IJCAI 2018 | 腾讯知文等提出新型生成式摘要模型:结合主题信息和强化训练生成更优摘要
选自arXiv
作者:Li Wang、Junlin Yao、Yunzhe Tao、Li Zhong、Wei Liu、Qiang Du
机器之心编译
参与:Panda
让机器能根据文章的主题思想生成人类能够读懂的文本摘要是一个重要的 NLP 研究问题。腾讯知文团队、苏黎世联邦理工学院、哥伦比亚大学和腾讯 AI Lab 的研究者针对这一任务提出了一种引入主题模型和强化学习方法的卷积神经网络方法。该论文已被 IJCAI 2018 接收,机器之心在此进行了摘要介绍。
自动文本摘要在很多不同的自然语言处理(NLP)应用中都发挥着重要的作用,比如新闻标题生成 [Kraaij et al., 2002] 和 feed 流摘要 [Barzilay and McKeown, 2005]。对于文本摘要来说,概括文章的中心思想、信息丰富性、内容代表性等,都是非常重要的。自动文本摘要的关键难题是准确评估摘要结果、选择重要信息、有效地过滤冗余内容、总结相关信息从而得到可读性强的摘要等。与其它 NLP 任务相比,自动文本摘要有自己的难点。比如,不同于机器翻译任务(输入和输出序列通常长度相近),摘要任务的输入和输出序列大都很不平衡。另外,机器翻译任务通常在输入和输出序列之间有一些直接词义层面的对应,这在摘要任务中却没那么明显。
自动摘要技术有两种类型,即抽取式(extraction)和生成式(abstraction)。抽取式摘要 [Neto et al., 2002] 的目标是通过选择源文档中的重要片段并将它们组合来生成摘要;而生成式摘要 [Chopra et al., 2016] 则是根据文档的核心思想来重新组织生成摘要,因此这种摘要的灵活性更高。不同于抽取式摘要,生成式方法能够针对源文档的核心思想重新组织摘要语言,并确保所生成的摘要语法正确且保证可读性;这更接近于人类做摘要的方式,因此也是本论文关注的方法。
近段时间,深度神经网络模型已经在 NLP 任务上得到了广泛应用,比如机器翻译 [Bahdanau et al., 2014]、对话生成 [Serban et al., 2016] 和文本摘要 [Nallapati et al., 2016b]。使用循环神经网络(RNN)[Sutskever et al., 2014] 的基于注意力机制的 sequence to sequence 框架 [Bahdanau et al., 2014] 在 NLP 任务上得到了尤其广泛的应用。但是,基于 RNN 的模型更容易受到梯度消失问题的影响,因为它们具有非线性的链式结构;相比而言,基于 CNN 的模型 [Dauphin et al., 2016] 的结构是分层式的。此外,RNN 的隐藏状态之间的时间依赖也影响了训练过程的并行化,这会使得训练效率低下。
在本论文中,我们提出了一种新方法,该方法基于卷积神经网络的 sequence to sequence 框架(ConvS2S)[Gehring et al., 2017],引入结合主题模型的注意力机制。就我们所知,这是生成式文本摘要中首个采用卷积框架结合联合注意力机制引入主题信息的研究,这能将主题化的和上下文的对齐信息提供到深度学习架构中。此外,我们还通过使用强化学习方法 [Paulus et al., 2017] 对我们提出的模型进行了优化。本论文的主要贡献包括:
我们提出了结合多步注意力机制和带偏置生成机制的方法,将主题信息整合进了自动摘要模型中,注意力机制能引入上下文信息来帮助模型生成更连贯、多样性更强和信息更丰富的摘要。
我们在 ConvS2S 的训练优化中使用了 self-critical 强化学习方法(SCST:self-critical sequence training),以针对文本摘要的指标 ROUGE 来直接优化模型,这也有助于缓解曝光偏差问题(exposure bias issue)。
我们在三个基准数据集上进行了广泛的实验,结果表明引入主题模型和 SCST 强化学习方法的卷积神经网络能生成信息更丰富更多样化的文本摘要,模型在数据集上取得了较好的文本摘要效果。
3 引入强化学习和主题模型的卷积 sequence to sequence 框架
我们提出了引入强化学习和主题模型的卷积 sequence to sequence 模型,其包含词语信息输入和主题信息输入的双路卷积神经网络结构、一种多步联合注意力机制、一种带主题信息偏置的文本生成结构和一个强化学习训练过程。图 1 展示了这种引入主题信息的卷积神经网络模型。
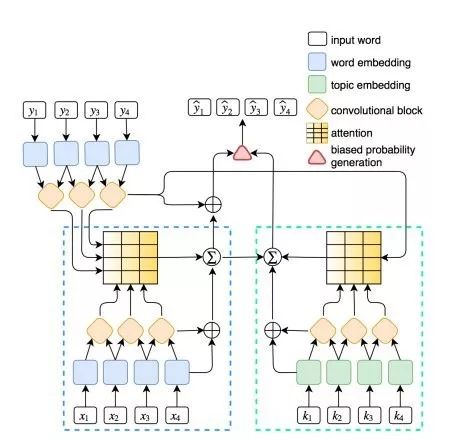
图 1:引入主题信息的卷积神经网络结构示意图。
3.1 ConvS2S 架构
我们使用 ConvS2S 架构 [Gehring et al., 2017] 作为我们的模型的基础架构。在这篇论文中,我们使用了两个卷积模块,分别与词层面和主题层面的 embedding 相关。我们在这一节介绍前者,在后一节介绍后者以及联合注意力机制和带偏置文本生成机制。
3.2 引入主题模型的多步注意力机制
主题模型是一种用于发现源文章集合中出现的抽象主题思想或隐藏语义的统计模型。在本论文中,我们使用了主题模型来获取文档的隐含知识以及将引入主题信息的多步注意力机制集成到 ConvS2S 模型中,这有望为文本摘要提供先验知识。现在我们介绍如何通过联合注意机制和带偏置概率生成过程将主题模型信息引入到基本 ConvS2S 框架中。
5 结果和分析

