AAAI 2022 | 无注意力+PatchOut,复旦大学提出面向视觉transformer的迁移攻击方法
本文中,来自复旦大学以人为本人工智能研究中心和马里兰大学的研究者提出了一种双重攻击框架,以提高不同 ViT 模型之间,甚至 ViT 与 CNN 之间对抗样本的迁移性。

论文链接:https://arxiv.org/pdf/2109.04176.pdf
代码链接:https://github.com/zhipeng-wei/PNA-PatchOut
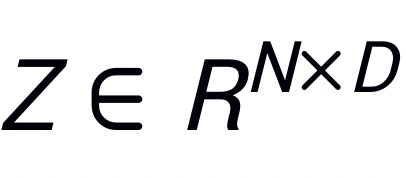 表示输入的 patch embedding,其中N为 patch 的数目,D为 patch 的特征大小;
使用
表示输入的 patch embedding,其中N为 patch 的数目,D为 patch 的特征大小;
使用
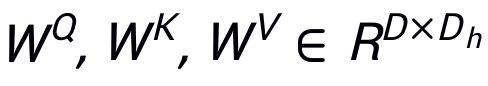 分
别表示 query、key 和 value 的权重,那么注意力图可以表示为:
分
别表示 query、key 和 value 的权重,那么注意力图可以表示为:
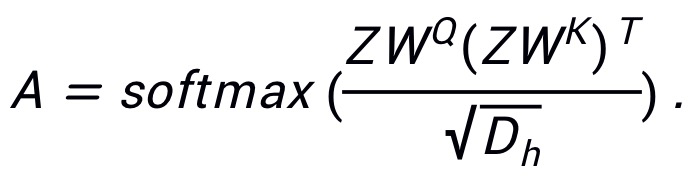
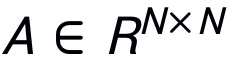 ,那么该 MSA 模块的输出则为:
,那么该 MSA 模块的输出则为:
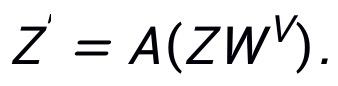
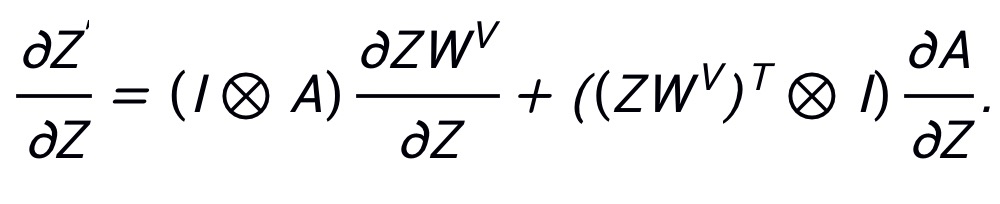
 表示 Kronecker 积。
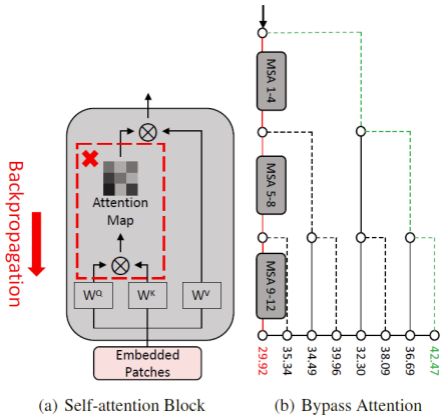
由于 PNA 攻击在梯度反向传播过程中跳过了注意力路径,则
表示 Kronecker 积。
由于 PNA 攻击在梯度反向传播过程中跳过了注意力路径,则
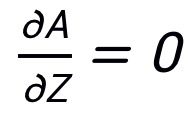 ,那么梯
度信息将变为:
,那么梯
度信息将变为:
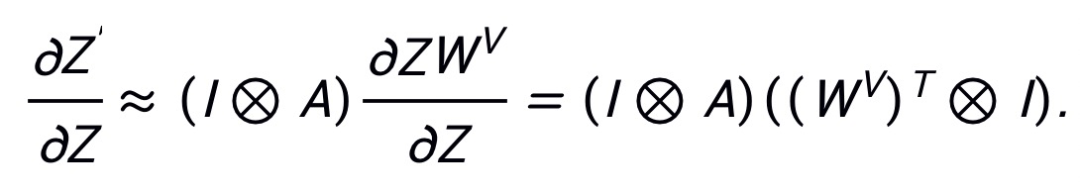
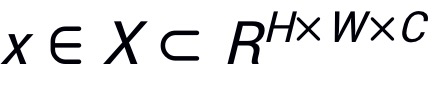 表示输入图像,
表示输入图像,
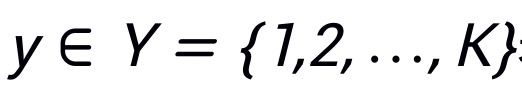 表示其对应真实标签,其中H,W,C分别表示图像的高度,宽度和通道数,K表示类别数目。
使用
表示其对应真实标签,其中H,W,C分别表示图像的高度,宽度和通道数,K表示类别数目。
使用
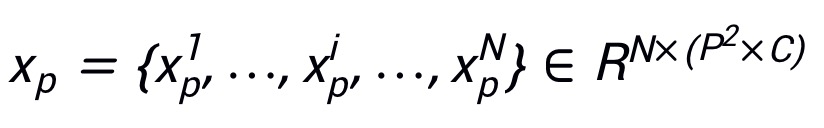 表示 patch,其中
表示 patch,其中
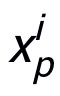 表示x的第i个 patch,(P,P)表示
的分辨率,
表示x的第i个 patch,(P,P)表示
的分辨率,
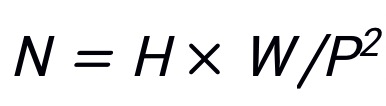 为 patch 的数目。
使用
为 patch 的数目。
使用
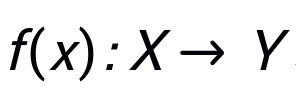 表示模型对于输入的预测结果。
定义
表示模型对于输入的预测结果。
定义
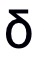 为对抗噪声,那么攻击目标可以定义为
为对抗噪声,那么攻击目标可以定义为
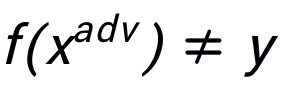 ,其中
,其中
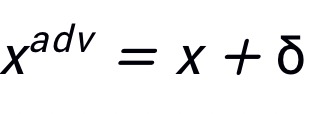 ,且限制
,且限制
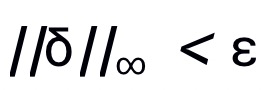 。
定义
。
定义
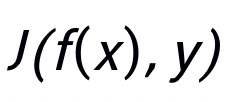 为损失函数。
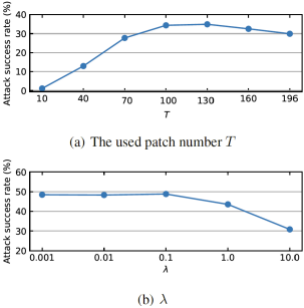
使用来控制在每次迭代中 patch 的数目,并且使用
为损失函数。
使用来控制在每次迭代中 patch 的数目,并且使用
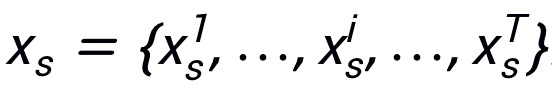 来表示选择到的 patch。
那么攻击掩码
来表示选择到的 patch。
那么攻击掩码
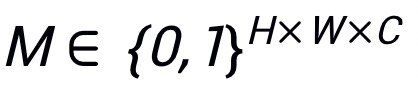 可定
义为:
可定
义为:
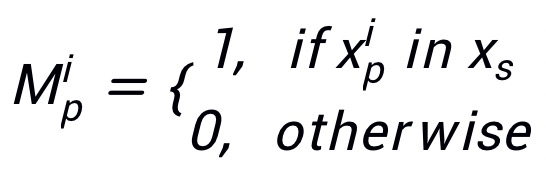
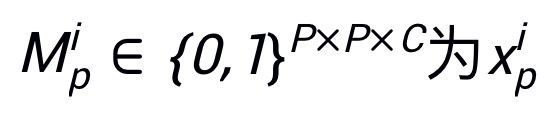 为所对应的掩码。
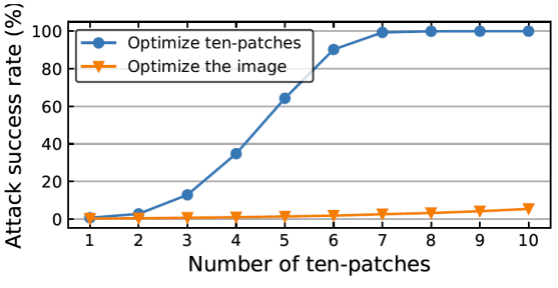
结合最大化 L2 距离后,PatchOut 攻
击的目标函数可以定义为:
为所对应的掩码。
结合最大化 L2 距离后,PatchOut 攻
击的目标函数可以定义为:
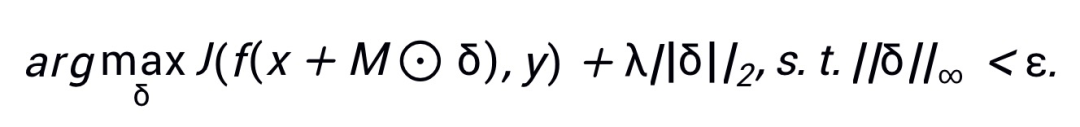
 表示逐元素相乘,损失中的第二项鼓励对抗样本远离x,λ为控制 L2 项和损失项间平衡的超参数。
表示逐元素相乘,损失中的第二项鼓励对抗样本远离x,λ为控制 L2 项和损失项间平衡的超参数。
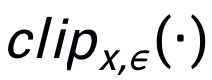 用来限制生成的对抗噪声满足
用来限制生成的对抗噪声满足
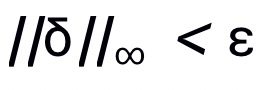 。
。

使用 NVIDIA Riva 快速构建企业级 ASR 语音识别助手
自动语音识别简介
NVIDIA Riva介绍与特性
快速部署NVIDIA Riva
启动NVIDIA Riva客户端快速实现语音到文字的转录
使用Python快速搭建基于NVIDIA Riva自动语音识别服务应用


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
Arxiv
1+阅读 · 2022年4月15日



相关VIP内容
相关资讯