南开&阿里联合提出P2T:基于金字塔池化的视觉Transformer!

极市导读
本文提出了基于金字塔池化的视觉 Transformer,第一次将金字塔池化思想引入到视觉 Transformer 中,并将其应用于下游场景理解任务。 金字塔池化可以自然地解决MHSA序列长度过长的问题,也可以高效地捕捉上下文和结构信息。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2106.12011
代码链接:https://github.com/yuhuan-wu/P2T
目前,现有的视觉Transformer中的两大问题:
1. 传统的 Multi-Head Self-Attention (MHSA) 需要大量的计算、空间资源。
2. 最近新提出的视觉 Transformer 在图像分类中被过度地开发和调整,却忽视了图像分类(单一场景,与MLP较为相似)和各类下游场景理解任务(复杂场景,丰富结构和内容信息)的区别。
为了解决以上两大问题,研究人员提出了基于金字塔池化的视觉 Transformer,第一次将金字塔池化思想引入到视觉 Transformer 中,从而减少使用传统 MHSA 带来的过高计算量和存储空间(问题1)。此外,研究人员注意到 Pyramid Pooling 因其强大的抽象上下文能力在各类下游视觉任务上的表现都十分出色,且其空间不变性的自然属性适合解决结构信息的丢失问题(问题2)。
一、Introduction
