【NeurIPS2021】去掉softmax后Transformer会更好吗?复旦&华为诺亚提出SOFT:轻松搞定线性近似
极市导读
本文介绍了复旦大学&华为诺亚提出的一种新颖的softmax-free的Transformer—SOFT。所提SOFT显著改善了现有ViT方案的计算效率,更为关键的是:SOFT的线性复杂度可以允许更长的token序列,进而取得更佳的精度-复杂度均衡。

论文链接:https://arxiv.org/pdf/2110.11945.pdf
代码链接:https://github.com/fudan-zvg/SOFT
项目链接:https://fudan-zvg.github.io/SOFT/
本文是复旦大学&华为诺亚关于Transformer中自注意力机制复杂度的深度思考,首次提出了一种新颖的softmax-free 的Transformer 。本文从softmax self-attention局限性出发,分析了其存在的挑战;然后由此提出了线性复杂度的SOFT;再针对线性SOFT存在的训练问题,提出了一种具有理论保证的近似方案。所提SOFT在ImageNet分类任务上取得了比已有CNN、Transformer更佳的精度-复杂度均衡。
Abstract
ViT通过图像块序列化+自注意力机制将不同CV任务性能往前推了一把。然而,自注意力机制会带来更高的计算复杂度与内存占用。在NLP领域已有不同的方案尝试采用线性复杂度对自注意力进行近似。然而,本文的深入分析表明:NLP中的近似方案在CV中缺乏理论支撑或者无效。
我们进一步分析了其局限性根因:softmax self-attention 。具体来说,传统自注意力通过计算token之间的点乘并归一化得到自注意力。softmax操作会对后续的线性近似带来极大挑战。基于该发现,本文首次提出了SOFT(softmax-free transformer )。
为移除自注意力中的softmax,我们采用高斯核函数替代点乘相似性且无需进一步的归一化。这就使得自注意力矩阵可以通过低秩矩阵分析近似 。近似的鲁棒性可以通过计算其MP逆(Moore-Penrose Inverse)得到。
ImageNet数据集上的实验结果表明:所提SOFT显著改善了现有ViT方案的计算效率 。更为关键的是:SOFT的线性复杂度可以允许更长的token序列,进而取得更佳的精度-复杂度均衡。
Contributation
本文的贡献主要包含以下几点:
-
提出一种新颖的线性空间、时间复杂度 的softmax-free Transformer ;
-
所提注意力矩阵近似可以通过具有理论保证的矩阵分解算法 计算得到;
-
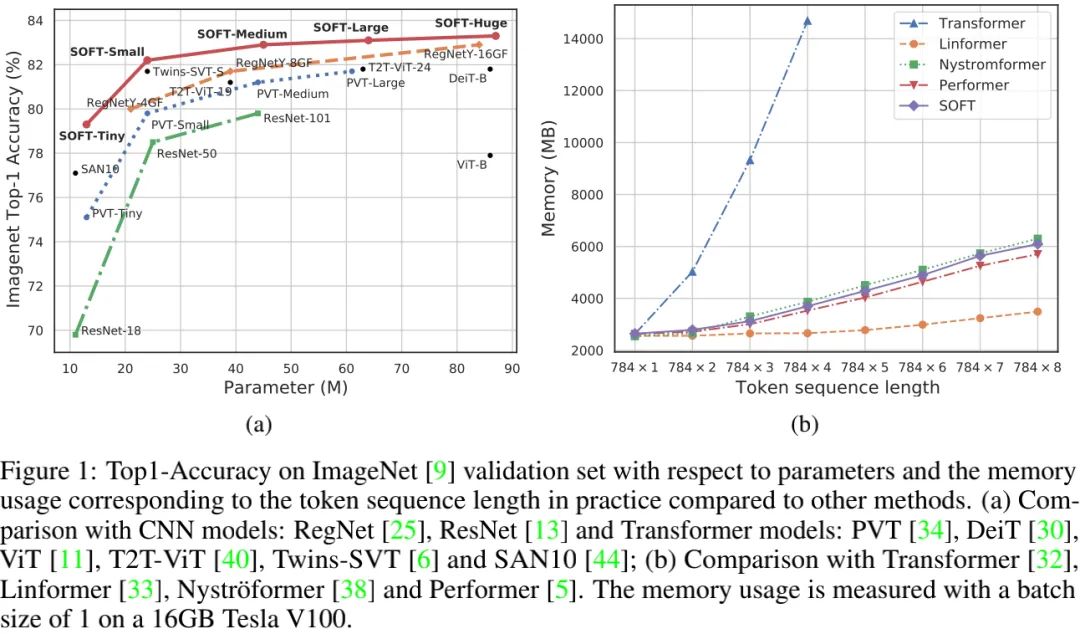
所提SOFT在ImageNet图像分类任务上取得了比其他ViT方案更佳的精度-复杂度均衡 (见下图a)。
Method
Softmax-free self-attention formulation
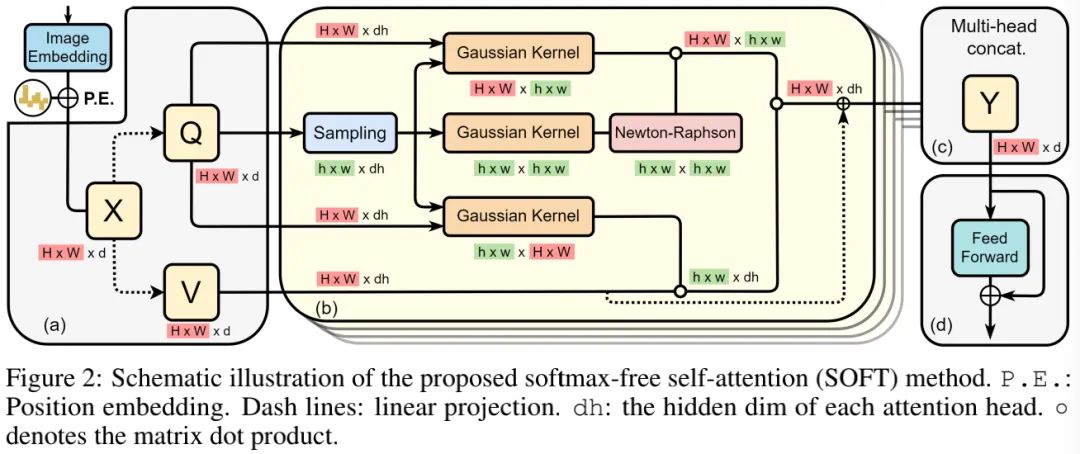
上图给出了本文所提SOFT架构示意图。我们首先来看一下该注意力模块的设计。给定包含n个token的输入序列 ,自注意力旨在挖掘所有token对之间的相关性 。
