「理解和生成」的大一统!华人一作提出BLIP模型,「视觉+语言」任务多项SOTA
![]()
新智元报道

新智元报道
编辑:LRS
【新智元导读】来自Salesforce的华人研究员提出了一个新模型BLIP,在多项「视觉-语言」多模态任务上取得了新sota,还统一了理解与生成的过程。目前代码开源在GitHub上已取得超150星!
视觉语言预训练(Vision-language pre-training)的相关研究在各种多模态的下游任务中已经证明了其强大的实力。

但目前的模型和方法还存在两个主要的缺陷:
1、从模型角度来看,大多数方法要么采用基于编码器的模型,要么采用编码器-解码器模型。然而,基于编码器的模型不太容易直接迁移到文本生成的任务中,如图像标题(image captioning)等;而编码器-解码器模型还没有被成功用于图像-文本检索任务。
2、从数据角度来看,大多数sota的方法,如CLIP, ALBEF, SimVLM 都是对从网上收集的图像-文本对(image-text pair)进行预训练。尽管可以通过扩大数据集的规模来获得性能上的提高,但研究结果显示,有噪声的网络文本对于视觉语言学习来说只能得到次优的结果。
为此,研究人员提出了一个新的模型BLIP(Bootstrapping Language-Image Pre-training),可以统一视觉语言理解和生成,目前代码在GitHub上已取得超150个Stars。

论文地址:https://arxiv.org/abs/2201.12086
项目地址:https://github.com/salesforce/BLIP
试玩地址:https://huggingface.co/spaces/akhaliq/BLIP
根据试玩效果来看还是不错的,例如表情包的标题,模型的返回结果为「两个熊猫熊的黑白照片」。
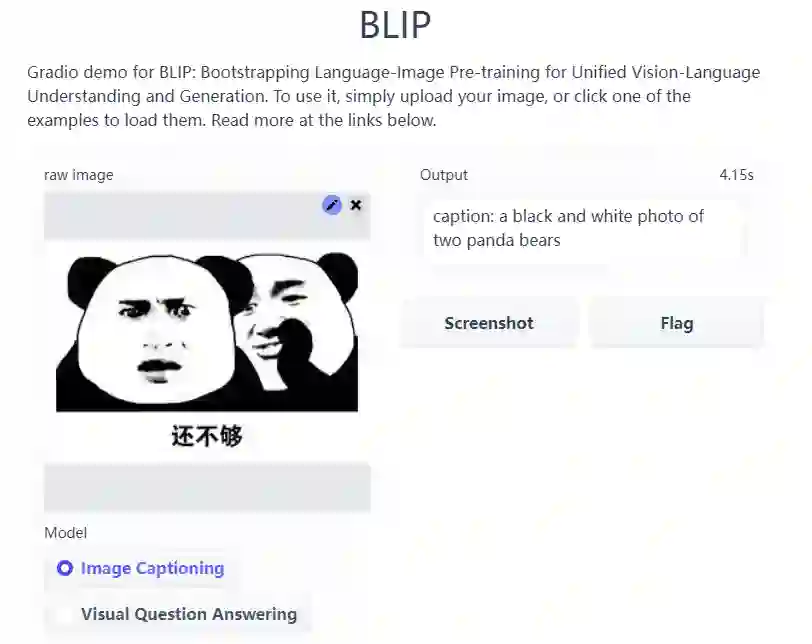
这不由得让我想起来那个经典笑话:「熊猫没办法拍彩色照片,除非吐舌头」。
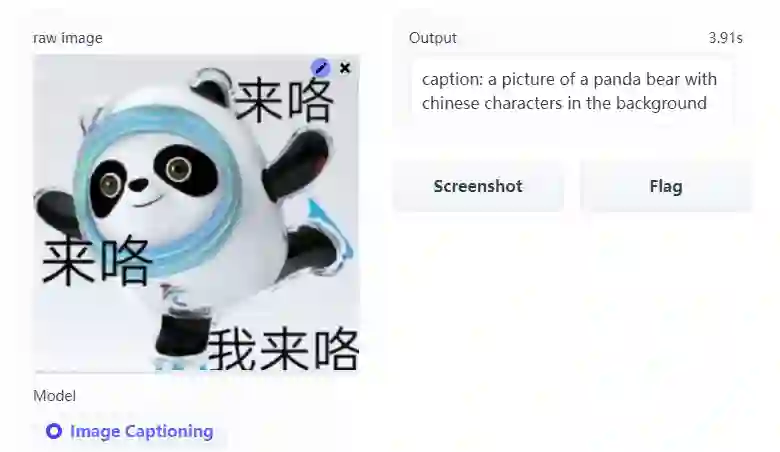
给冰墩墩的标题则是:「a picture of a panda bear with chinese characters in the background(熊猫图片,背景是汉字)」。
作者给的一个例子是梵高的星空图,BLIP起的标题是「caption: a painting of a starry night over a city(一幅描绘城市星空的画)」。

