CVPR 2022 Oral | 全新视觉Transformer主干!NUS&字节跳动提出Shunted Transformer
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
Shunted Self-Attention via Multi-Scale Token Aggregation

论文链接: https://arxiv.org/abs/2111.15193
代码链接(已开源):
https://github.com/OliverRensu/Shunted-Transformer
1.研究动机
基于自注意力机制(Self-Attention)的Vision Transformer (ViT)在多个计算机视觉任务上取得了令人惊艳的成果。然而自注意力机制的内存消耗是和Token数量的平方相关的,这导致ViT需要在第一层进行16x16下采样并且得到的特征是粗糙的和单一尺度的,同时每个tokens的固定且相同的感受野和一个注意力层内的均匀的信息粒度,因此无法同时捕获不同尺度的特征。如图所示,

圆点的数量表示计算量,圆点的大小表示每个token的感受野。我们将ViT,PVT,和我们的SSA的注意力机制放在相同大小的特征图上。ViT需要很大的计算量,对于捕捉大的物体是多余的,PVT通过融合tokens来降低计算量,但是这样会使得来自小物体的tokens和背景噪音混合,不利于捕捉小物体。我们的方法能准确捕捉多尺度的物体。我们的方法将多头注意力机制分成不同的group。每一个group都负责一个注意力粒度,对于细粒度的group,我们的方法学习去融合较少的tokens,并且保证更多的细节,对于粗粒度的组,这个方法去融合大量的tokens,因此减少了计算量,同时又保证了捕捉大物体的能力,这样的多粒度的组联合的去学习多粒度的信息,让整个模型能够捕捉多尺度的物体。
