微软翻译突破百种语言和方言大关


(本文阅读时间:8分钟)

近日,微软 Azure 认知服务翻译的语言列表又添加了12种全新的语种和方言,微软翻译可以提供翻译支持的语言总数已达103种!
新增语言的母语使用者合计达8,460万人,包括巴什基尔语、迪维希语、格鲁吉亚语、吉尔吉斯语、马其顿语、蒙古语(西里尔文字)、蒙古语(传统文字)、鞑靼语、藏语、土库曼语、维吾尔语和乌兹别克语(拉丁文字)。微软亚洲研究院为其中的七种语言和方言——迪维希语、蒙古语(西里尔文字)、蒙古语(传统文字)、藏语、土库曼语、维吾尔语和乌兹别克语(拉丁文字),提供了核心技术支持。目前最新版的微软翻译可以在全球56.6亿人所使用的不同母语之间实现文本文档的互译。

微软翻译的核心使命是打破人与人之间的文化和语言障碍。为实现这一目标,微软的研究员们不断为这项服务增添新的语种和方言,同时确保所支持语言的机器翻译达到并超过我们设置的高质量标准。
微软研究院在20多年前首次开发出了机器翻译系统。2003年,该机器翻译系统将整个微软知识库(Microsoft Knowledge Base)从英文翻译成了西班牙文、法文、德文、日文,并在微软网站上发布了译文版,使之成为当时互联网上规模最大、面向公众开放的初始机器翻译应用。
此后,微软以统计机器翻译(SMT)模型为基础,对系统做了进一步改良,并通过 Windows Live Translator、Translator API 以及作为微软 Office 应用程序的内置功能,向用户提供翻译服务。
多年来,微软已将世界上诸多常用的语言和方言添加到了微软翻译的系统中。而随着人工智能技术的发展,微软研究院开始采用神经机器翻译(NMT)技术,将所有机器翻译系统迁移到了基于 Transformer 架构的神经模型上,因此翻译的流畅度和准确性获得了大幅提升。
引入 Transformer 架构的 NMT 技术,不仅可以利用包括单语语料数据在内的更多数据来训练超大模型,提升翻译的整体质量,也为构建机器翻译模型开辟了新的路径,让模型可以借助比先前更少的数据来进行训练。多语言的 Transformer 架构可以利用来自其他语言(通常属于相同或相关的语系)的资料扩充训练数据,为低资源语言构建翻译模型。
当全部技术都已准备就绪的同时,机器翻译系统还必须要有一套数字化的并行文档,其中包括目标语言版本的文档,以及另一种已纳入翻译服务的语言的翻译版文档。但对于很多小语种来说,这些并行文档中的平行语料很难获得。幸运的是,微软通过与语言社区的合作伙伴展开合作,可以获取人工翻译的文本,收集低资源语言的数据。这些社区伙伴通常是在各自社区任职的志愿者,他们通过咨询社区成员和长者,不辞劳苦地收集双语词句。与社区合作伙伴的接触始于2010年,当时微软与社区负责灾难响应的人员合作,在海地发生毁灭性地震后短短10天内,就为海地克里奥尔语构建了一个翻译系统。从那时起,越来越多的社区伙伴加入了社群,帮助微软创建了多个语言系统,例如苗族语、乌尔都语、玛雅语、毛利语和因纽特语等等。
尽管如此,缺少足够的平行语料依然是小语种语言翻译的最大难点。多年来,微软亚洲研究院承担了多个小语种语言和方言的模型构建工作,将新技术融入其中,帮助解决语料问题。微软亚洲研究院首席研究员秦涛表示,“基于源语言和目标语言的平行语料及单语语料,我们在训练阶段将多语言模型与 MASS 预训练模型相结合,同时再利用相关大语种的丰富语料及单语语料来提升模型的翻译质量。”
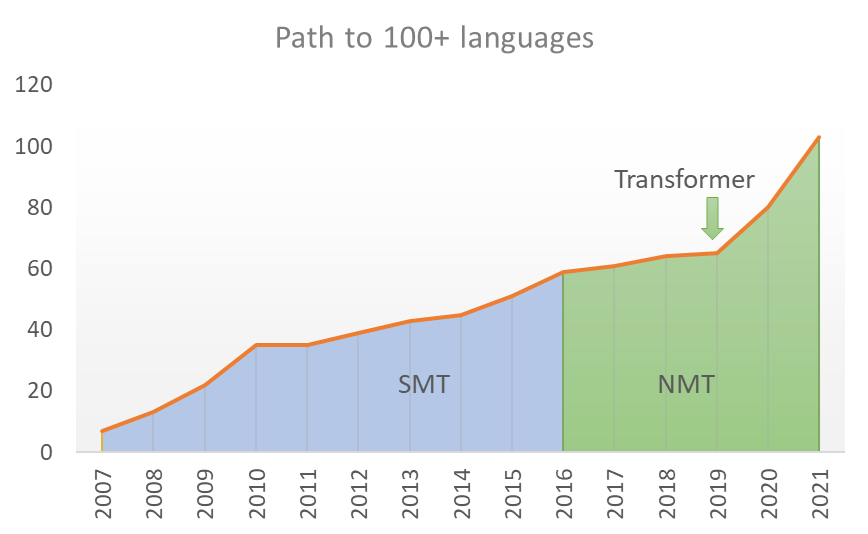
图 1:2016年,微软利用神经机器翻译(NMT)技术提高了翻译质量,2019年,微软采用 Transformer 架构为低资源语言构建了模型
Azure 认知服务中的翻译工具由微软翻译提供支持,旨在帮助企业扩大其全球影响力,让他们能够快速、可靠并以合理的成本跨越语言障碍,用客户的母语与之进行合作、交流并提供内容服务。当然,这项服务还能帮助企业内部来自不同国家的员工在沟通时打破语言障碍。
Azure 认知服务翻译工具将 NMT 模型纳入微软产品中,通过文本翻译和文档翻译 API,为用户提供服务,将纯文本和复杂的文档从一种语言翻译成另一种语言。Azure 认知服务翻译工具还包含自定义翻译服务,该服务允许用户使用自备翻译存储器构建自定义的机器翻译模型,用于翻译他们在各自业务及相关领域中所使用的特定术语。用户可以通过文本和文档翻译 API 使用这些自定义机器翻译模型。为了实现音频或语音内容的翻译,Azure 认知服务的翻译工具和语音工具紧密集成,并通过 Azure 语音 SDK 为语音翻译和多设备对话提供支持。
Azure 认知服务翻译工具及其支持的产品被用户广泛采用,用于网站内容和 App 的本地化、为业务分析的对话和内容及法证调查的内容提供翻译等诸多应用场景。该服务还无缝集成到微软的许多产品中,每个人都可以随时通过他们所选择的语言来使用和创建内容。集成了翻译服务的微软产品包括 Microsoft 365 中的文本和文档翻译、微软 Edge 浏览器中的网页翻译、SwiftKey 中的消息翻译、LinkedIn 中的用户提交内容翻译、微软翻译 App 中的多语言对话翻译等等。
如果一个人并不能掌握承载特定信息的语言,那么技术如何才能帮助他获取信息呢?在一个不断缩小的世界中,人们又将如何更了解和欣赏彼此的文化?语言障碍阻碍了人们获取某些重要信息,而这也是促使微软致力于打破这些障碍的动因之一。将文本、文档、语音和图像从一种语言翻译成另一种语言,将为实现这一目标发挥重要作用。
微软亚洲研究院高级研究员张冬冬认为,“语言作为文化的载体,其翻译任务一方面促进了各种文化的交流,另一方面也在保护、复原那些正在消失或已经消失的语言中所蕴含的人类知识、智慧文明。我们除了不断提升主流语言机器翻译质量让其接近人工翻译水平外,同时也在考虑低资源和零资源语言的翻译问题。机器翻译技术是解决跨国家、跨地区、跨民族无障碍交流、文化传承等问题的重要手段。”
事实上,当翻译语言覆盖面达到世界语言总数的百分之一时,微软就已经为全球72%的人口打破了语言障碍。微软的科研和技术人员在感到自豪的同时,也将以谦卑的态度继续语言翻译的探索与研究。未来,微软将继续满怀激情地改进服务和解决方案,提升质量,让每个人都能获取来自世界各地的内容,消除语言差异带来的分歧,同时保持对文化、传统和归属感的尊重。
你也许还想看:








