CVPR 2022 | 关注文本阅读顺序,蚂蚁集团、上海交大提出多模态文档理解模型

©作者 | 蚂蚁集团-大安全-机器智能
来源 | 机器之心
来自蚂蚁集团 - 大安全 - 机器智能和上海交通大学的研究者提出了一种多模态文档理解新模型 XYLayoutLM。
近年来,多模态文档理解在各类场景得到了广泛的应用。它要求我们结合图像,文本和布局信息对扫描件或者 pdf 文件进行理解。在常见的表单理解的任务中,多模态数据如图 1 所示。

除此之外,多模态的模型还被应用于文档自动处理,文本关系提取和网页分类定性等等一系列应用。然而,需要强调的是,这个问题并不简单。这是因为表单的结构复杂多变,布局信息难以提取。
目前学术界中,针对多模态文档理解的模型方案,通常都需要先经过对图像进行 ocr 扫描,解析出图中的文本和文本框位置,再将得到的文本和文本框坐标,按照 ocr 解析出的默认顺序,将文本框及其对应的内容输入给模型。然而,和普通的文档图像不同,诸如票据、表单、卡证等数据,其文本位置通常无法按照传统的 “从左至右“或者” 从上到下“进行简单排序,而是存在丰富的层次结构。一个合理的文本框阅读顺序(proper reading order),可以帮助模型更好得理解图像讯息。
另一个局限性是许多现有的模型使用了长度固定的位置编码(position embeddings),这会导致模型在训练完成后无法处理更长的输入序列。当然我们可以强行使用插值算法补全缺失的部分,但还是会影响文档理解的结果。
针对上述两个缺陷,来自蚂蚁集团机器智能团队和上海交通大学的研究者做了如下两点改进,并提出了多模态文档理解模型 XYLayoutLM:
1. 我们提出一个创新的 Augmented XY Cut 算法作为 augmentation 策略来对文本框进行排序生成合理的阅读顺序,从而改进模型性能;
2. 基于空洞卷积的思想,我们提出了可以处理变长输入序列的空洞条件位置编码 DCPE 生成模块。
XYLayoutLM 模型通过获得合理的文本阅读顺序和提出空洞条件位置编码,取得了在 FUNSD 和 XFUN 文档理解数据集上非常具有竞争力的结果。该论文已被 CVPR 2022 录用。

论文标题:
XYLayoutLM: Towards Layout-Aware Multimodal Networks For Visually-Rich Document Understanding
收录会议:
CVPR 2022

合理的阅读顺序
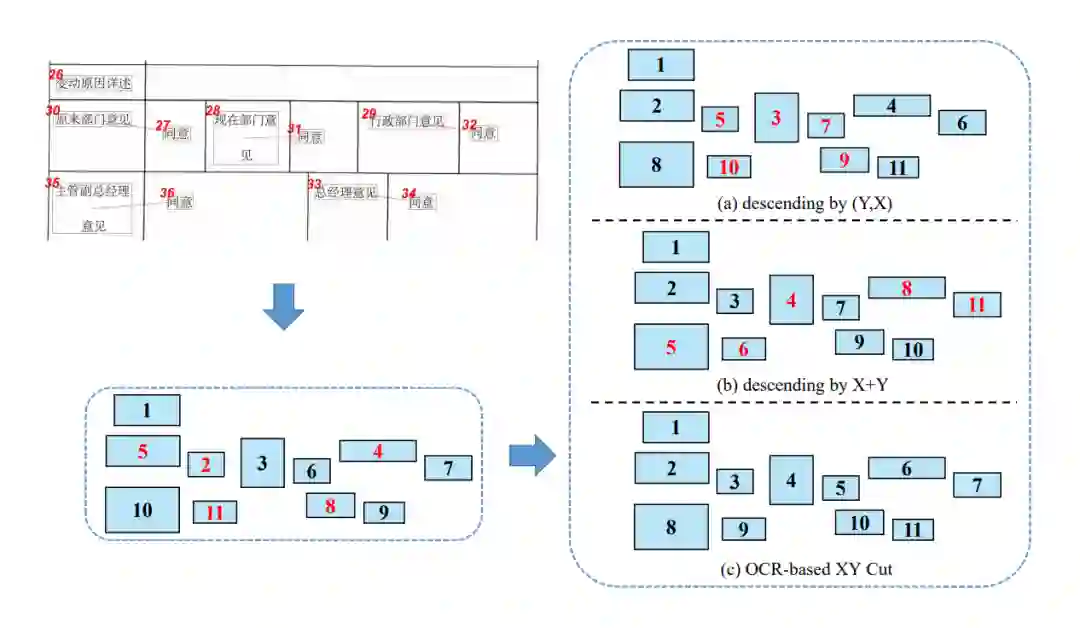
▲ 图2. 不同的阅读顺序
首先我们解释一下合理阅读顺序的定义。一般来说,对于一个给定的文档和完美的 ocr 工具,人类观察所有文本框的阅读顺序即为一个合理阅读顺序。现实情况却是,ocr 识别出的文本框位置往往不够准确,甚至会存在明显在同一行但是 y 轴差距过大的一些文本框。这些噪声一方面会使得存在非唯一的合理阅读顺序,同时也会使得简单的对文本框进行排序的规则失效。
如图 2a 和 2b 中所示,不管是按照先 Y 后 X 降序还是 X+Y 降序排序,得到的阅读顺序都有不对的地方,也就是标红的序号。而我们通过调研文章发现,XY Cut [1] 这个算法能获得合理的阅读顺序。

