哈工大讯飞联合实验室荣获多语言理解评测XTREME冠军
声明:本文转载自 哈工大讯飞联合实验室 公众号

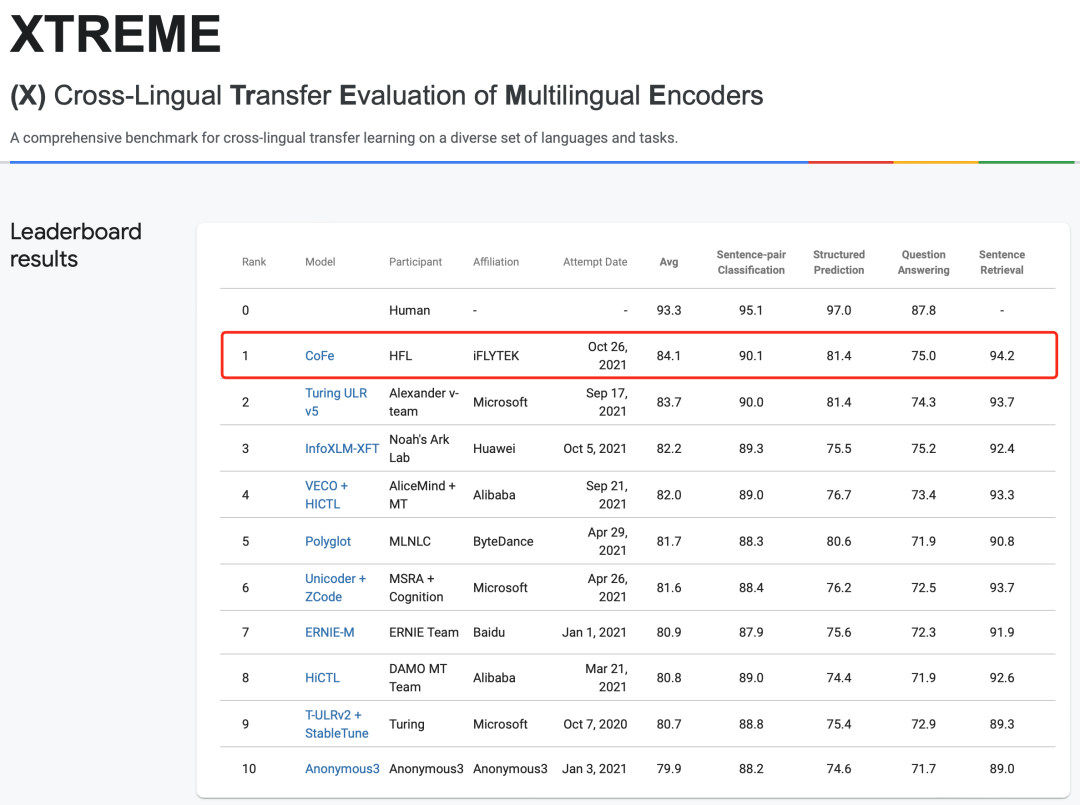
2021年10月26日,哈工大讯飞联合实验室(HFL)团队以总平均分84.1位列权威多语言理解评测XTREME榜首,四个赛道中获得三项最好成绩。XTREME评测(Cross-Lingual Transfer Evaluation of Multilingual Encoders)由谷歌举办,旨在全面考察模型的多语言理解与跨语言迁移能力。该评测覆盖40种语言,包含了句对分类、序列标注、阅读理解、句子检索赛道,共四大类九个任务。XTREME评测举办以来吸引了众多知名高校和研究机构参加,其中包括纽约大学、微软、华为、阿里巴巴、字节跳动、百度等。
XTREME评测
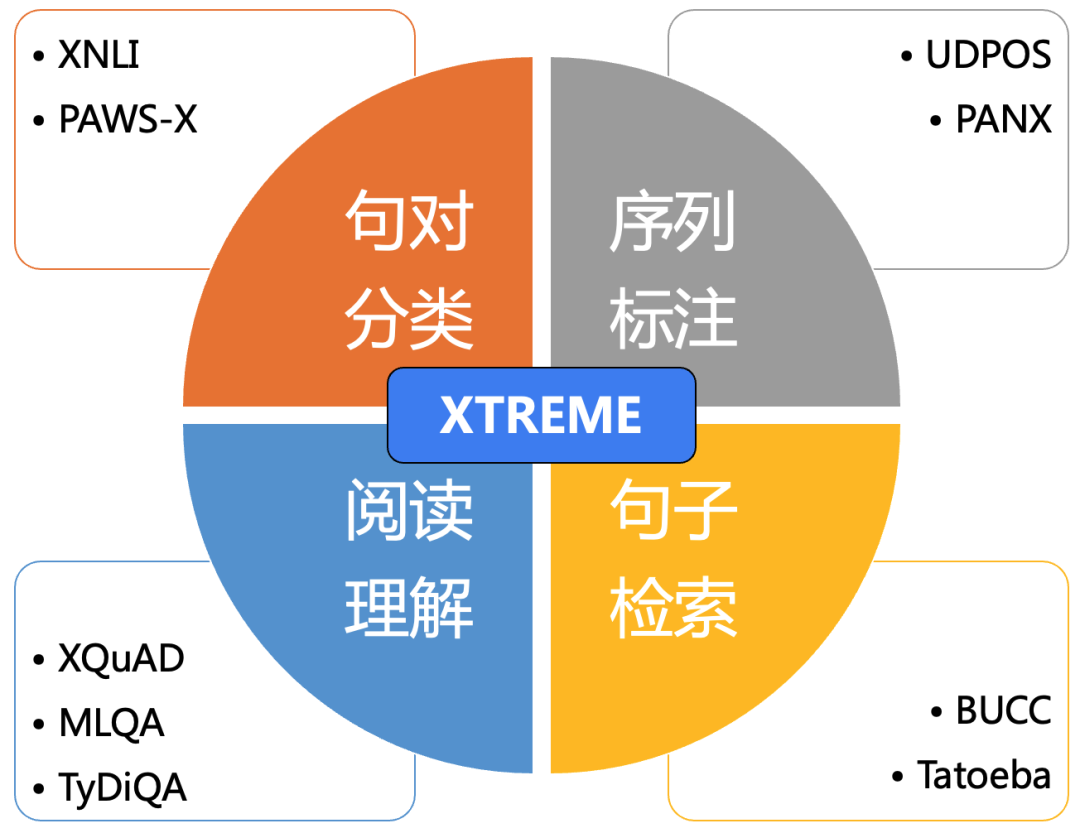
XTREME评测包含4大类9个任务,分别为:
句对分类:XNLI、PAWS-X(自然语言推断)
序列标注:UDPOS(词性标注)、PANX (命名实体识别)
阅读理解:XQuAD、MLQA、TyDiQA(片段抽取型阅读理解)
句子检索:BUCC、Tatoeba(跨语言文本检索)
与以往单语言自然语言理解评测任务不同的是,XTREME中的每一个任务都覆盖了多种语言,评价的是模型在多种语言上的平均指标,因此要求模型具有很好的多语言理解与跨语言迁移能力,而并非只专注于处理单一语言。此外,从任务的多样性也可以看出,XTREME同时评测模型的多种理解能力,而非单一种类任务上的表现。XTREME的总平均分是各个语言、各个任务得分的平均值。若要在XTREME评测上取得总平均分提升,并且从众多顶尖评测队伍中脱颖而出,模型要具备全面的多语言、多任务能力。XTREME评测的难度可想而知,榜单上的模型也代表了多语言模型的顶尖水平,因此获得了众多机构和高校的广泛关注。
夺冠系统
本次哈工大讯飞联合实验室提交的CoFe模型以总成绩84.1分位居XTREME评测榜首,在句对分类、序列标注、句子检索三类任务上也达到或超越了榜单的最优成绩。
