框架下进行训练生成。研究员们希望能够借助该多语言翻译模型,有效支持更多低资源和零资源的语言翻译,终有一日实现重建巴别塔的愿景。
近期,在刚刚结束的国际机器翻译大赛(WMT 2021)上,微软亚洲研究院、微软翻译产品团队及微软图灵团队强强联手,在「大规模多语言机器翻译」评测任务赛道上大展风采,凭借 Microsoft ZCode-DeltaLM 模型以巨大的优势在该赛道的全部三项子任务上均取得排名第一的成绩。相比于参数量相当的 M2M 模型,Microsoft ZCode-DeltaLM 模型在大任务上更是获得了10个 BLEU 分数以上的提高。
WMT 国际机器翻译大赛是全球学术界公认的国际顶级机器翻译比赛。自2006年至今,WMT 机器翻译比赛已成功举办16届,每次比赛都是全球各大高校、科技公司与学术机构展示自身机器翻译实力的平台,更见证了机器翻译技术的不断进步。其「大规模多语言机器翻译」评测任务赛道提供了上百种语言翻译的开发集和部分语言数据,旨在推动多语言机器翻译的研究。该评测任务由三个子任务组成:一个大任务,即用一个模型来支持102种语言之间的10,302个方向上的有向翻译任务,以及两个小任务:一个专注于包括英语和5种欧洲语种之间的翻译,另一个专注于包括英语和5种东南亚语种之间的翻译。
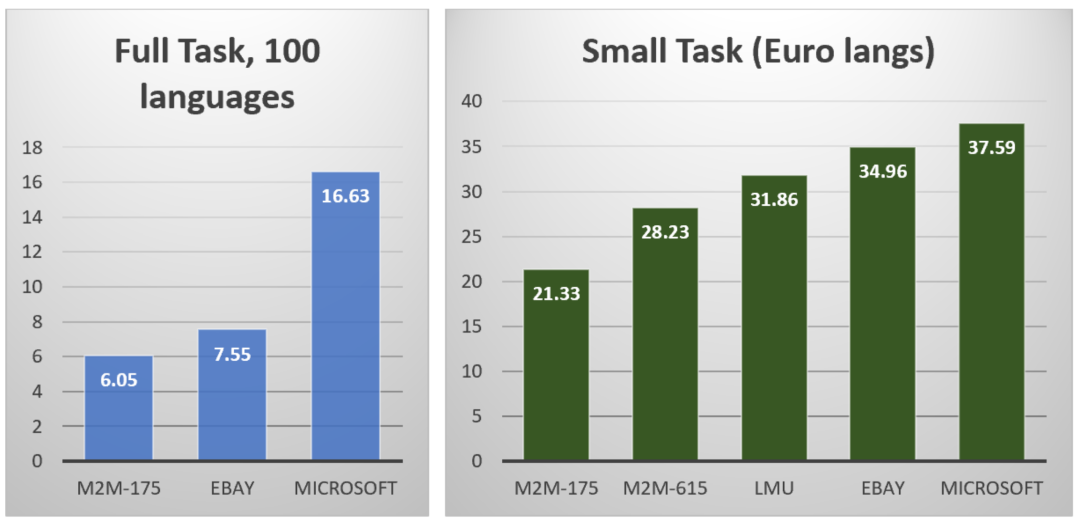
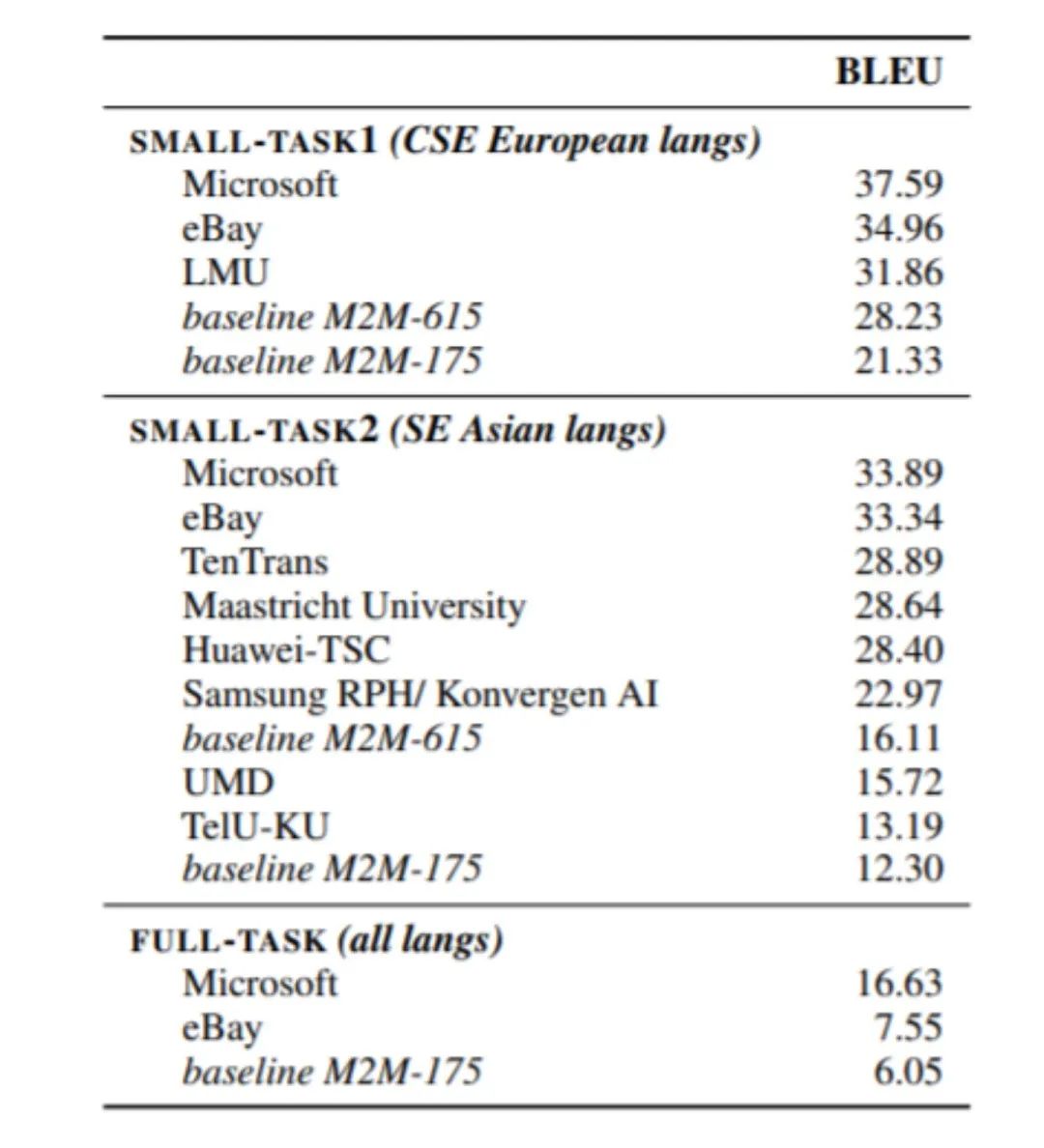
WMT 2021 大规模多语言翻译任务中 Full-Task 和 Small-Task1 的官方结果(BLEU分数)
据统计,目前世界上存在有7000多种不同的语言,有很多语言正濒临消失或已经消失了。每种语言都承载着不同的文明。笛卡尔曾经说过:「语言的分歧是人生最大的不幸之一」。长久以来,重建巴别塔,能够在经济活动、文化交流中消除语言造成的隔阂,实现语言互通,是人类共同的梦想。1888年,语言学家波兰籍犹太人柴门霍夫在拉丁语的基础上创立了一种新的语言,称为世界语(Esperanto)。他希望全世界人类都学习使用同一种语言。这是一个理想的解决方案,但世界语最后并没有流行起来。
彼得·勃鲁盖尔(Bruegel Pieter)于1563年创作的油画《巴别塔》。圣经上记载,人类最早生活在一起,使用同一种语言,后来人类越来越强大,他们想修建一座通往天堂的高塔,称为巴别塔。上帝听闻后震怒,为了阻止人类建造巴别塔,上帝打乱了人类的语言,让人类说不同的语言,相互之间不能沟通,巴别塔计划因此失败,人类从此散落世界各地。
