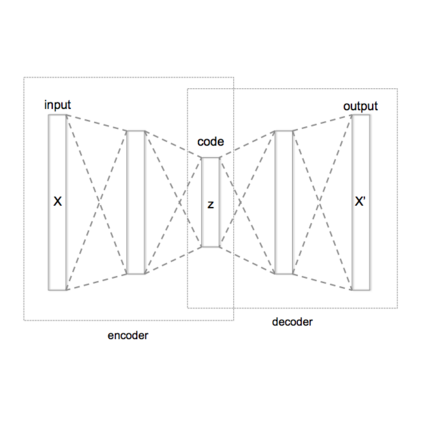
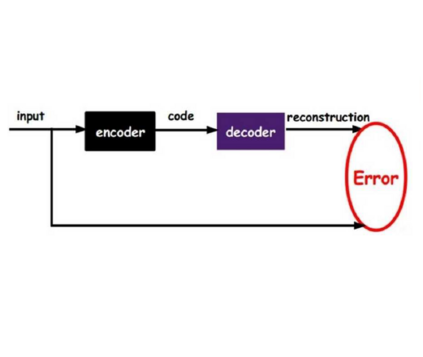
We propose a VAE for Transformers by developing a variational information bottleneck regulariser for Transformer embeddings. We formalise the embedding space of Transformer encoders as mixture probability distributions, and use Bayesian nonparametrics to derive a nonparametric variational information bottleneck (NVIB) for such attention-based embeddings. The variable number of mixture components supported by nonparametric methods captures the variable number of vectors supported by attention, and the exchangeability of our nonparametric distributions captures the permutation invariance of attention. This allows NVIB to regularise the number of vectors accessible with attention, as well as the amount of information in individual vectors. By regularising the cross-attention of a Transformer encoder-decoder with NVIB, we propose a nonparametric variational autoencoder (NVAE). Initial experiments on training a NVAE on natural language text show that the induced embedding space has the desired properties of a VAE for Transformers.
翻译:我们建议为变异器开发一个变异信息瓶颈常规化器,用于变异器嵌入。 我们正式确定变异器编码器的嵌入空间为混合物概率分布,并使用巴伊西亚非参数得出非对等变异信息瓶(NVIB)用于这种以注意力为基础的嵌入。 由非参数方法支持的混合成分的变量数可以捕捉得到注意支持的矢量变量,而我们非参数分布的互换性可以捕捉到注意的变异性。 这使得NVIB能够将可获取的矢量和单个矢量的信息定期化。 通过将变异器编码器-解码器的交叉使用与NVIB常规化,我们建议采用非参数变异自动编码器(NVAE)。 关于自然文字培训NVAE的初步实验显示,导入嵌入空间具有变异器VAE的理想特性。