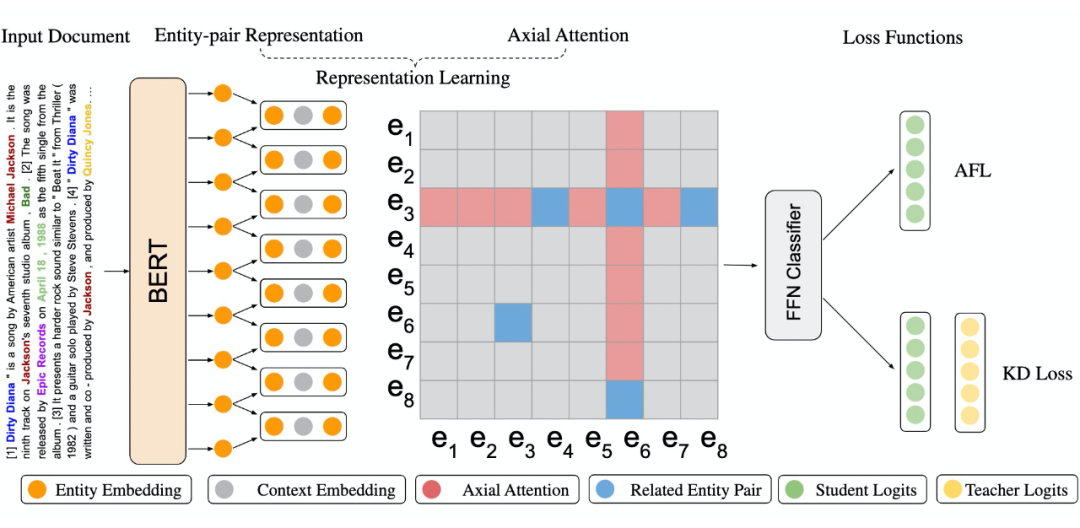
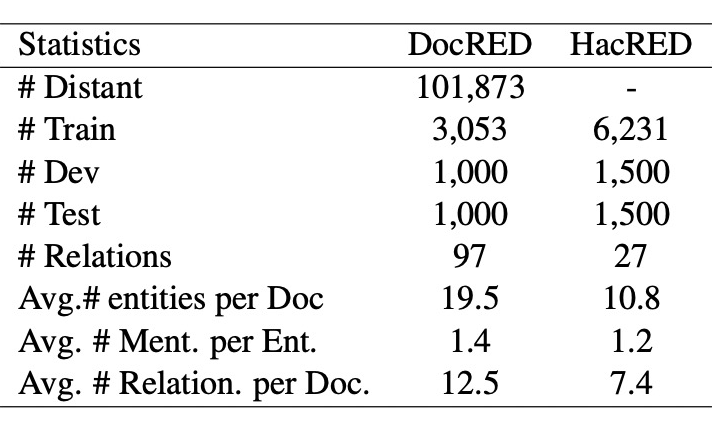
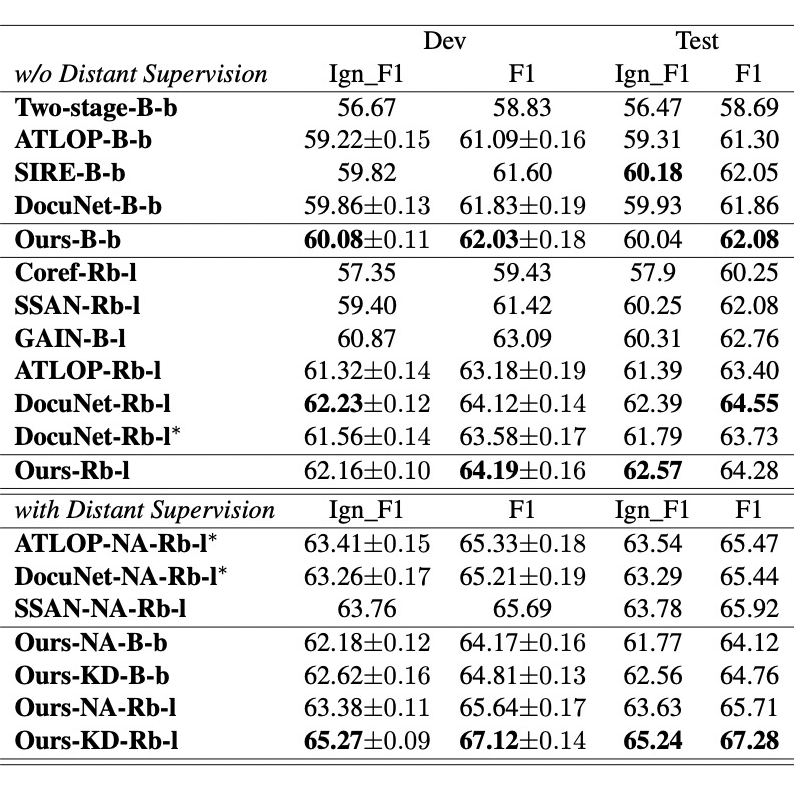
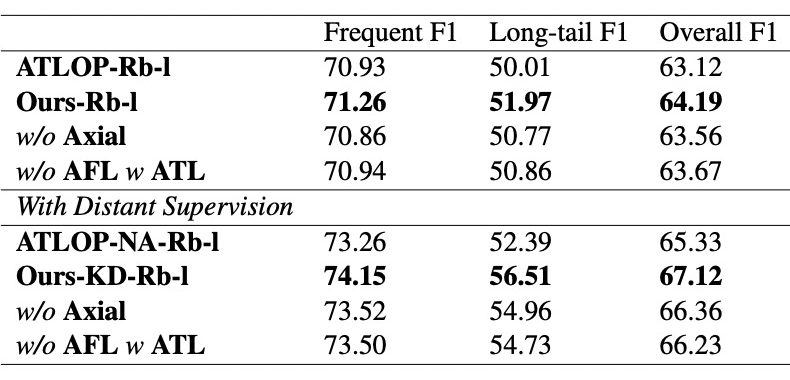
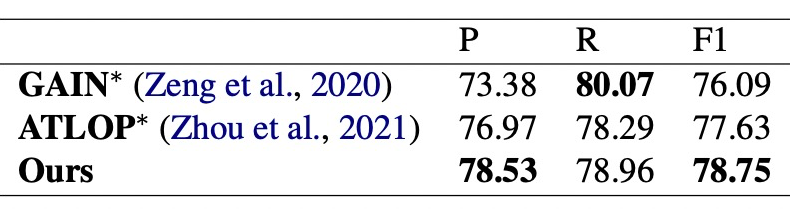
综上所述, 我们提出了一个基于知识蒸馏的半监督学习框架,并且基于轴向注意力和自适应聚焦函数提出了一个新的文档级别关系抽取的模型,并且在 DocRED 排行榜显著超过了 SOTA 的表现。
RelationPrompt:通过提示语言模型的数据生成来解决零样本关系三元组抽取任务 本小节工作来自论文:RelationPrompt: Leveraging Prompts to Generate Synthetic Data for Zero-Shot Relation Triplet Extraction, in ACL Findings 2022.
论文链接:
https://arxiv.org/abs/2203.09101
数据代码:
http://github.com/declare-lab/RelationPrompt
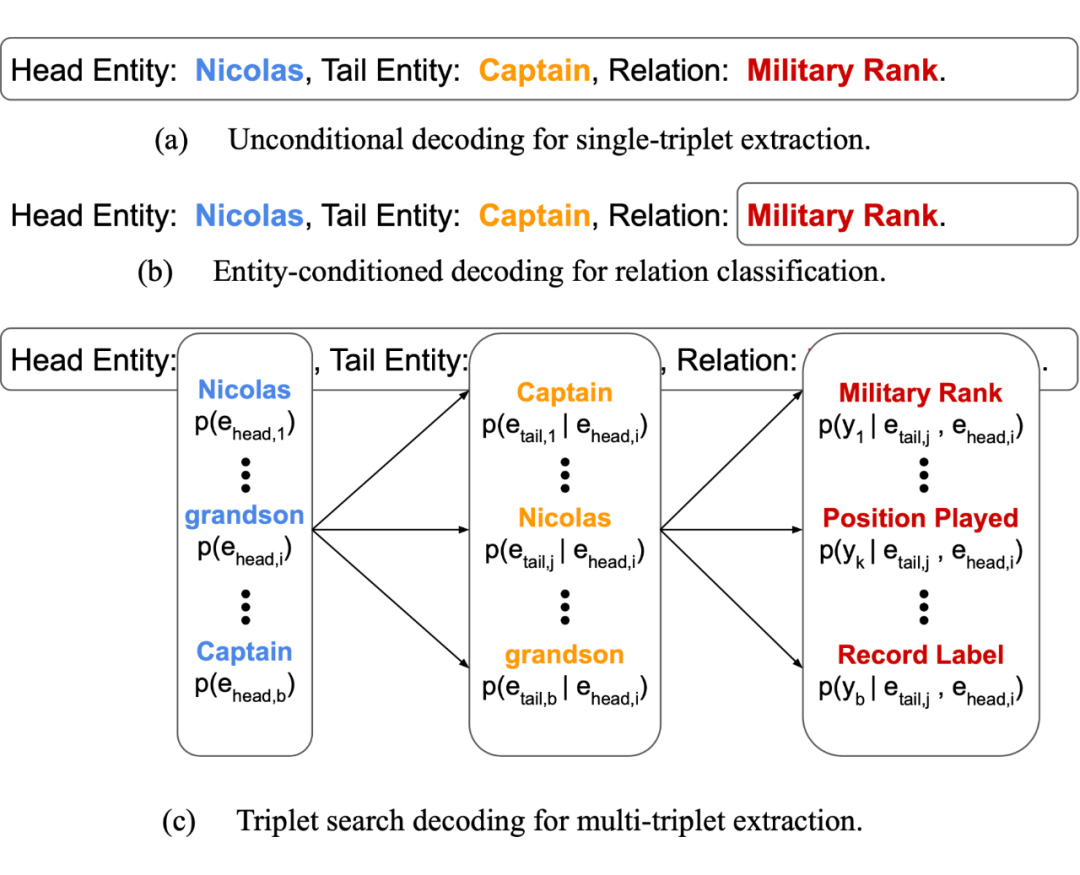