方法介绍
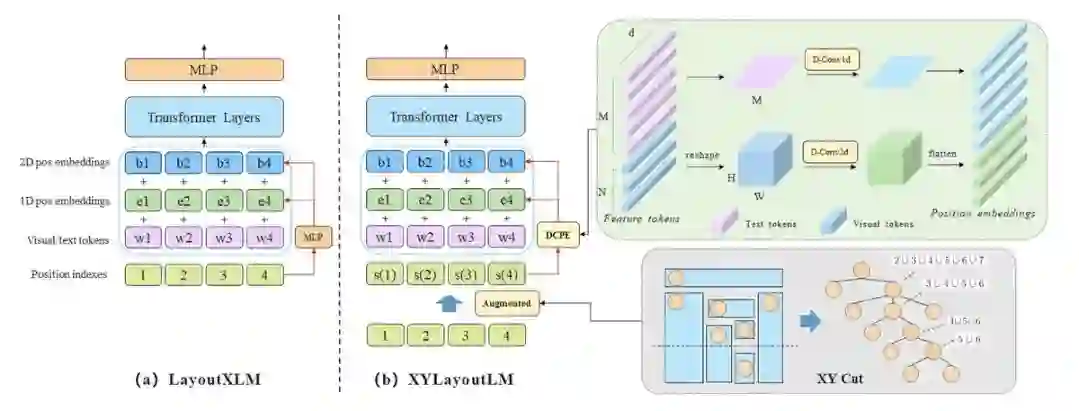
图 3 展示了基准模型 LayoutXLM [2] 和我们的 XYLayoutLM 的区别。我们的模型输入是图像视觉特征,文本特征和文本位置特征。视觉特征是把 ResNeXt-101 的特征图池化到 7*7 的特征图拉平。同时,两个位置编码生成器把输入文本框编码成 pos embeddings 和 box embeddings。在此之后,我们将 embeddings 都拼接起来,输入具有 self-attention 的 transformer 层,输出的视觉 / 文本 token 表征被用于文档理解任务。
与基准模型 LayoutXLM 不同的是,我们的 XYLayoutLM 有两个创新性模块:
1. 我们提出了一个 Augmented XY Cut 模块来对文本框进行排序,同时生成不同的合理阅读顺序,以提升模型的鲁棒性;
2. 为了替代只能生成固定长度 embeddings 的 MLP,我们提出了 DCPE 模块处理文本和视觉的变长序列。
2.1 Augment XY Cut
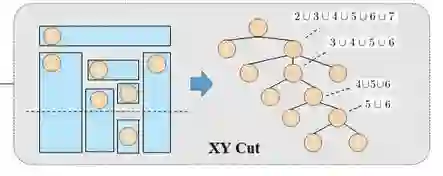
▲ 图4. XY Cut