过去十年从 AlexNet 开始,卷积神经网络(CNN)在计算机视觉各类任务上都大放异彩,绝大部分的新 SOTA 都采用了 CNN 作为基础架构。而最近在自然语言处理领域,Transformer技术逐步替代CNN作为主要技术。Transformer的主要依赖其自注意力(self-attention)机制,从而获取长距离的全局注意力信息。因为Transformer 的成功点主要在于其获取全局信息的能力,而全局信息在计算机视觉领域也同样十分重要,将 Transformer 迁移至视觉领域也能够克服传统CNN需要叠加多个层才能获取更大感受野的缺陷。
最近,Dosovitskiy 等人[1]第一次将纯粹的视觉 Transformer 用于图像分类中,并取得了与 CNN 相比十分有竞争力的效果。随后,在极短的时间内,大量的研究者试图去改进 Dosovitskiy 等人提出的视觉 Transformer 方法,并取得了比CNN更好的效果。
然而,视觉 Transformer 方法仍然有两点巨大的问题。
1) 一个问题是自注意力机制中序列的长度。视觉 Transformer 中序列的长度往往远大于自然图像处理中的序列长度。过长的序列长度会导致多头自注意力机制(MHSA)过大的自注意力计算量和计算空间。为了解决这一问题,PVT方法[2]直接将输入进 Transformer 的特征图作下采样从而避免MHSA带来的过大计算量和计算空间。然而这种做法会导致它实际是 token-to-region 的建模,而非 token-to-token 的建模。