后来,计算机科学家们希望通过算法模型来实现机器翻译。初期,科研人员们尝试设计规则完成任意两种语言之间的翻译,手段包括编撰双语词典、总结翻译转换规则、构建翻译知识库手段等。但是基于规则的方法存在很大缺陷,比如规则描述颗粒度大、覆盖率低、规则库维护代价极大等现象,从而导致翻译质量低、鲁棒性差,且容易出现新旧规则的冲突与兼容性问题。之后,研究人员开始尝试基于数据驱动的方法来解决语言翻译问题,从基于实例的方法,到基于统计的方法,再到目前流行的基于神经网络的方法。
基于数据驱动的翻译方法依赖于双语平行语料的数量和质量。受益于信息技术的发展,高资源语言的数据相对来说容易获得,机器翻译系统针对高资源语言的翻译质量越来越高,如今也得以大量部署和商用,帮助解决了部分语言之间的交流障碍,促进了各种跨语言的商业应用发展,使人们看到了重建巴别塔的希望。
但尽管如此,当前机器翻译仍面临着许多困难。首先,仍然有大量的低资源语言存在,它们的双语语料很难获取,所以针对低资源语言的独立机器翻译系统翻译质量非常低。其次,为所有语言单独建立机器翻译系统,开发、维护成本都非常大。
那么,有没有更好的技术方法能够一次性实现所有语言之间的翻译且兼顾翻译性能呢?为此,研究人员开始探索多语言机器翻译模型,即仅使用一个模型,来实现所有语言之间的翻译。这种模型方法的动机和优点在于:
(1). 基于数据驱动的方法,将所有语言编码映射到一个语义空间中,然后再从该空间通过解码算法生成目标语言。相对于显式构造的世界语来说,这个语义空间是隐式存在的,理论上它能够将所有人类语言的语义信息进行编码。就好比人类大脑能理解多种模态(视觉、触觉、听觉、嗅觉、味觉等)的输入信息,并对各模态发出相应的指令信息。
(2). 语言之间是有关联的,很多语言之间是同源的,而且很多语言文字之间有着相同的词根。人类语言在日常使用中也经常出现多语种混杂使用的现象。尽管不同语言的资源不均衡,但是将所有语言混合后用于模型训练,不仅能够共享不同语言之间的知识,也可以利用高资源语言的知识帮助提升低资源语言的翻译质量。
(3). 该方法充分发挥了计算机的硬件算力。基于先进的深度学习算法,仅使用一个模型就可以支持几十种、上百种、直至所有语言之间的互译问题。从这个意义上来说,机器已经超越了人类专家的翻译能力,因为即使在吉尼斯世界纪录中,一个人最多可以掌握的语言种类也只有32种,而一个机器模型则可以做到更多。