本次夺冠的模型CoFe(Cross-lingual Fine-tuning),在多语言预训练模型XLM-R的基础上,加入了自主研发的跨语言对比学习技术,鼓励模型学习不同语言中的语义相似性。此外,我们还借助哈工大讯飞联合实验室推出的知识蒸馏工具TextBrewer,利用知识蒸馏技术进行自监督学习和知识迁移,进一步提升了模型在各个语言上效果的稳定性。为了解决低资源语言学习不充分的问题,CoFe中创新性地融入了细粒度的语言学特征,帮助模型克服训练不足的困难,同时使之适应不同语言的形态学特点。
少数民族语言预训练模型CINO
哈工大讯飞联合实验室不仅在国际比赛中屡获佳绩,也持续关注和积极推动中文相关信息处理技术的研究与发展。目前由于国内少数民族语言语料稀缺、获取难度大等原因,相关技术研究相对匮乏,而主流的的多语言模型也无法很好地处理国内少数民族语言文字。为了促进中国少数民族语言信息处理的研究与发展,哈工大讯飞联合实验室于近期发布了首个面向少数民族语言的多语言预训练模型CINO (Chinese mINOrity pre-trained language model),弥补相关资源的空白,并将相关预训练模型和任务数据开源。
少数民族语言处理是中文信息处理中不可缺少的一环,也是中文信息处理多样性的一种体现。近年来,从国内外自然语言处理重要会议和期刊来看,关于国内少数民族语言的研究正稳步增多,说明越来越多的研究人员意识到少数民族语言处理的重要意义。我们希望随着少数民族语言预训练模型CINO的推出,能够进一步促进少数民族语言相关的技术研究,推动少数民族语言相关技术的应用落地。
关于哈工大讯飞联合实验室(HFL)
哈工大讯飞联合实验室(HFL)是科大讯飞针对“讯飞超脑”项目计划,重点引进和布局的核心研发团队之一,由科大讯飞AI研究院与哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)共同创办。根据联合实验室建设规划,双方将在语言认知计算领域进行长期、深入合作,具体开展阅读理解、预训练模型、人机对话、智能校对、自动阅卷、类人答题等前瞻课题的研究。重点突破深层语义理解、逻辑推理决策、自主学习进化等认知智能关键技术,支撑科大讯飞实现从“能听会说”到“能理解会思考”的技术跨越,并围绕教育、司法、人机交互、智能办公等领域实现科研成果的规模化应用。哈工大讯飞联合实验室成立以来在阅读理解、语法检错、自然语言理解等国际重要评测中荣获十余项冠军。
本期责任编辑:刘 铭
理解语言,认知社会
以中文技术,助民族复兴



