Meta 提出的单个多语言模型,首次超过最佳双语模型,赢得了著名的 WMT 竞赛。
机器翻译(MT)领域的最终目标是构建一个通用的翻译系统,以帮助用户获取信息并更好地相互联系。但是 MT 领域需要解决实际应用中遇到的基本局限性,未来才能更好的使用。
如今,大多数 MT 系统使用双语模型组,这通常需要为每个语言对和任务提供大量标记示例。不幸的是,这种方法对于训练数据很少的语言(例如冰岛语、豪萨语)来说失败了。双语模型组的高度复杂性使得它无法扩展到大型实际应用程序中,因为每天有数十亿人用数百种语言发布信息。
为了构建通用翻译器,来自 Meta 的研究者认为 MT 领域应该从双语模型转向多语言翻译(Multilingual translation)——多语言模型即一个模型可以同时翻译许多语言对,包括对低资源语言对(例如,冰岛语到英语的翻译)和高资源语言对(例如,英语到德语的翻译)的翻译。
![]()
由于多语言翻译更简单、更容易扩展、并且更适合低资源语言等特点,更容易受到研究者的青睐。但直到现在,多语言翻译无法为高资源语言对提供与双语模型(经过特殊训练的)一样好的结果。因此,提供跨多种语言的高质量翻译通常涉及使用单个双语模型的组合,而对于低资源语言来说,实现还比较困难。
现在,Meta 的研究取得了突破性的进展:首次单一的多语言模型在 14 个语言对中有 10 个超过了经过特别训练的最好的双语模型,赢得了 WMT(一个著名的 MT 比赛)比赛。该单一多语言模型为低资源和高资源语言提供了最佳翻译,表明多语言方法确实是 MT 的未来。
Yann LeCun 在推特上对这一研究进行了宣传:
![]()
这项研究建立在先前研究之上,提高了低资源语言的翻译质量。然而,当添加具有各种资源的语言时,随着更多语言的添加,一种模型将变得不堪重负,因为每种语言都具有独特的语言属性、脚本和词汇。当高资源语言受益于大型多语言模型时,对低资源语言对来说有过拟合的风险。
![]()
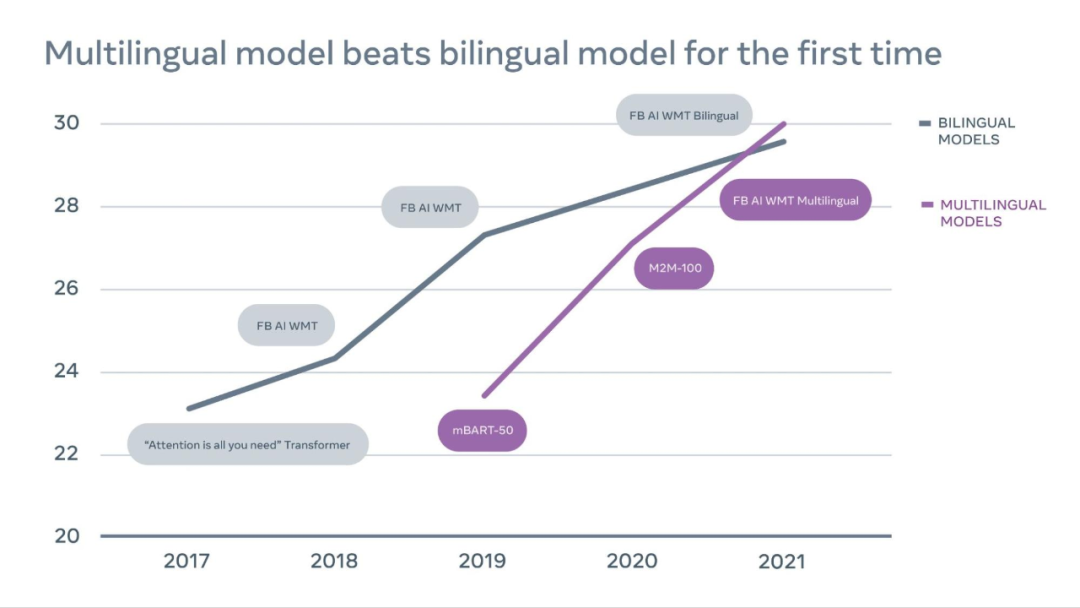
上图为 2017-2021 年 WMT 竞赛时间表,表中展示了英语到德语翻译的性能质量随时间的进展,由结果可得多语言模型现已超过了双语模型。其中 En-De(English to German) 被公认为最具竞争力的翻译方向。
Meta 的多语言模型是 MT 中一个激动人心的转折点,因为它表明——通过大规模数据挖掘、扩展模型容量和更高效的基础设施方面的新进展——多语言模型有可能在高资源和低资源任务上实现更好的性能。这一技术使研究者更接近于构建一个通用翻译器。
![]()
为了训练 WMT 2021 模型,研究者构建了两个多语言系统:任何语言到英语(any-to-English) 和英语到任何语言(English-to-any),方法采用并行数据挖掘技术。
![]()
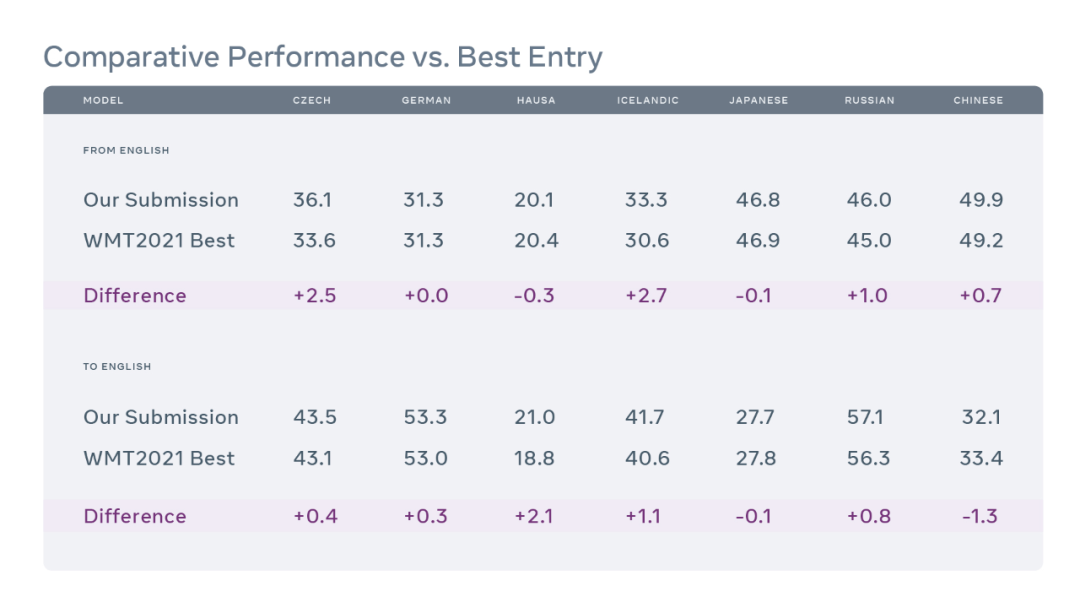
Meta 提出的模型与提交给 WMT '21 的最佳模型的性能比较。图中数据为 WMT'21 测试集的 BLEU 得分。
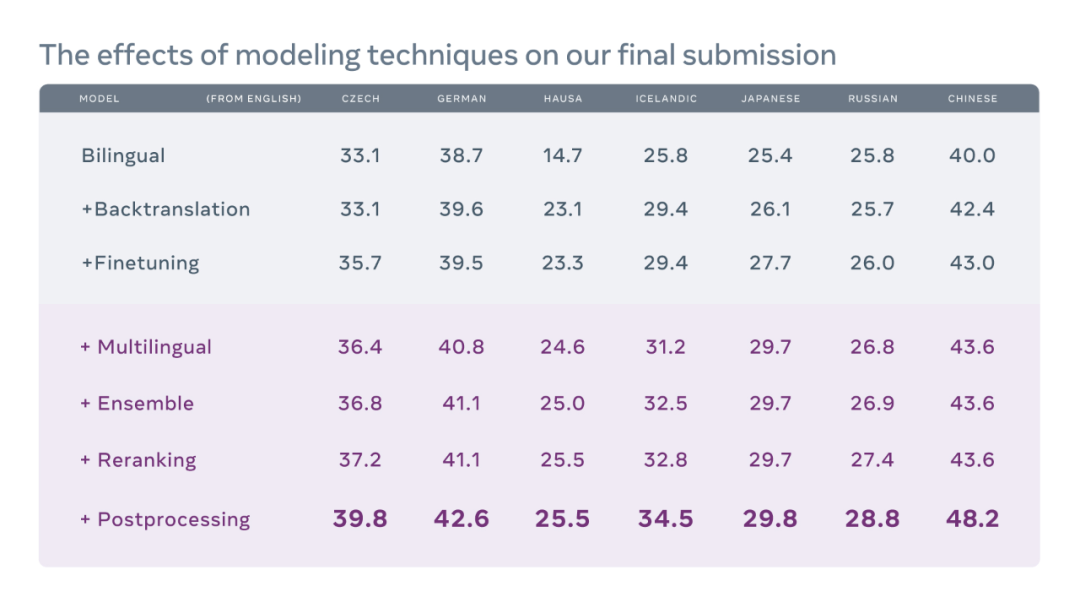