我们的贡献如下:
-
我们提出了 Shunted Self-Attention (SSA),它通过在每一个注意力层内集成多尺度的特征提取能力,使得我们的SSA自适应地合并针对大物体的tokens以提高计算效率,并保留针对小物体上的特征捕捉能力。 -
基于SSA,我们提出了 Shunted Transformer特别是能够捕捉多尺度物体。 -
我们对Shunted Transformer在分类、目标检测以及语义分割上做了验证。实验结果表明在类似的模型大小下,我们的Shunted Transformer始终优于以前的Vision Transformer。
2.方法
Shunted Self-Attention
如图所示,
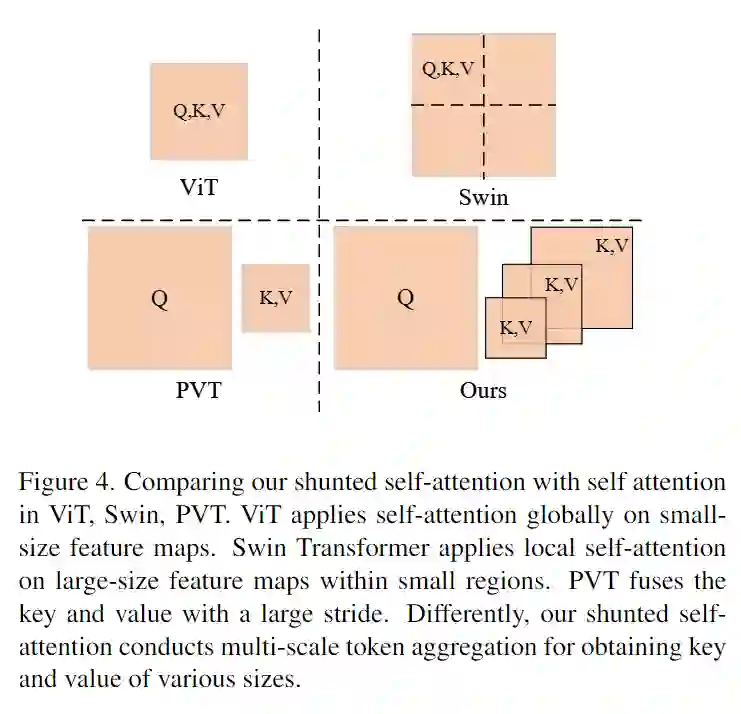
不同于ViT应用注意力在小尺寸特征图上,Swin分割特征图局部自注意力,PVT只有单尺度粗颗粒度特征融合。我们的方法借鉴了PVT的提出要通过token融合产生不同大小的{Key, Value},同时使用local enhancing layer强化value:
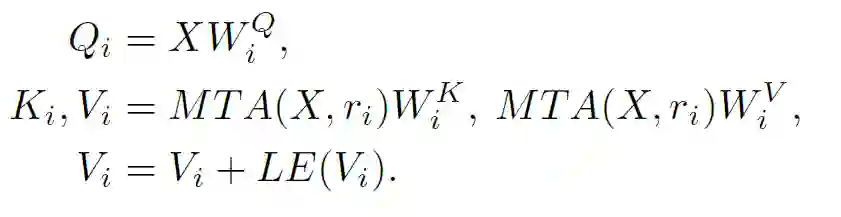
其中MAT指多尺度特征融合在第i个head的下采样率为 。当r变大的时候,K和V里面的更多的token被融合在了一起,因此K和V的长度就变短了,计算量就减少了,但是仍然保持了捕捉大物体的能力,相反当r变小的时候,更多的细节就被保存在K和V里面。通过整合多种多样的r在一个注意力层里,就能够实现一个注意力层捕捉多粒度的特征。