但当我们问他,「What's this」时,BLIP给出的答案是painting,即绘画、油画。

什么是BLIP?
什么是BLIP?
BLIP是一个全新的VLP框架,与现有的方法相比,能够覆盖范围更广的下游任务。
BLIP分别从模型和数据的角度引入了两点创新:
1、编码器-解码器的多模态混合(MED, Multimodal mixture of Encoder-Decoder),一个全新的模型架构,能够有效地进行多任务预训练和灵活的迁移学习。一个MED可以作为一个单模态编码器(unimodal encoder),或是基于图像的文本编码器(image-grounded text encoder),或是基于图像的文本解码器(image-grounded text decoder)。
该模型与三个视觉语言目标共同进行预训练,即图像-文本对比学习(image-text contrastive learning)、图像-文本匹配(image-text matching)和图像-条件语言建模(image-conditioned language modeling)。
2、标题和过滤(Captioning and Filtering,CapFilt),一种新的数据集boostrapping方法,可以用于从噪声图像-文本对中学习。将预训练的MED微调为两个模块:一个是给定网络图像产生合成标题的captioner,另一个是去除原始网络文本和合成文本中的噪声标题的Filter。
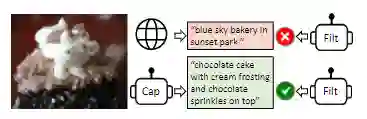
实验结果表明,通过captioner和filter的协作,BLIP模型能够在各种下游任务上取得了稳定的性能改进,包括图像-文本检索、图像标题、视觉问答、视觉推理和视觉对话。研究人员还发现,更多样化的caption会产生更大的性能收益。
将模型直接迁移到两个视觉语言任务时(文本-视频检索和videoQA),研究人员还实现了sota的zero-shot性能。
文章的第一作者是Junnan Li,目前是在位于新加坡的Saleforce亚洲研究院的高级研究科学家,博士毕业于新加坡国立大学。主要研究领域包括自监督学习、半监督学习、弱监督学习、迁移学习,视觉和语言。

