元宇宙中可跨语种交流!Meta 发布新语音模型,支持128种语言无障碍对话

来源:AI科技评论
本文约1630字,建议阅读3分钟
本文介绍了Meta 正式发布的用于各类语音任务的新型自监督模型XLS-R。
语言交流是人类互动一种自然的方式,随着语音技术的发展,我们可以与设备以及未来的虚拟世界进行互动,由此虚拟体验将于我们的现实世界融为一体。
然而,语音技术仅适用于全世界数千种语言中的一小部分。基于有限标记数据的少样本学习,甚至无人监督的语音识别是有帮助的,但这些方法的成功取决于自监督模型的质量。
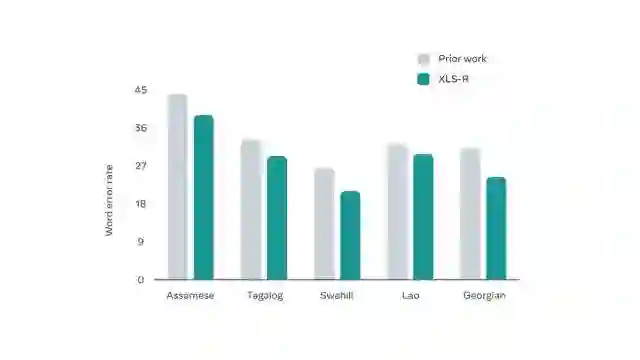
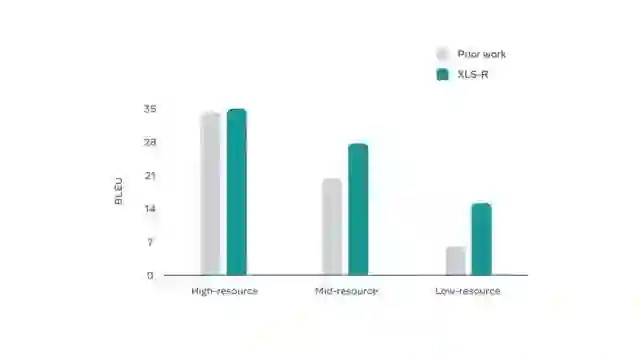
近日,Meta 正式发布 XLS-R ——一套用于各类语音任务的新型自监督模型。XLS-R 由海量公共数据训练而成,能够将传统多语言模型的语言支持量增加两倍以上。
而 XLS-R 作为元宇宙社交中必不可少的一环,可以帮助母语不同的人在元宇宙中直接对话。
为了能够通过单一模型实现对多种语言的理解,Meta 对 XLS-R 进行了微调,使它能够执行语音识别、语音翻译和语言识别等功能。XLS-R 在 BABEL、CommonVoice 以及 VoxPopuli 语音识别基准测试,CoVoST-2 的外语到英文翻译基准测试,以及 VoxLingua107 语言识别基准测试中都有了先进的水平。
为了进一步使这些能够被广泛地访问,Meta 与 Hugging Face 联手发布了模型在 Github 上。
https://huggingface.co/spaces/facebook/XLS-R-2B-22-16

登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
10+阅读 · 2018年5月10日




相关VIP内容
相关资讯