由于任何语言的单语数据量远远超过并行数据量,因此 Meta 利用可用的单语数据来最大化 MT 系统的性能至关重要。回译(back- translation)是单语数据最常见的技术之一,Meta 采用这一技术赢得了 2018 年和 2019 年 WMT 英语对德语新闻翻译任务。在本次研究中,Meta 添加了包含来自所有八种语言的数亿个句子的大规模单语数据。并且过滤了可用的单语数据以减少噪声量,然后使用可用的最强多语言模型对它们进行回译。
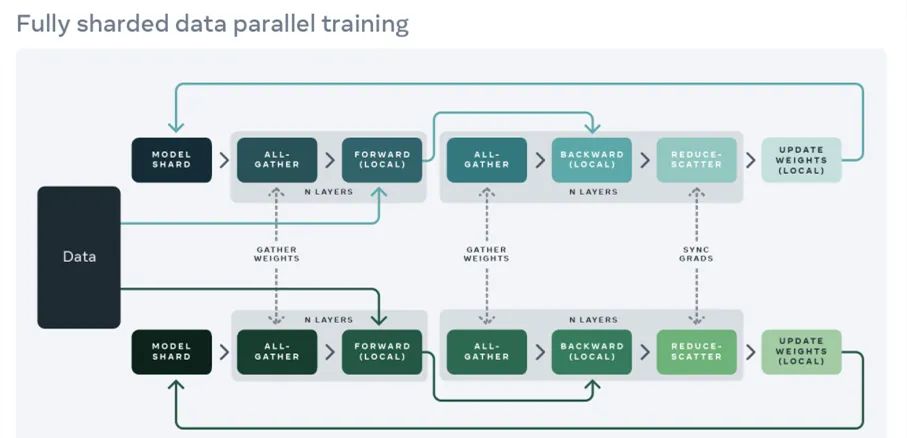
除了通过回译扩展数据大小之外,Meta 还将模型大小从 150 亿参数扩展至 520 亿参数,以增加多语言模型架构的容量。但是如果没有 Meta 六月推出的名为「Fully Sharded Data Parallel」的 GPU 内存节省工具,所有这些扩展工作都不可能实现。该工具使得大规模训练的速度是以往方法的 5 倍。
![]()
Fully Sharded Data Parallel(FSDP)。
由于多语言模型自身就有竞逐容量的属性,因此它们必须在共享参数和不同语言的专门化之间取得平衡。按照比例扩展模型大小导致计算成本无法支撑。
![]()
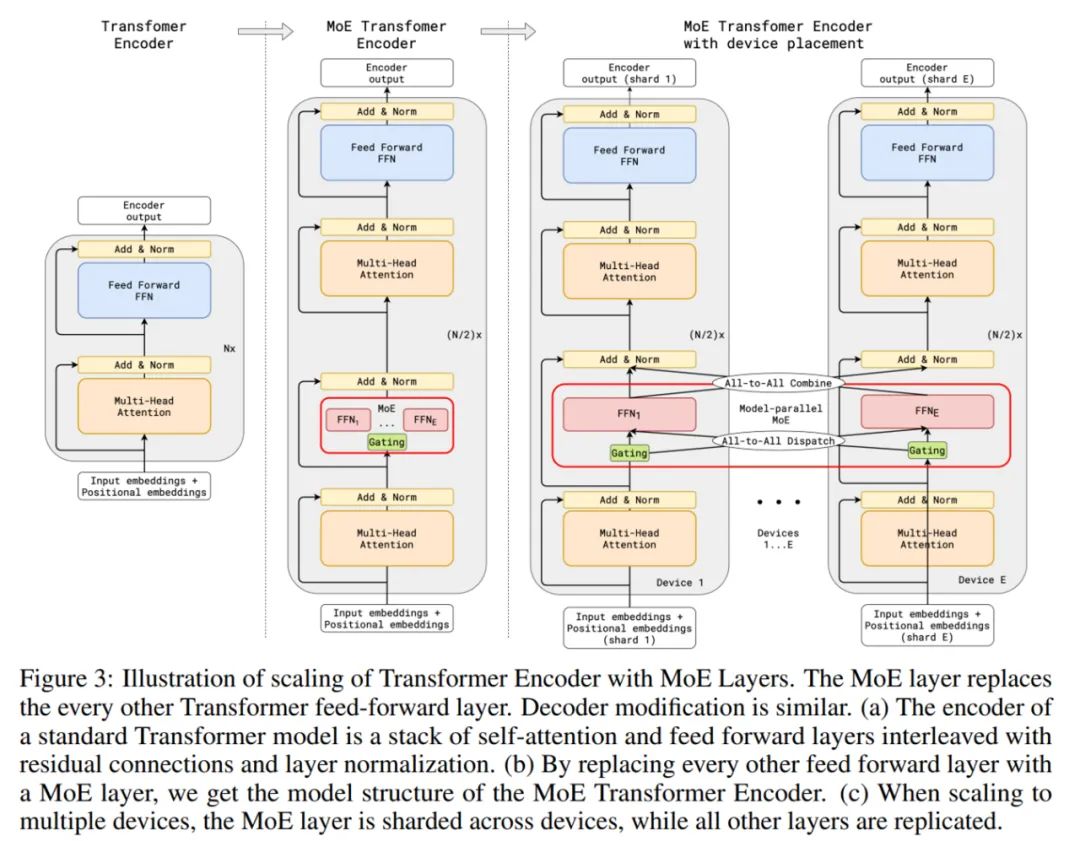
Meta 使用了一种替代方案来利用条件式计算方法,该方法仅为每个训练示例激活模型的一个子集。具体来说,Meta 训练了稀疏门混合专家(Sparsely Gated Mixture-of-Expert)模型,每个 token 基于学习到的门函数馈入到 top-k 个专家前馈(FeedForward)块。