▲ 算法1
XY Cut [1] 是一个启发式的迭代算法。以水平方向的映射为例子,我们先将所有的文本框 boxes 映射到 Y 轴形成相应的一堆映射区间,得到
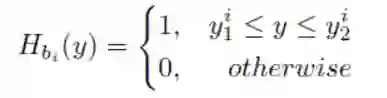
这个指示函数代表第 i 个 box 映射到 Y 轴形成的区间。我们遍历所有的 i 求和,得到
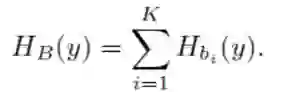
该函数在 y 点的值代表了有多少个本文框 box 在 y 点上有交集。
我们寻找使得 HB(y) 函数值为 0 的一些点 y*,以它们为基础进行 cut。此时,寻找所有文本框的阅读顺序被分解成了一些子问题,因此我们可以进行递归调用求解。另外,水平映射和竖直映射是交替进行的。递归的终止条件是,最后剩下的文本框在两个方向都有交集。此时,我们按照传统的先排序 Y 后排序 X 的规则确定剩下的文本框的阅读顺序。
以图 4 为例,我们先做一次水平映射,确定了 1 号和 2~7 号的顺序。接着,我们做竖直映射,可以确定 2 号、7 号和 3~6 号的阅读顺序。继续以上过程,最终可以得到一个合理的文本框阅读顺序。
相较于启发式的 XY Cut,我们提出的 Augmentd XY Cut 增加了算法 1 中的第 2 步,即以一定的概率给文本框的 box 一些小的 x 轴和 y 轴上的平移扰动,从而生成一些合理的阅读顺序,以模拟现实场景中 ocr 的识别噪声,从而提升模型的鲁棒性。
2.2 DCPE模块

现有模型的第二个局限性是 position embedding 的长度固定。对于这一点,最近的 CPE[3]将 MLP 替换成了新的 PEG 模块来处理变长的输入序列。具体流程是先将输入 tokens reshape 成 2D 的特征,然后利用卷积去提取 local 信息做成 position embedding。
但是,在多模态任务中直接使用 CPE 会遇到问题。因为对于 CPE 所处理的图像分类来说,它的输入 tokens 是有规律的图像 patches,比较常见的作法是将一张图分成 16*16 的小 patch 再拉平,因此它可以 reshape 并且利用 2D 卷积来提取邻域信息。而多模态模型的输入 tokens 除了图像信息还有文本 1D 信息,其中 1D 信息是没法 reshape 成 2D 提取邻域信息的。
因此,我们基于 CPE 提出了 DCPE,如图 5 所示。主要有 2 点改进:1. 是将 text 和 image 的 tokens 分开处理,text 过 1D 卷积,image 过 2D 卷积,最后再合并起来。二是我们观察到多模态模型往往需要更大的感受野,举个例子,he is a very handsome boy. 这句话 he 和 boy 分别是主语和宾语,他们的关系非常重要。而 CPE 中的普通卷积可能捕捉不到这种长距离的信息,因此我们使用了空洞卷积替代了标准卷积,使得在相比 CPE 在不额外增加计算量的前提增加了模型的感受野,进一步提升模型性能。除此之外,DCPE 模块正好能使用到 Augmented XY Cut 带来的红利。因为阅读顺序的合理性加上特征提取能力的提升,能得到 1+1>2 的效果。

