解决Transformer固有缺陷:复旦大学等提出线性复杂度SOFT
来自复旦大学、萨里大学和华为诺亚方舟实验室的研究者首次提出一种无 softmax Transformer。
视觉 Transformer (ViT) 借助 patch-wise 图像标记化和自注意力机制已经在各种视觉识别任务上实现了 SOTA。然而,自注意力模块的使用使得 Transformer 类模型的空间和时间复杂度都是 O(n^2)。自然语言处理领域的研究者们已经进行了各种让 self-attention 计算逼近线性复杂度的尝试。
近日,来自复旦大学、萨里大学和华为诺亚方舟实验室的研究者在一项研究中经过深入分析表明,这些尝试要么在理论上存在缺陷,要么在实验中对视觉识别无效,并进一步发现这些方法的局限性在于在近似过程中仍然保持 softmax 自注意力。具体来说,传统的自注意力是通过对标记特征向量之间的缩放点积(scaled dot-product)进行归一化来计算的。保持这种 softmax 操作阻碍了线性化 Transformer 的复杂度。基于此,该研究首次提出了一种无 softmax Transformer(softmax-free transformer,SOFT)。
为了去除 self-attention 中的 softmax,使用高斯核函数(Gaussian kernel function)代替点积相似度,无需进一步归一化。这使得可以通过低秩矩阵分解来近似一个完整的自注意力矩阵。通过使用 Newton-Raphson 方法计算其 Moore-Penrose 逆来实现近似的稳健性。ImageNet 上的大量实验表明,SOFT 显着提高了现有 ViT 变体的计算效率。至关重要的是,对于线性复杂性,SOFT 中允许更长的 token 序列,从而在准确性和复杂性之间实现卓越的权衡。

论文地址:https://arxiv.org/abs/2110.11945
项目地址:https://github.com/fudan-zvg/SOFT
Transformer 模型存在一个瓶颈,即计算和内存使用的二次复杂度。这是自注意力机制的内在特征:给定一系列 token(例如,单词或图像块)作为输入,自注意力模块通过将一个 token 与所有其他 token 相关联来迭代地学习特征表示。这导致计算(时间)和内存(空间)中 token 序列长度为 n 的二次复杂度 O(n 2 ),因为在推理过程中需要计算和保存 n × n 大小的注意力矩阵。这个问题在视觉中尤为严重:即使空间分辨率适中,在 tokenization 的 2D 图像也会产生比 NLP 中的序列长得多的序列。因此,这种二次复杂性阻止了 ViT 模型以高空间分辨率对图像进行建模,这对于视觉识别任务通常是至关重要的。