Detail-specific Feedforward Layers
传统的feedforward layer是point-wise的,没有跨token的信息,因此我们提出通过明确细节来补充局部的信息到里面。
Conv-Stem Patch Embedding
和之前的只用一层7x7,步长为4的卷积作为patch embedding不同,我们采用了多层卷积作为patch embedding。其中第一层为7x7步长为2的卷积紧接着一些3x3的卷积,其数量取决于模型大小。最后,一个步长为2的不重叠映射生成输入到注意力的特征。
3.实验结果
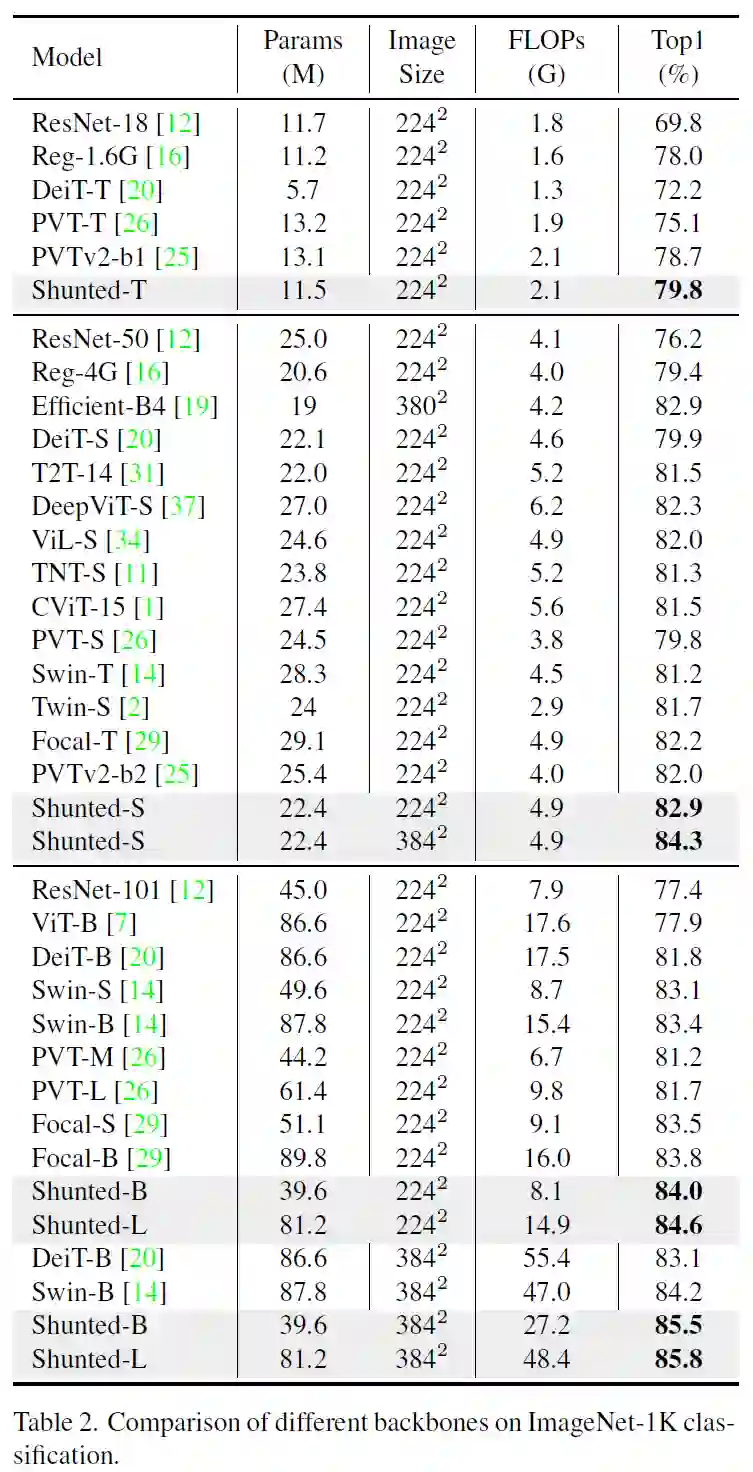
分类 (ImageNet)
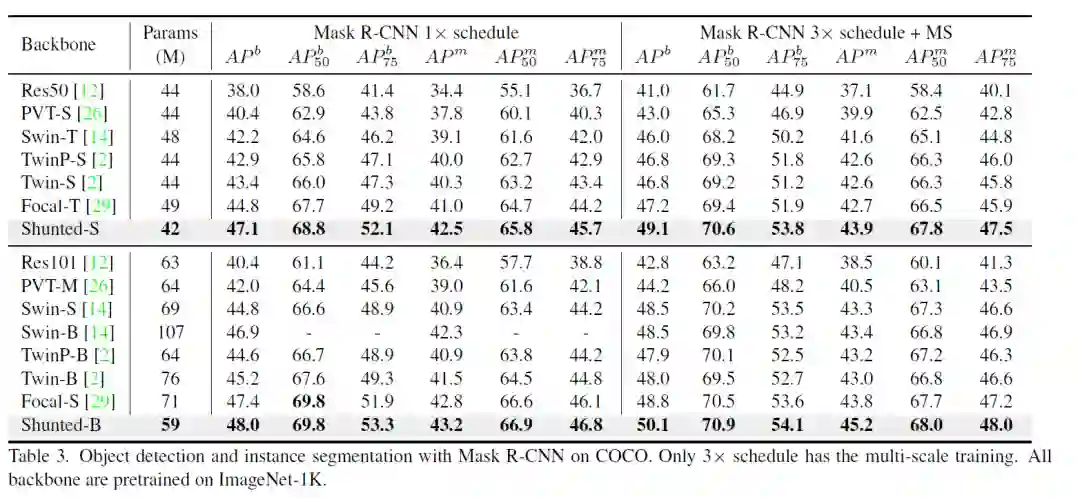
我们的方法相比之前的Transformer无论在大模型或者小模型,224x224和384x384的输入下都显著超越之前的方法
检测 (Coco)
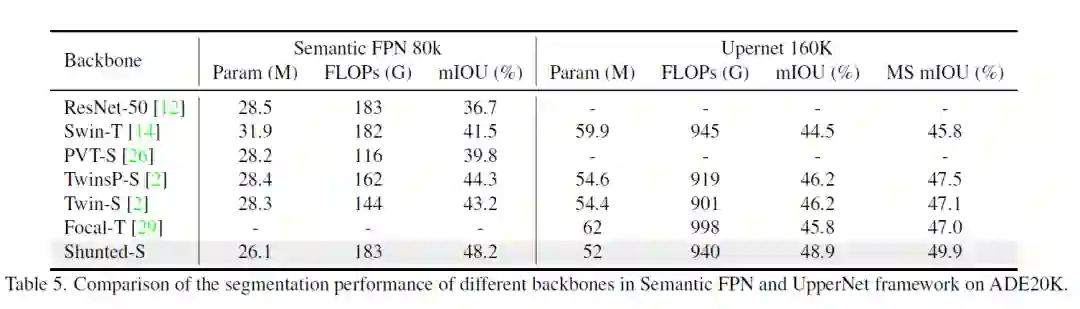
分割 (ADE20K)
上面论文、代码下载
后台回复:SSA,即可下载上述论文/代码
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer或者目标检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer或者目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看