模型架构
模型架构
BLIP采用Visual Transformer作为图像编码器,将输入的图像划分为patch,然后将patches编码为一个embedding序列,并用一个额外的[CLS]标记来代表全局图像特征。与使用预训练的目标检测器进行视觉特征提取相比,使用ViT更便于计算,并且已经逐渐成为主流。
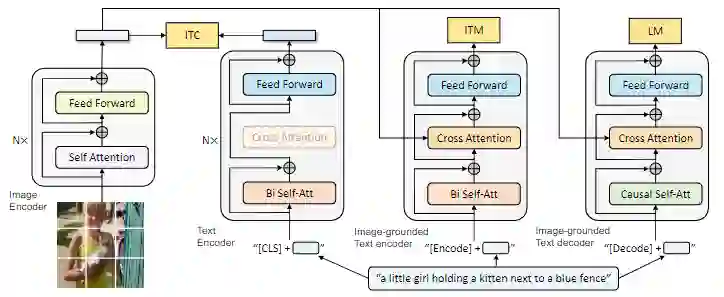
为了预训练一个具有理解和生成能力的统一模型,研究人员提出了多模态混合编码器-解码器(MED),能够用于多任务。
1、单模态编码器(Unimodal encoder),对图像和文本分别进行编码。文本编码器(text encoder)与BERT相同,在文本输入的开头附加一个[CLS]标记,以总结句子。
2、以图像为基础的文本编码器(Image-grounded text encoder),通过在自注意力(SA)层和前馈网络(FFN)之间为文本编码器的每个Transformer块插入一个额外的交叉注意力(CA)层来注入视觉信息。一个特定任务的[Encode]标记被附加到文本上,[Encode]的输出embedding被用作图像-文本对的多模态表示。
3、以图像为基础的文本解码器(Image-grounded text decoder),用因果自注意力层(causal self-attention layer)替代编码器中的双向自注意力层。用[Decode]标记来表示一个序列的开始和结束。
三大损失函数
三大损失函数
在预训练期间,BLIP联合优化三个目标,其中两个是基于理解的目标,一个是基于生成的目标。
每个图像-文本对只需要在计算量比较大的ViT中进行一次前向传递,并在text Transformer系统中进行三次前向传递。
1、图像-文本对比损失(Image-Text Contrastive Loss, ITC)激活了单模态编码器,目的是通过促进正向的图像-文本对与负向的图像-文本对有相似的表示,来对齐ViT和text Transformer的特征空间。在以前的研究中已被证明是改善视觉和语言理解的一个有效目标。研究人员遵循前人的ITC损失,引入了一个动量编码器来产生特征,并从动量编码器中创建软标签作为训练目标,以说明negative pairs中的潜在positive。
2、图像-文本匹配损失(Image-Text Matching Loss, ITM)激活了以图像为基础的文本编码器。它的目的是学习图像-文本的多模态表示以捕捉视觉和语言之间的细粒度对齐。ITM是一个二元分类任务,模型根据多模态特征使用一个ITM头(一个线性层)来预测一个图像-文本对是positive(匹配的)还是negative(不匹配的)。
为了找到信息量更大的否定词,研究人员采用了硬否定词挖掘策略,在一个batch中具有更高的对比相似度的否定词对更有可能被选来计算损失。
3、语言建模损失(Language Modeling Loss, LM)激活了以图像为基础的文本解码器,其目的是生成给定图像的文本描述。它优化了交叉熵损失,训练模型以自回归的方式最大化文本的概率。
在计算损失时,研究人员采用0.1的标签平滑度(label smoothing)。与其他用于VLP的MLM损失相比,LM损失使模型具有泛化能力,能够将视觉信息转换为连贯的标题。
CapFlit模块
CapFlit模块
研究人员使用标题和过滤(Captioning and Filtering, CapFilt)来提高文本语料库的质量。
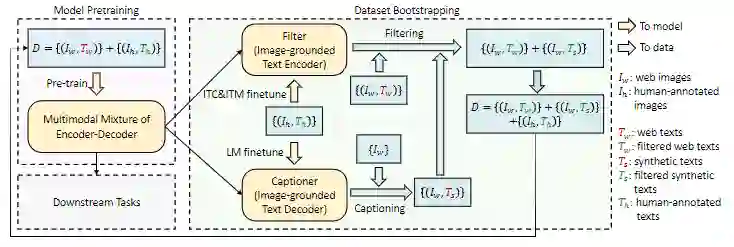
其中包含了两个模块:一个是给定网络图像生成字幕的Captioner,另一个是去除噪声图像-文本对的Filter。
Captioner和Filter都是从同一个预训练的MED模型初始化的,并在COCO数据集上单独进行微调。微调是一个轻量级的程序。
具体来说,Captioner是一个以图像为基础的文本解码器。它以LM为目标进行微调,对给定的图像进行文本解码。给定网络图片Iw,Captioner生成合成captions,即每张图片一个caption。
Filter是一个以图像为基础的文本编码器。它根据ITC和ITM的目标进行微调,以学习文本是否与图像匹配。该Filter去除原始网络文本和合成文本中的噪音文本,如果ITM头预测一个文本与图像不匹配,则该文本被认为是噪音。
最后,研究人员将过滤后的图像-文本对与人工标注的文本对结合起来,形成一个新的数据集用它来预训练一个新模型。
实验结果
实验结果
研究人员对比了在不同数据集上预训练的模型以证明CapFilt在下行任务中的有效性,包括图像-文本检索和图像标题任务,并进行了微调和zero-shot测试。
可以看到,CapFilt可以通过更大的数据集和更大vision backbone来进一步提高性能,也证实了它在数据规模和模型大小方面的可扩展性。
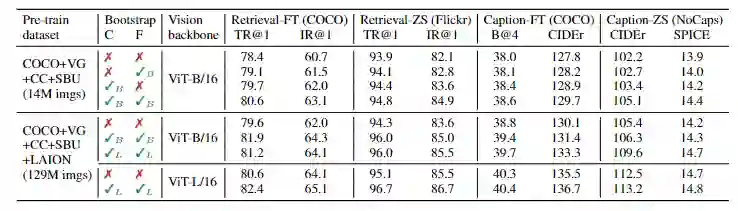
在论文中研究人员还进行了更细致的分析,在广泛的视觉语言任务上取得了最先进的结果,如图像文本检索(平均召回率+2.7%@1)、图像标题(CIDEr+2.8%)和VQA(VQA score+1.6%)。
参考资料:
https://arxiv.org/abs/2201.12086
https://github.com/salesforce/BLIP



