
由于线性空间和时间的复杂性,Transformer模型的最新进展允许前所未有的序列长度。同时,相对位置编码(relative position encoding, RPE)被认为是一种利用滞后而不是绝对位置进行推理的方法。尽管如此,RPE还不能用于Transformer最近的线性变体,因为它需要显式计算注意力矩阵,而这正是这些方法所避免的。在本文中,我们填补了这一缺口,并提出了随机位置编码作为生成PE的一种方法,该方法可以用来替代经典的加性(正弦)PE,并且可以证明其行为类似于RPE。其主要理论贡献是将位置编码与相关高斯过程的交叉协方差结构联系起来。我们在Long-Range Arena基准测试和音乐生成上证明了我们的方法的性能。
https://www.zhuanzhi.ai/paper/e42297b68bb088dc94c114e44992cea1
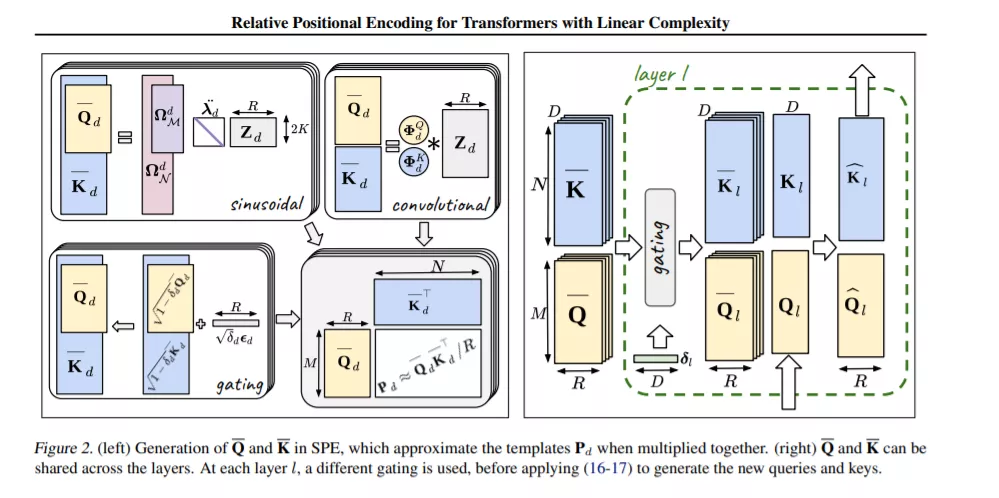
成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
Arxiv
21+阅读 · 2020年12月17日
Arxiv
15+阅读 · 2018年10月11日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
21+阅读 · 2020年12月17日
Arxiv
15+阅读 · 2018年10月11日