一种自然的解决方案是通过近似来降低自注意力计算的复杂性。事实上,在 NLP 中已经有很多尝试 [33, 5, 18, 38]。例如,[33] 采取了一种天真的方法,通过可学习的预测来缩短 Key 和 Value 的长度。这种粗略的近似将不可避免地导致性能下降。相比之下,[5, 17] 都利用内核机制来近似 softmax 归一化,以线性化自注意力中的计算。[18] 取而代之的是采用散列策略来选择性地计算最相似的对。最近,[38] 使用 Nyström 矩阵分解通过多项式迭代重建完整的注意力矩阵,以逼近地标矩阵的伪逆。
尽管如此,softmax 归一化在矩阵分解过程中只是简单地重复,这在理论上是不可靠的。该研究通过实验发现,当应用于视觉时,这些方法都不是有效的(参见第 4.2 节)。该研究发现现有高效 Transformer 的局限性是由使用 softmax self-attention 引起的,并首次提出了一种无 softmax 的 Transformer。更具体地说,在所有现有的 Transformer(有或没有线性化)中,在 token 特征向量之间的缩放点积之上需要一个 softmax 归一化。保持这种 softmax 操作挑战任何后续的线性化工作。
为了克服这个障碍,该研究提出了一种新的无 softmax 的自注意力机制,命名为 SOFT,在空间和时间上具有线性复杂度 O(n)。具体来说,SOFT 使用 Gaussian kernel 来定义相似度(self-attention)函数,不需要后续的 softmax 归一化。有了这个 softmax-free 注意力矩阵,该研究进一步引入了一种新的低秩矩阵分解算法来逼近。通过采用 Newton-Raphson 方法可靠地计算矩阵的 Moore-Penrose 逆,理论上可以保证近似的稳健性。
该研究的主要贡献包括:
提出了一种具有线性空间和时间复杂度的新型 softmax-free Transformer;
该研究的注意力矩阵近似是通过一种具有理论保证的新型矩阵分解算法来实现的;
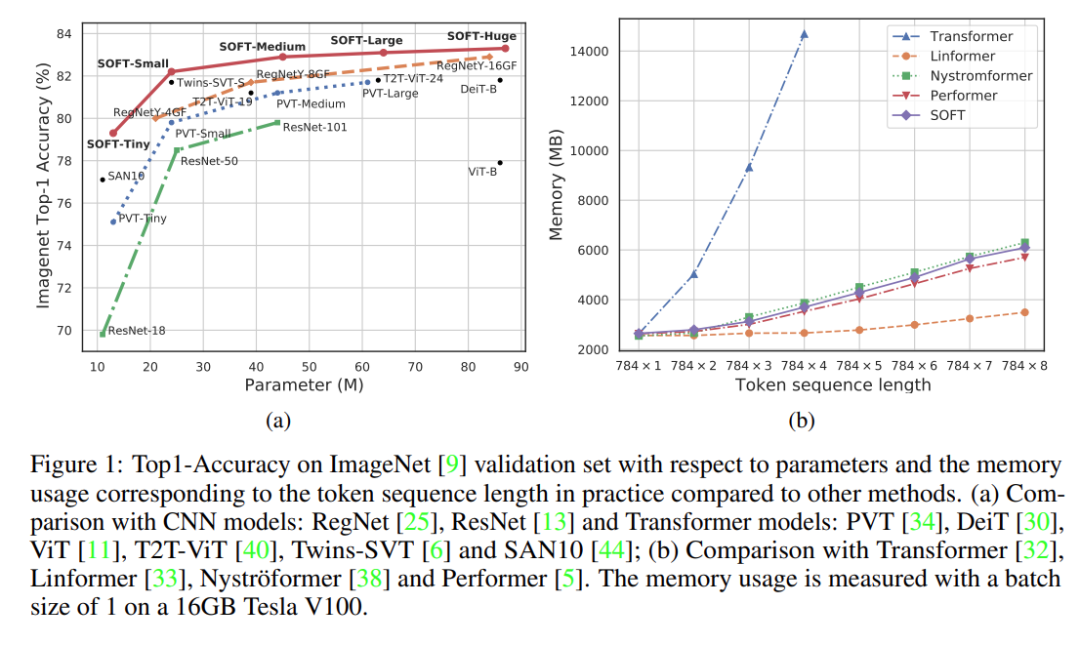