具体来说,X首先线性投影为三个 维的query、key以及values:
自注意力可以表示为如下广义形式:
自注意力的关键函数 包含一个非线性函数 与一个相关函数 。自注意力的常规配置定义如下:
虽然该softmax自注意力已成为首选且很少受到质疑,但是它并不适合进行线性化。为构建线性自注意力设计,我们引入了一种sfotmax-free自注意力函数:通过高斯核替换点乘操作。定义如下:
为保持注意力矩阵的对称性,我们设置投影矩阵 相同,即 。所提自注意力矩阵定义如下:
为描述的简单性,我们定义为矩阵形式: 。所提自注意力矩阵S具有三个重要属性:
-
对称性 -
所有元素均在[0,1]范围内; -
所有对角元素具有最大值1。
我们发现:当采用无线性化的核自注意力矩阵时,transformer的训练难以收敛 。这也就解释了:为何softmax自注意力在transformer中如此流行。
Low-rank regularization via matrix decomposition with linear complxity
为解决收敛于二次复杂度问题,我们利用了矩阵分解作为带低秩正则的统一解,这就使得模型复杂度大幅下降,且无需计算全部的自注意力矩阵。
作出上述选择因为在于:S为半正定矩阵,且无需后接归一化。我们将S表示为块矩阵形式:
其中,。通过上述分解,注意力矩阵可以近似表示为:
其中, 表示A的MP逆。更多关于MP逆的信息建议查看原文,这里略过。
在上述公式,A和B是S通过随机采样m个token得到的子矩阵,可表示为 (我们将其称之为bottleneck token )。然而,我们发现:随机采样对于m非常敏感。因此,我们通过利用结构先验探索两种额外的方案:
-
采用一个核尺寸为k、stride为k的卷积学习 ; -
采用一个核尺寸为k、stride为k的均值池化生成 。
通过实验对比发现:卷积层学习 具有更好的精度 。由于K与Q相等,因此 。给定m个token,我们计算A和P:
最终,我们得到了SOFT的正则化后的自注意力矩阵:

上图Algorithm1给出所提SOFT流程,它涉及到了MP逆计算。一种精确且常用的计算MP逆的方法是SVD,然而SVD对于GPU训练不友好。为解决该问题,我们采用了Newton-Raphson方法,见上图Algorithm2:一种迭代算法。与此同时,作者还给出了上述迭代可以最终收敛到MP逆的证明。对该证明感兴趣的同时强烈建议查看原文公式,哈哈。
Instantiations
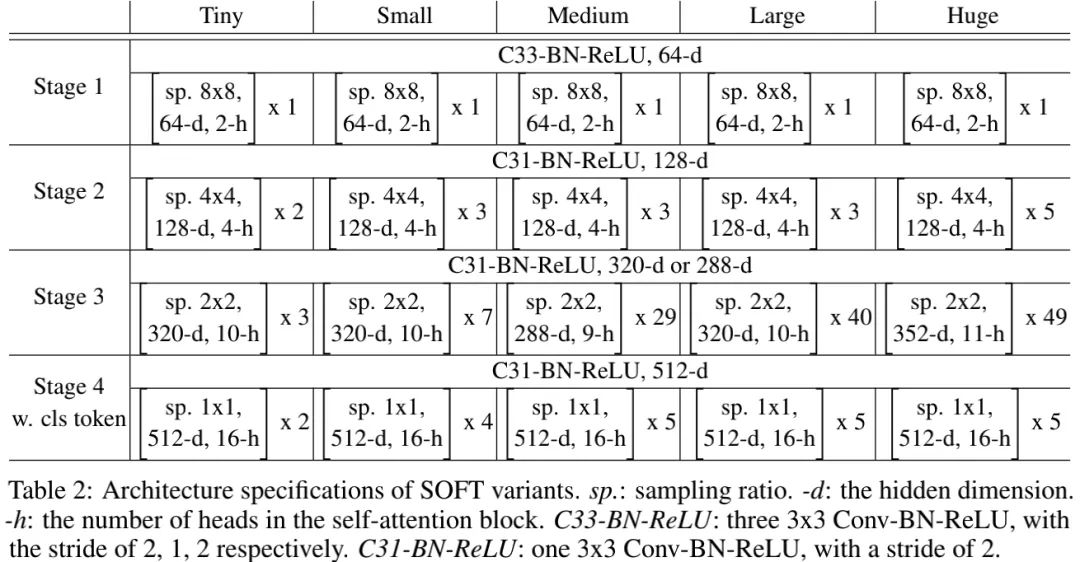
上面主要聚焦于softmax-free self-attention 模块的介绍,接下来我们将介绍如何利用SOFT模块构建Transformer模型。我们以图像分类任务为切入点,以PVT作为基础架构并引入所提SOFT模块构建最终的SOFT模型,同时还在stem部分进行了微小改动。下表给出了本文所提方案在不同容量大小下的配置信息。
Experiments
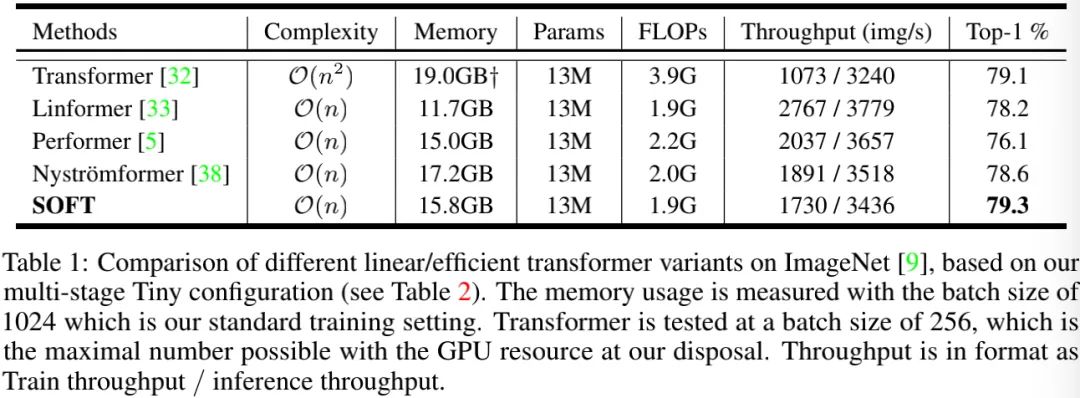
上表对比了所提方案与现有线性Transformer模型的性能,从中可以看到:
-
相比基线Transformer,线性Transformer能够大幅降低内存占用与FLOPs,同时保持相当参数量; -
所提SOFT在所有线性方案中取得了最佳分类精度; -
所提SOFT与其他线性方案的推理速度相当,训练速度稍慢。
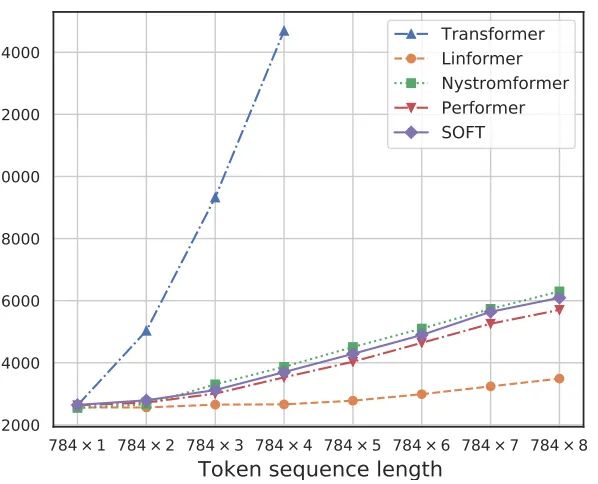
上图给出了不同方案的序列长度与内存占用之间的关系,从中可以看到:所提SOFT确实具有线性复杂度的内存占用 。
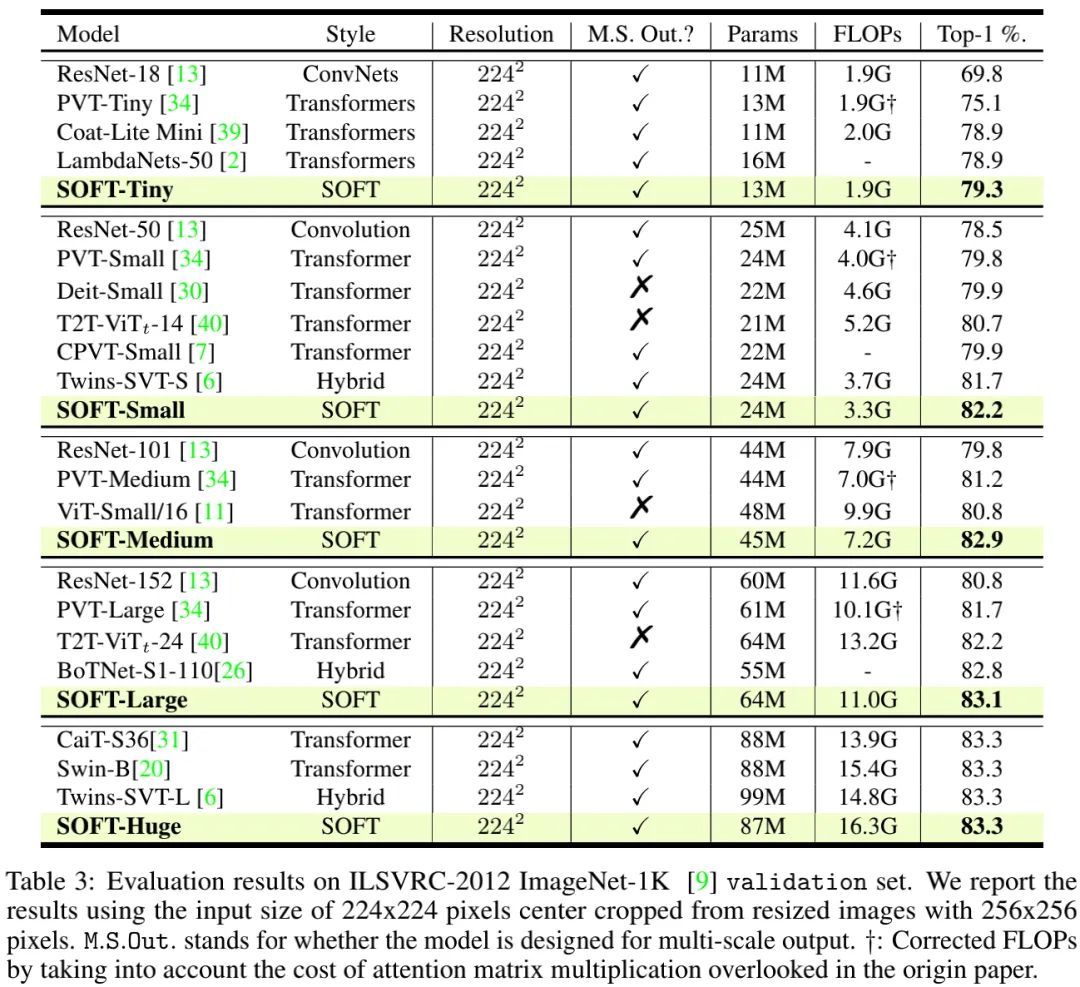
上表给出了所提方案与其他CNN、Transformer的性能对比,从中可以看到:
-
总体来说,ViT及其变种具有比CNN更高的分类精度;
-
相比ViT、DeiT等Transformer方法以及RegNet等CNN方法,所提SOFT取得了最佳性能;
-
相比PVT,所提方案具有更高的分类精度,直接验证了所提SOFT模块的有效性;
-
相比Twins与Swin,所提SOFT具有相当的精度,甚至更优性能。
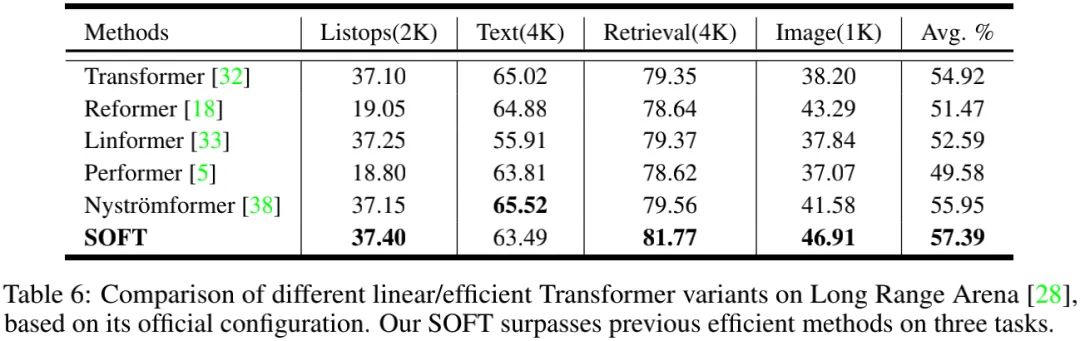
此外,作者还在NLP任务上进行了对比,见上表,很明显:SOFT又一次胜出 。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SOFT” 就可以获取《【NeurIPS2021】去掉softmax后Transformer会更好吗?复旦&华为诺亚提出SOFT:轻松搞定线性近似》专知下载链接