Swin方法[3]将计算整个特征图的注意力转变为在特征图的每个小窗口中计算。它使用一种 window shift 的策略去逐渐地增大网络的感受野,即通过叠加多个层来增加感受野。这类策略的问题在于它仍然沿用的 CNN 的策略。研究者们用 Transformer 替代 CNN 的初衷在于 Transformer 能够对特征进行直接的全局关系建模。
2) 另一问题是计算机视觉与自然语言处理的域间隙(domain gap)。 在计算机视觉中,研究人员一般是对图像进行处理,而图像一般是一种自然的2D结构,而在自然语言处理中一般是处理 1D 的句子序列。对于1D的句子序列,研究人员只需要考虑序列的先后顺序,利用 Positional Encoding 就可以简单地解决该问题。然而大部分视觉transformer只是针对 ImageNet 分类进行改进而不考虑这个问题。ImageNet 中的图像仅具有简单的上下文信息,例如,相同类的某些对象以图像为中心。一个简单的 Position Embedding 就可以处理这种简单的情况。但显然对复杂的真实情景,特别是对于需要像素级图像理解的密集预测任务来说,这种方式是次优的。因此,研究人员认为目前 Transformer 网络的先前在图像分类取得结果不能代表其在下游视觉任务中的性能。目前也迫切需要一个下游任务导向的Transformer 来弥合计算机视觉和自然语言处理之间的域间隙。