为了评估该方法在视觉识别任务上的性能,该研究使用 SOFT 作为核心自注意力组件设计了一系列具有不同能力的通用骨干架构。大量实验表明,具有线性复杂性(图 1b),SOFT 模型可以将更长的图像 token 序列作为输入。因此,在模型大小相同的情况下,SOFT 在准确度 / 复杂度权衡方面优于 ImageNet [9] 分类上最先进的 CNN 和 ViT 变体(图 1a)。
下图 2 给出了该模型的示意图。
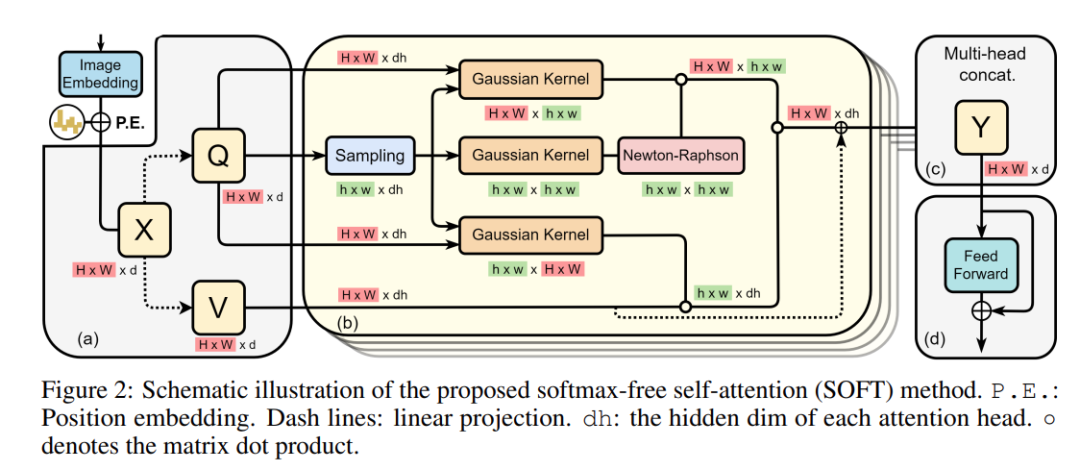
图 2:所提出的无 softmax 自注意力 (SOFT) 方法的示意图。P.E.:位置嵌入。虚线:线性投影。dh:每个注意力头的隐藏暗淡。◦ 表示矩阵点积。
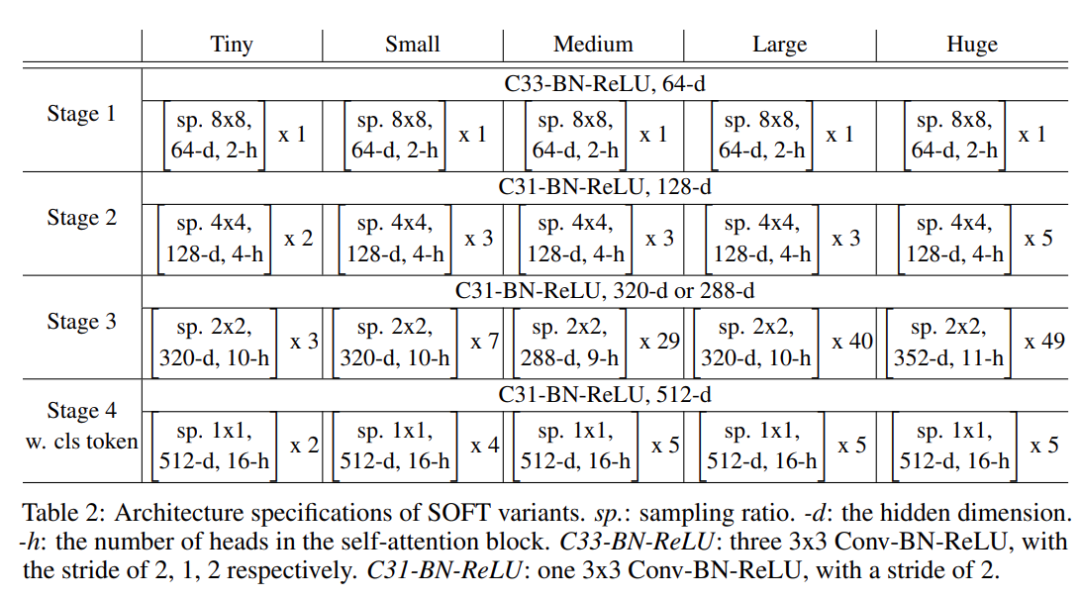
作者采用了两个实验设置。在第一个设置下,对于所有方法,该研究使用相同的 Tiny(表 2)架构进行公平比较。也就是说,用每个基线自己的注意力块替换 SOFT 中的核心自注意力块,而架构的其余部分保持不变。请注意,[35] 的空间缩减模块是 Linformer [34] 的特例。研究者将减速比设置为与该方法相同。使用相同的统一采样思想,该研究将 Nyströmformer(用于 NLP 任务)的 1D 窗口平均替换为 2D 平均池化(用于图像)。下采样率与该研究的方法的保持一致。还值得一提的是,Reformer [19] 没有官方代码发布,本地敏感哈希(LSH)模块对输入 token 的长度有严格的要求,因此该研究的比较中不包括这种方法。
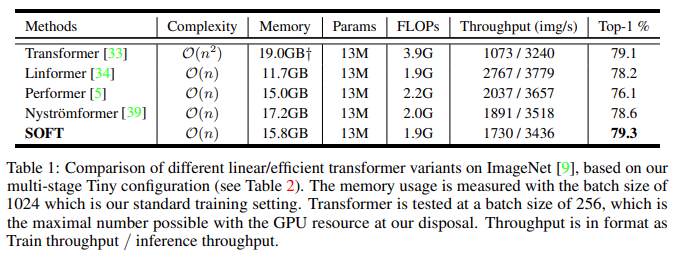
从下表 1 可以观察到:
与 Tiny 架构上的 Transformer 相比,Linear Transformer 方法大大减少了内存和 FLOP,同时保持了相似的参数大小;
SOFT 方法在所有线性化方法中实现了最好的分类精度;
该方法的推理速度与其他线性 Transformer 相当,训练速度比 Nystromformer 稍慢,并且都比 Performer 和 Linformer 慢。
研究者指出:该模型的训练速度缓慢主要是由于 Newton-Raphson 迭代,它只能按顺序应用以确保 Moore-Penrose 逆的准确性。总之,由于同等的推理速度,研究者认为训练成本的增加是值得为卓越的准确性付出的代价。