他们使用 Transformer 架构,其中每个 alternate Transformer 层中的前馈块都替换成稀疏门混合专家层,后者在编解码器中有 top-2 个门。因此,每个输入序列仅使用所有模型参数的一个子集。
![]()
具有混合专家层的 Transformer 编码器的扩展。
这些模型既可以允许在高资源方向从增加的专家模型容量中受益,也能够通过共享模型容量迁移至低资源方向。
Meta 相信,他们在 WMT 2021 上取得的成绩巩固了多语言翻译作为构建单一通用翻译系统的重要途径。他们还证明了,对于高资源和低资源语言,单个多语言模型可以提供较双语模型更高的翻译质量,并且更易于针对「新闻文章翻译」等特定任务进行微调。
这种「单个模型适用多种语言」的方法可以简化现实世界应用中翻译系统的开发,还有可能实现用一个模型替换数千个模型,从而为世界上的每个人带来新的应用和服务。
https://ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
第一期:快速搭建基于Python和NVIDIA TAO Toolkit的深度学习训练环境
英伟达 AI 框架 TAO(Train, Adapt, and optimization)提供了一种更快、更简单的方法来加速培训,并快速创建高度精确、高性能、领域特定的人工智能模型。
11月15日19:30-21:00,英伟达专家带来线上分享,
将介绍:
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com