实验结果
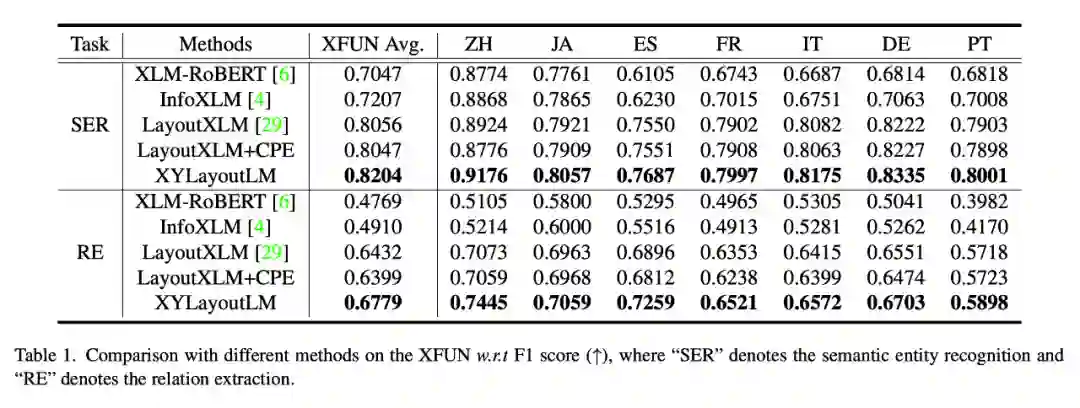

上面的两个表格是 XYLayoutLM 在两个学术数据集 XFUN 和 FUNSD 上的结果。从中可以看出我们的方案在模型参数量相当的情况下,F1 score 达到了 SOTA。

上面这个表格验证了我们提出的两个模块的有效性。其中第四行的结果表明只在基础模型上加 DCPE 而不考虑文本框阅读顺序的情况下提升较小,与预期相符。

上表在 LayoutXLM 上测试了不同的顺序策略导致的结果,同时通过比较结果我们确定了 Augmented XY Cut 中的 3 个超参数。
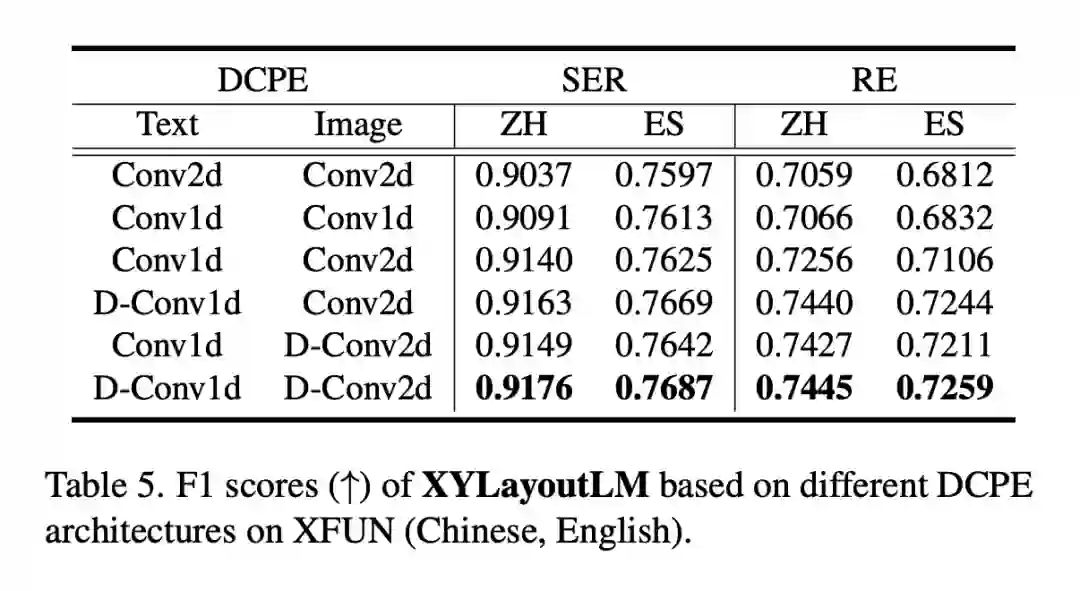
上表探索了在 text 和 image 模态上是否使用空洞卷积的结果。我们发现在两个模态上均使用空洞卷积效果最好。

可视化

上图是利用 Augmented XY Cut 对文本框顺序排序后输出的一个结果。其阅读顺序比默认顺序更加合理。

上图是 LayoutXLM 和我们的 XYLayoutLM 预测分类的结果。从中可以看出我们的方法的有效性。

参考文献
[1] Jaekyu Ha, Robert M Haralick, and Ihsin T Phillips. Recursive xy cut using bounding boxes of connected components. In ICDAE, 1995.
[2] Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, and Furu Wei. Layoutxlm: Multimodal pre-training for multilingual visually-rich document understanding. arXiv preprint arXiv:2104.08836,
2021.
[3] Xiangxiang Chu, Zhi Tian, Bo Zhang, Xinlong Wang, Xiaolin Wei, Huaxia Xia, and Chunhua Shen. Conditional positional encodings for vision transformers. arXiv preprint arXiv:2102.10882, 2021.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧