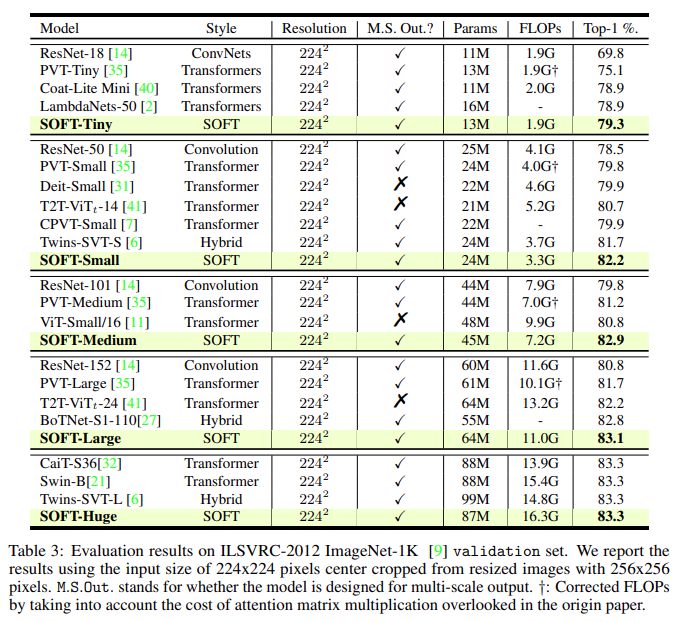
该研究与最先进的替代方案进行比较,并报告 ImageNet-1K 验证集上的 top-1 准确率。FLOP 的计算批大小为 1024。从图 1a 和表 3 中得出以下观察结果:(i) 总体而言,ViT 及其变体比 CNN 产生更好的分类准确度。(ii) 该研究在最近基于纯视觉 Transformer 的方法中取得了最佳性能,包括 ViT [11] 和 DeiT [31],以及最先进的 CNN RegNet [26]。(iii)SOFT 在所有变体中都优于最相似的(在架构配置中)Transformer 对应物 PVT [35]。由于注意力模块是主要区别,这直接验证了该模型的有效性。(iv) 该方法还击败了旨在解决 ViT 效率限制的最新 ViT 变体 Twins,并且所需的参数和浮点计算都更少。
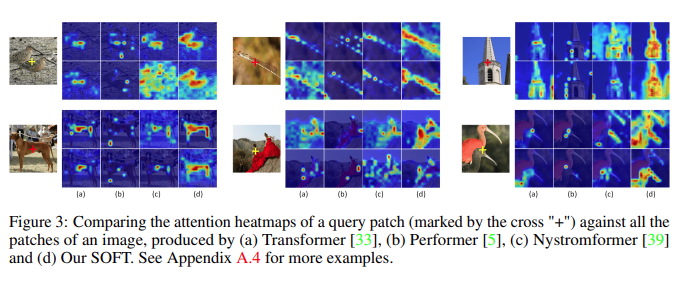
为了深入了解如何使用 SOFT 及替代方法学习注意力,图 3 显示了各种比较模型的注意力掩码。对于每个模型,论文中给出了前两个注意力头的输出。很明显,SOFT 在捕捉像素之间的局部和长距离关系方面表现出鲁棒性和多功能性。有趣的是,尽管 SOFT 在 ImageNet [9] 中的对象分类数据集上进行了训练,但它似乎能够学习同一类别中的实例之间共享的语义概念和实例特定的特征。
感兴趣的读者可以阅读论文原文,了解更多研究细节。
基于Python,利用 NVIDIA TAO Toolkit 和 Deepstream 快速搭建车辆信息识别系统
DeepStream是一个用于构建人工智能应用的流媒体分析工具包。它采用流式数据作为输入,并使用人工智能和计算机视觉理解环境,将像素转换为数据。
DeepStream SDK可用于构建视觉应用解决方案,用于智能城市中的交通和行人理解、医院中的健康和安全监控、零售中的自助检验和分析、制造厂中的组件缺陷检测等
12月14日19:30-21:00,本次分享摘要如下:
介绍 TAO Toolkit 的最新特性;
介绍 NVIDIA Deepstream 的最新特性;
利用 TAO Toolkit 丰富的预训练模型库,快速训练模型;
直接利用 TAO Toolkit 的预训练模型和 Deepstream 部署应用;


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