表 4:模型在 Gigaword 语料库上生成的摘要示例。D:源文档,R:参考摘要,OR:引入强化学习的 ConvS2S 模型的输出,OT:引入主题模型和强化学习的 ConvS2S 模型的输出。蓝色标记的词是参考摘要中没有出现的主题词。红色标记的词是参考摘要和源文档中都没有出现的主题词。
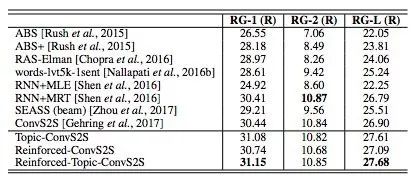
表 5: Rouge 在 DUC-2004 数据集上的准确度分数。在每种分数上的最佳表现用粗体表示。

表 7:模型在中文语料库 LCSTS 上生成的摘要示例。D:源文档,R:参考摘要,OR:引入强化学习的 ConvS2S 模型的输出,OT:引入主题模型和强化学习的 ConvS2S 模型的输出。蓝色标记的词是参考摘要中没有出现的主题词。红色标记的词是参考摘要和源文档中都没有出现的主题词。
论文:一种用于抽象式文本摘要的强化型可感知主题的卷积序列到序列模型(A Reinforced Topic-Aware Convolutional Sequence-to-Sequence Model for Abstractive Text Summarization)

论文链接:https://arxiv.org/pdf/1805.03616.pdf
摘要:在本论文中,我们提出了一种解决自动文本摘要任务的深度学习方法,即将主题信息引入到卷积 sequence to sequence(ConvS2S)模型中并使用 self-critical 强化学习训练方法(SCST)来进行优化。引入词语和主题信息,加入多步注意力机制,我们的方法可以通过带主题偏置的概率生成机制提升所生成摘要的连贯性、多样性和信息丰富性。另一方面,SCST 这样的强化学习训练方法可以根据针对摘要的评价指标 ROUGE 直接优化模型,这也能缓解曝光偏差问题。我们在 Gigaword、 DUC-2004 和 LCSTS 数据集上进行实验评估,结果表明我们提出的方法在生成式摘要上的优越性。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com