多语言机器翻译模型是当前非常重要的一个热点研究问题,有望帮助人们实现重建巴别塔的愿望。近年来,微软亚洲研究院机器翻译研究团队开展了多语言机器翻译模型多方位的相关研究,包括模型结构探索、模型预训练方法、参数初始化、微调方法,以及构建大规模模型的方法等等。该团队在机器翻译领域积累了很多研究经验,在以中文为中心的语言翻译任务上取得了丰厚的成果,包括实现东亚语言(如中日韩语言)之间的翻译,中国少数民族语言的翻译,中国方言(如粤语),以及文言文的翻译。相关机器翻译的技术成果也赋能了微软多种跨语言的产品应用,如语音翻译、跨语言检索与跨语言问答等。
在 WMT 2021 比赛中脱颖而出的多语言机器翻译模型 Microsoft ZCode-DeltaLM 是在微软 ZCode 的多任务学习框架下进行训练的。而实现该模型的核心技术则是基于微软亚洲研究院机器翻译研究团队此前打造的能支持上百种语言的多语言预训练模型 DeltaLM。DeltaLM 是微软开发的一系列大规模多语言预训练语言模型中的最新一款。作为一个基于编码器-解码器网络结构的通用预训练生成模型,DeltaLM 可用于许多下游任务(如机器翻译、文档摘要生成、问题生成等),并且都展示出了很好的效果。
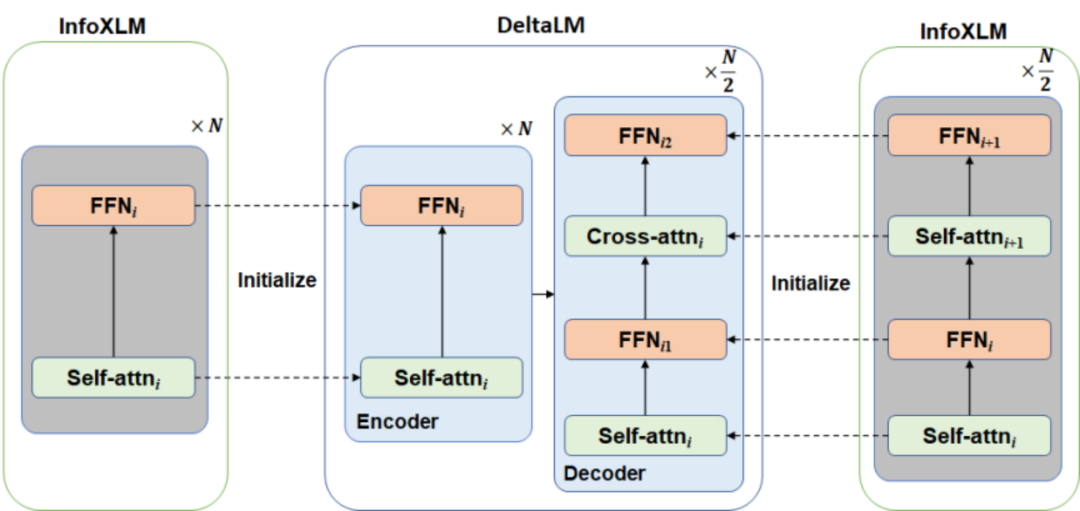
预训练一个语言模型通常需要很长的训练时间,为了提高 DeltaLM 的训练效率和效果,微软亚洲研究院的研究员们并没有从头开始训练模型参数,而是从先前预训练的当前最先进的编码器模型(InfoXLM)来进行参数初始化。虽然初始化编码器很简单,但直接初始化解码器却有一定难度,因为与编码器相比解码器增加了额外的交叉注意力模块。因此,DeltaLM 基于传统的 Transformer 结构进行了部分改动,采用了一种新颖的交错架构来解决这个问题(如下图所示)。研究员们在解码器中的自注意力层和交叉注意力层之间增加了全连接层。具体而言,奇数层的编码器用于初始化解码器的自注意力,偶数层的编码器用于初始化解码器的交叉注意力。通过这种交错的初始化,解码器与编码器的结构匹配,可以与编码器用相同的方式进行参数初始化。
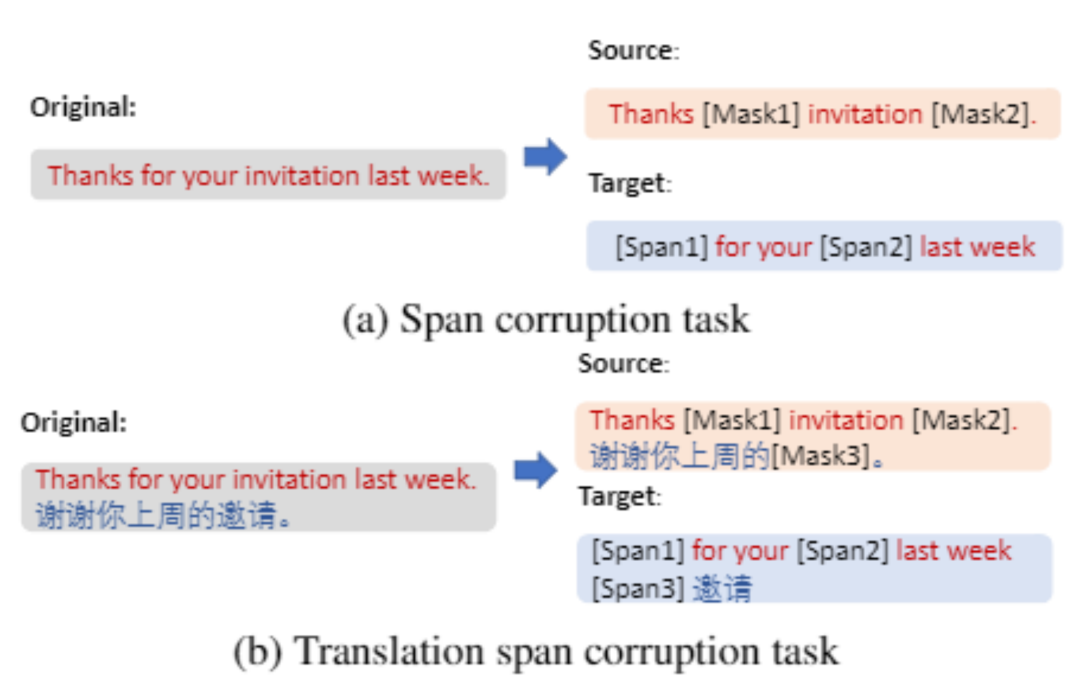
DeltaLM 模型的预训练充分使用了多语言的单语语料和平行语料,它的训练任务是重构单语句子和拼接后的双语句对中随机指定的语块,如下图所示。
在参数微调方面,研究员们将多语言翻译任务视为 DeltaLM 预训练模型的下游任务,使用双语平行数据对其进行了参数微调。不同于其它自然语言处理任务的微调,多语言机器翻译的训练数据规模较大,所以参数微调的成本也非常大。为了提高微调的效率,研究员们采用了渐进式训练方法来对模型进行从浅层到深层的学习。
微调的过程可以分为两个阶段:在第一阶段,研究员们直接在 DeltaLM 模型的24层编码器和12层解码器架构上使用所有可用的多语言语料库进行参数微调。在第二阶段,研究员们将编码器的深度从24层增加到36层,其中编码器的底部24层复用微调后的参数,顶部12层参数随机初始化,然后在此基础上继续使用双语数据进行训练。由于使用了更深的编码器,扩大了模型的容量,考虑到编码器的可并行性,因此新增的编码器层数不会增加太多额外的任务计算时间成本。
此外,微软亚洲研究院的研究员们采用了多种数据增强技术,以解决多语言机器翻译多个方向的数据稀疏问题,进一步提高了多语言模型的翻译性能。研究员们使用了单语语料库和双语语料库在以下三个方面进行了数据增强:
1)为了得到英文到任意语言的反向翻译数据,研究员们使用初始的翻译模型回译英文单语数据以及其它语言的单语数据;
2)为了得到非英文方向的双伪数据,研究员们通过将相同的英文文本分别回译为两种语言进行配对。当这个方向效果足够好的时候,研究员们也将该方向的单语预料进行直接回译来获取伪平行数据;
3)研究员们还使用了中枢语言来进行数据增强。具体而言就是将中枢语言到英文的双语数据进行回译,从而得到目标语言到英文以及中枢语言的三语数据。
面对复杂的数据类型构成(包括平行数据、经过数据增强的反向翻译合成数据和双伪平行数据)以及语种数据规模的非均衡性,研究员们基于动态调整策略,不仅调整数据类型的优先级,同时应用温度采样来平衡不同语言对数据的训练使用次数。比如,在模型微调前期更多侧重于高资源语言翻译的学习,而后期则更加平均地从不同语言数据中学习翻译知识。针对每个语言对的翻译任务,研究员们还根据其开发集上的性能表现决定选择是采用直接翻译策略,还是通过利用英语作为轴语言进行桥接翻译。
基于以上方法,研究员们构建的大规模多语言系统 Microsoft ZCode-DeltaLM 模型,在 WMT 2021 隐藏测试集的官方评测结果超出预期。如下图所示,该模型领先位于第二的竞争对手大约平均4个 BLEU 分数,比基准 M2M-175 模型领先大约10至21的 BLEU 分数。与较大的 M2M-615 模型比较,模型翻译质量也分别领先了10到18 BLEU 分数。
WMT 2021 大规模多语言翻译模型评测结果榜单总结
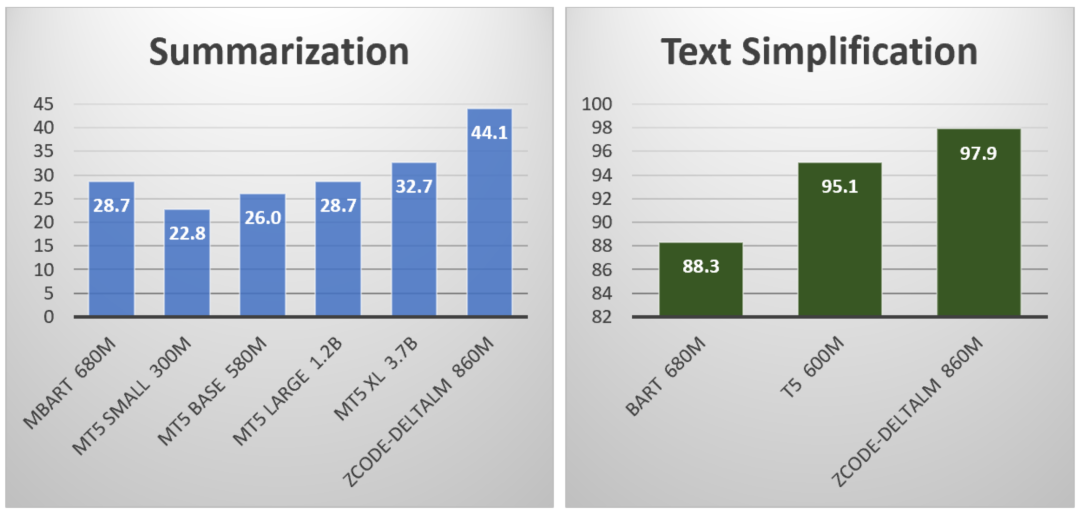
尽管微软的科研人员们对于此次在 WMT 2021 比赛中所取得的成绩倍感兴奋,但更令人激动的是 Microsoft ZCode-DeltaLM 模型不仅仅是一个翻译模型,而是一个通用的预训练编码器-解码器语言模型,可适用于所有类型的自然语言生成任务。Microsoft ZCode-DeltaLM 在 GEM Benchmark 中的许多生成任务上也取得了最佳性能,包括摘要生成(Wikilingua),文本简化(WikiAuto)和结构化数据到文本(WebNLG)等任务。如下图所示,微软 ZCode-DeltaLM 模型的性能表现远优于其他更大参数规模的模型,如37亿参数量的 mT5 XL 模型。
Microsoft ZCode-DeltaLM 模型在 GEM Benchmark 中摘要生成和文本简化任务上的评测结果
微软亚洲研究院已对包括 DeltaLM 在内的多种预训练模型开源,相关资源获取可以访问 https://github.com/microsoft/unilm(点击阅读原文,即可访问)。
展望未来,微软亚洲研究院的研究员们仍将在多语言翻译任务上继续精进,融合更多的数据和知识,在提高翻译性能的同时,不断增强模型能力,使之有效地支持更多低资源和零资源语言翻译,以及自然语言处理领域的其他任务。重建巴别塔的愿景终将实现!
参考资料:
[1] Jian Yang, Shuming Ma, Haoyang Huang, Dongdong Zhang, Li Dong, Shaohan Huang, Alexandre Muzio, Saksham Singhal, Hany Hassan, Xia Song, and Furu Wei. 2021. Multilingual Machine Translation Systems from Microsoft for WMT21 Shared Task. In Proceedings of the Sixth Conference on Machine Translation, Online. Association for Computational Linguistics.
[2] Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, Alexandre Muzio, Saksham Singhal, Hany Hassan Awadalla, Xia Song, Furu Wei. DeltaLM: Encoder-Decoder Pre-training for Language Generation and Translation by Augmenting Pretrained Multilingual Encoders. CoRR abs/2106.13736.
[3]. Yiren Wang, ChengXiang Zhai, Hany Hassan. Multi-task Learning for Multilingual Neural Machine Translation. EMNLP 2020: 1022-1034
[4]. Zewen Chi, Li Dong, Furu Wei, Nan Yang, Saksham Singhal, Wenhui Wang, Xia Song, Xian-Ling Mao, Heyan Huang, Ming Zhou: InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training. NAACL-HLT 2021: 3576-3588
[5]. Guillaume Wenzek, Vishrav Chaudhary, Angela Fan, Sahir Gomez, Naman Goyal, Somya Jain, Douwe Kiela, Tristan Thrush, Francisco Guzmán. Findings of the WMT 2021 Shared Task on Large-Scale Multilingual Machine Translation. In Proceedings of the Sixth Conference on Machine Translation, Online. Association for Computational Linguistics.
![]()