研究人员注意到金字塔池化 (Pyramid Pooling) 是一种建模深度特征图长距离特征关系的有效手段。 具体而言,金字塔池化对给定的特征图使用具有不同感受野、步长的池化操作。这种技术已经在各类场景理解的视觉任务应用,比如语义分割、物体检测、视觉显著性、图像超分辨率、立体匹配、去雨、去噪等视觉任务。利用金字塔池化技术改进现有的视觉 Transformer 可以自然地解决视觉 Transformer 中序列过长的问题。而且金字塔池化技术利用多核池化操作和金字塔的空间不变性可以自然地捕获多尺度长距离的上下文信息和2D结构。
基于以上观察,研究人员提出了金字塔池化 Transformer (Pyramid Pooling Transformer, P2T),并将其应用于下游场景理解任务。 金字塔池化可以自然地解决MHSA序列长度过长的问题,也可以高效地捕捉上下文和结构信息。
二、Methodology
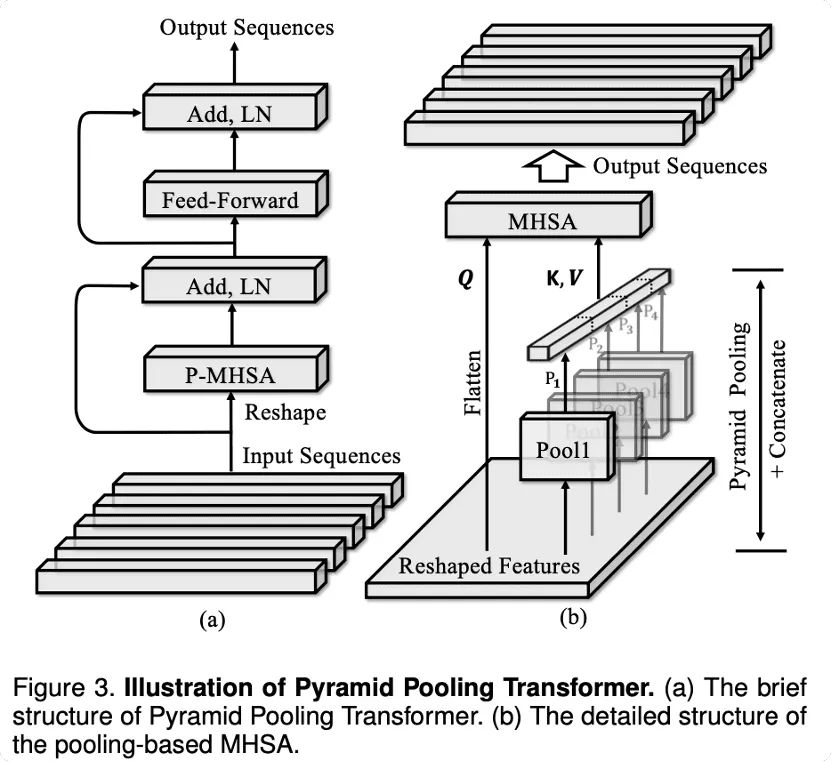
设MHSA中query, key, value分别为 , 传统MHSA的计算方式为
在P2T中,研究人员提出使用:
与传统MHSA的不一致在于, 是对输入特征 使用金字塔池化方式生成的,即对 使用多个不同感受野、步长的池化操作,将中间特征按空间维度拉直拼接为 。研究人员将这种新型的MHSA命名为 Pooling-based MHSA (P-MHSA)。
所以,单个金字塔池化Transformer的计算可以用下式来进行表示:
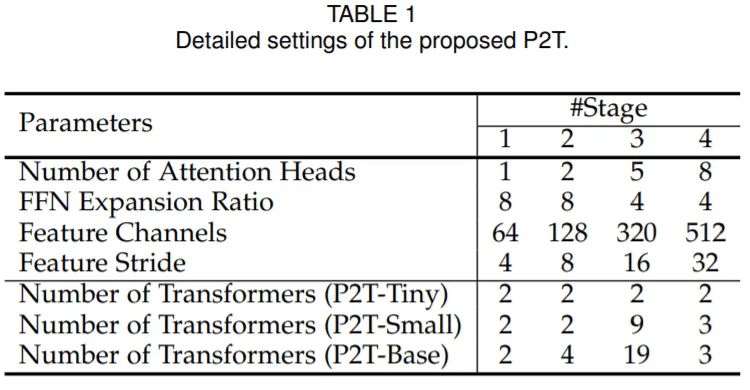
研究人员也构建了多个不同深度的金字塔池化Transformer,使得这种Transformer 可以适用于不同的计算场景。
三、Experiments
为了验证P2T在不同下游任务的有效性,研究人员在语义分割、目标检测、实例分割、视觉显著性等下游任务与现有的多个骨干方法进行对比。
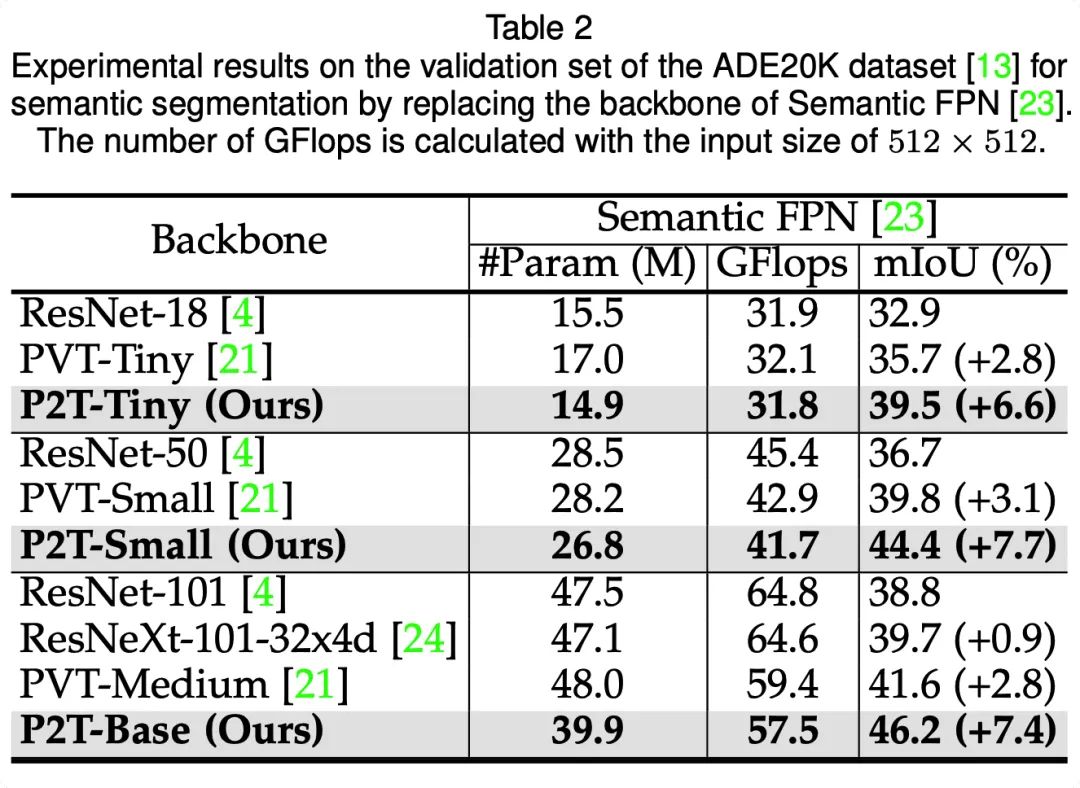
语义分割(ADE20K val)
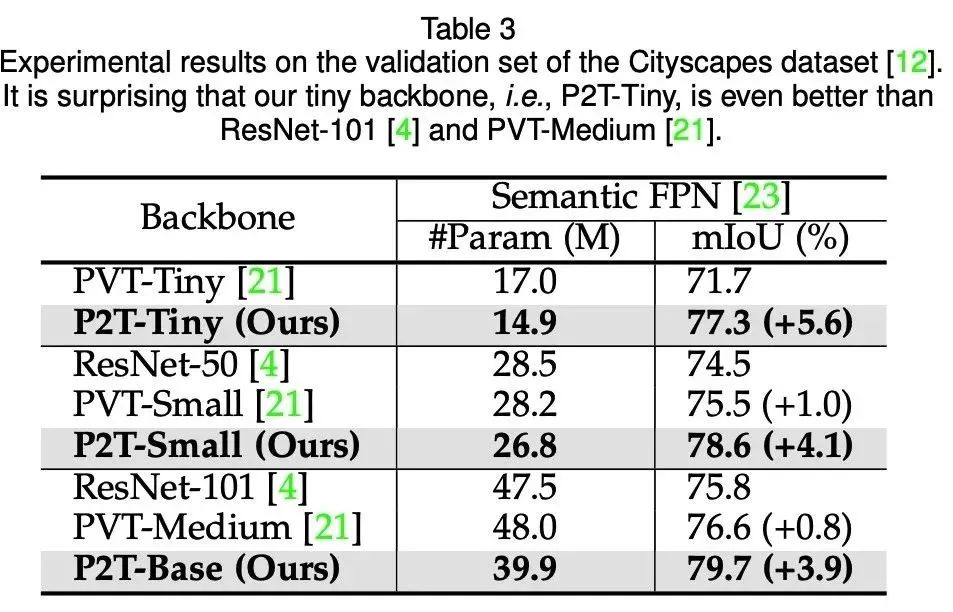
语义分割(Cityscapes val)
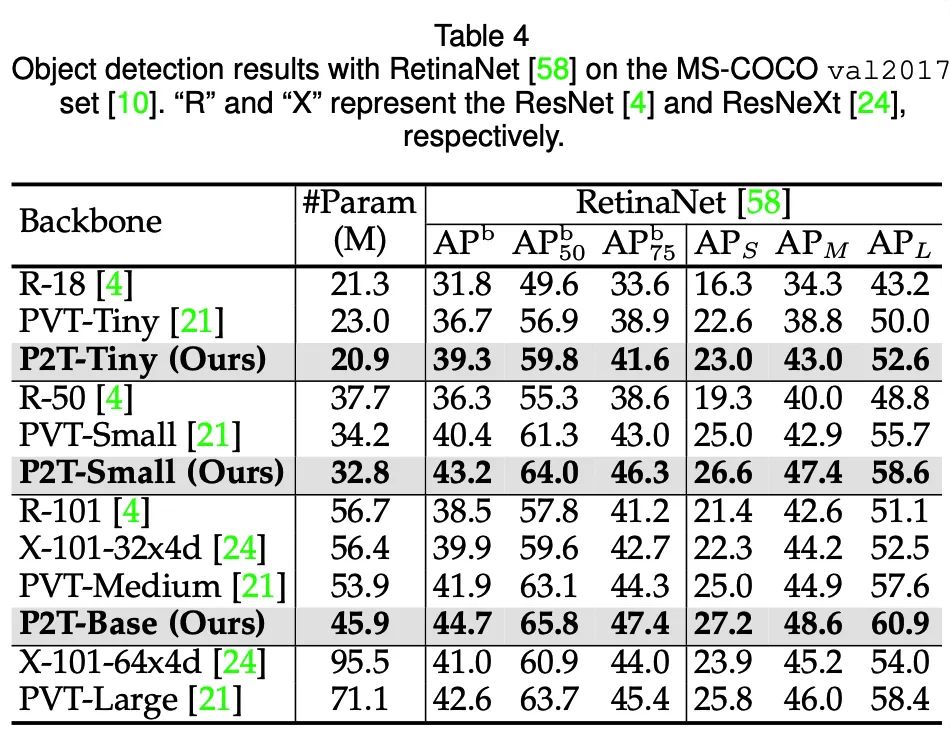
目标检测(MS-COCO 2017val)
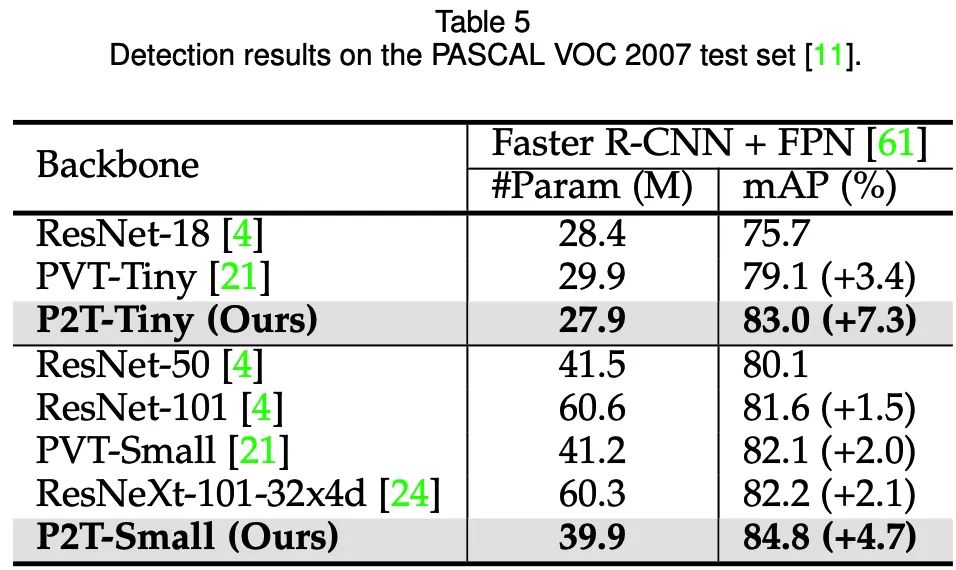
目标检测(Pascal VOC 2007test)
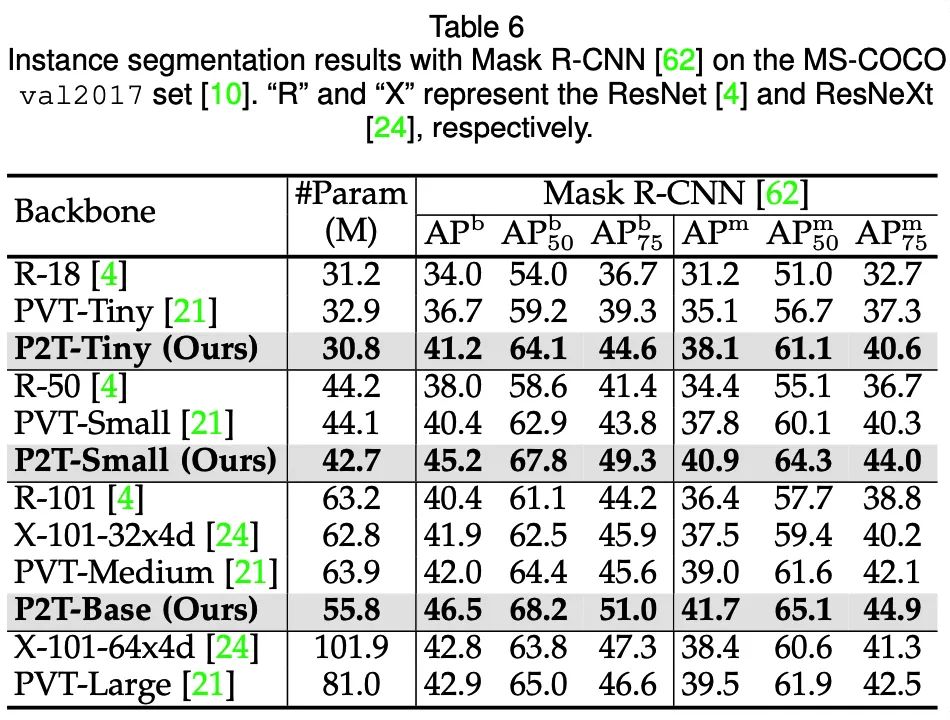
### 实例分割(MS-COCO 2017val)
实例分割(MS-COCO 2017val)
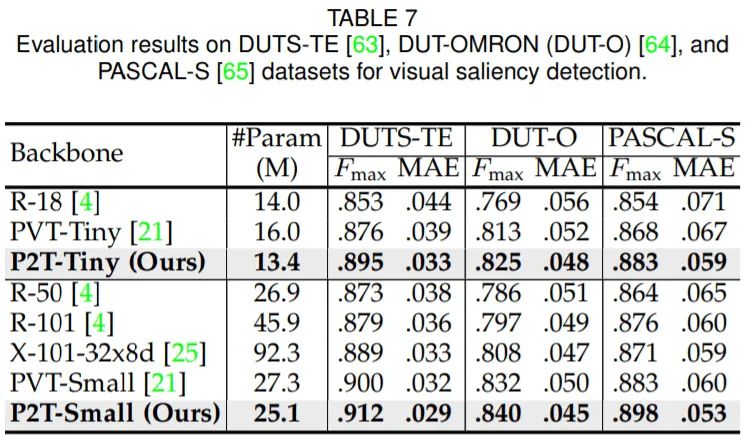
可以发现,在语义分割、目标检测、实例分割、视觉显著性等下游场景上,P2T方法均大幅战胜了CNN及Transformer方法。
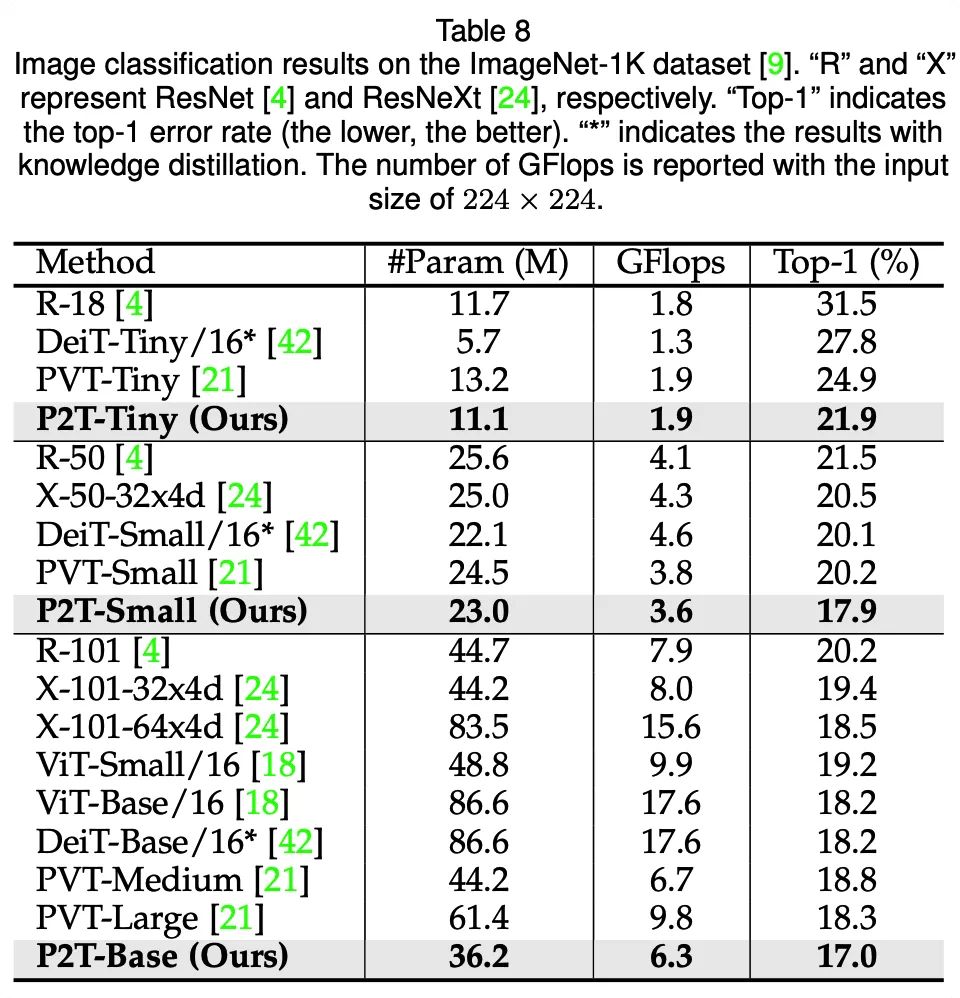
除了在各类下游任务与其他方法作对比,研究人员也测试了P2T在图像分类上的性能。虽然P2T并不是专门设计于图像分类任务,但也相对其他CNN、Transformer方法取得了十分有竞争力的性能。
参考文献
[1] A. Dosovitskiy, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
[2] W. Wang, et. al., “Pyramid Vision Transformer: A versatile backbone for dense prediction without convolutions,” arXiv preprint arXiv:2102.12122, 2021.
[3] Z. Liu, et. al., “Swin Transformer: Hierarchical vision transformer using shifted windows,” arXiv preprint arXiv:2103.14030, 2021.
Illustration by Olha Khomich from Icons8
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“80”获取CVPR 2021-Alpha Refine 直播回放及PPT~


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