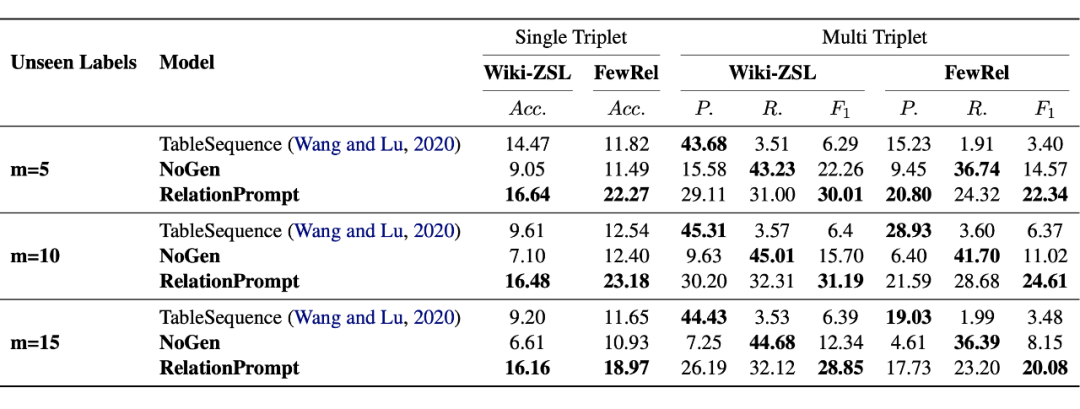
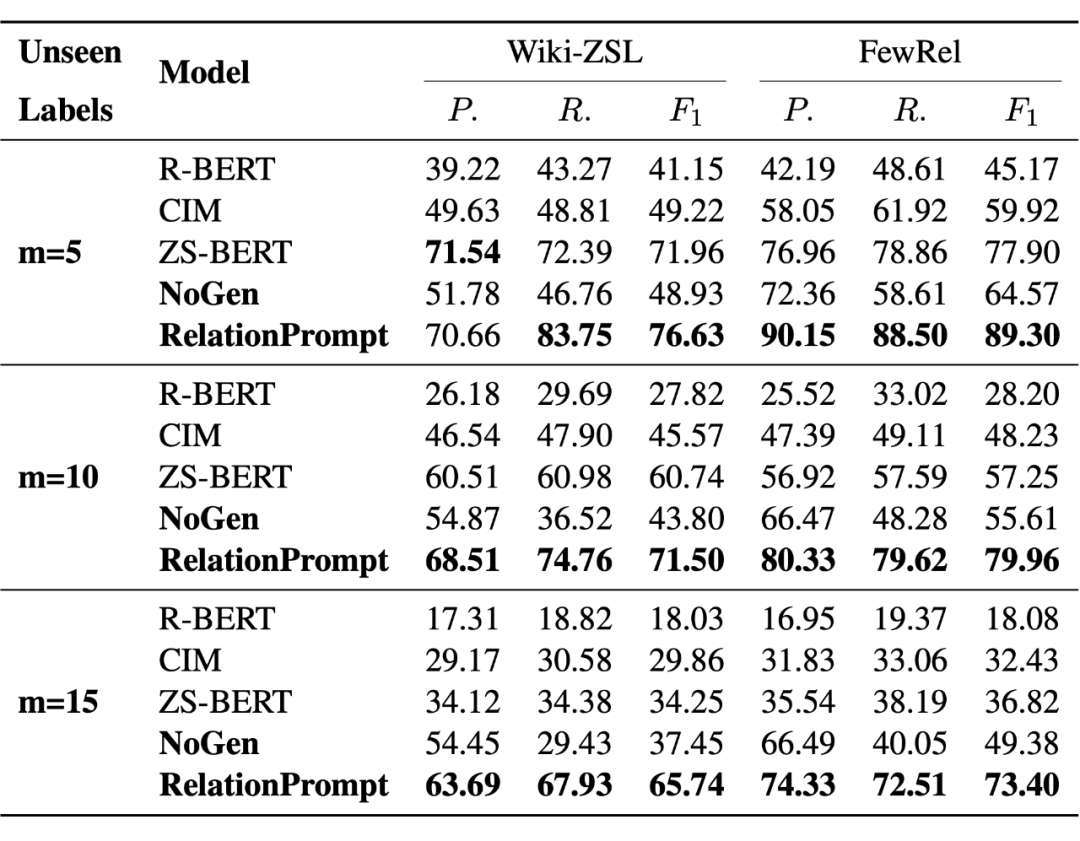
2.1 问题提出 关系三元组是知识库 [9] 的基本组成部分,能应用于搜索、社交网络、事实核查等等。然而,具体地说,现有的模型只能针对训练时候见过的关系类别执行三元组抽取(Relation Triplet Extraction)。因此,我们首次提出零样本关系三元组抽取任务(Zero-Shot Relation Triplet Extraction)(ZeroRTE)。 比如这个句子“Their grandson was Group Captain Nicolas Tindal.” 包含了 “Military Rank”的关系,但是训练数据没有见过这类关系类别的样本。ZeroRTE 的目标就是在这个零样本的情况下仍然能够抽取三元组(Nicolas Tindal,Military Rank, Group Captain)。 为了执行 ZeroRTE,我们提出了RelationPrompt 方式,为没有见过的关系类别生成伪训练数据(Pseudo-training data)。RelationPrompt 能够利用初次见到的关系名作为语言模型的提示(Prompt),生成该关系的结构化句子样本。这类样本的结构信息标明了句子中三元组的头部实体(Head Entity)和尾部实体(Tail Entity),进而可以作为抽取模型的训练数据。
[1] Yao, Yuan, et al. "DocRED: A Large-Scale Document-Level Relation Extraction Dataset." Proceedings of ACL. 2019. [2] Mintz, Mike, et al. "Distant supervision for relation extraction without labeled data." Proceedings of ACL. 2009.[3] Zhou, Wenxuan, et al. "Document-level relation extraction with adaptive thresholding and localized context pooling." Proceedings of AAAI. 2021.[4] Wang, Huiyu, et al. "Axial-deeplab: Stand-alone axial-attention for panoptic segmentation." Proceedings of ECCV. Springer, 2020.[5] Lin, Tsung-Yi, et al. "Focal loss for dense object detection." Proceedings of ICCV. 2017.[6] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 2.7 (2015).[7] Cheng, Qiao, et al. "HacRED: A Large-Scale Relation Extraction Dataset Toward Hard Cases in Practical Applications." Findings of ACL. 2021.[8] Xu, Benfeng, et al. "Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction." Proceedings of the AAAI. 2021.[9] Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning entity and relation embeddings for knowledge graph completion. In Proc. of AAAI. [10] Chih-Yao Chen and Cheng-Te Li. 2021. Zs-bert: To- wards zero-shot relation extraction with attribute representation learning. In Proc. of NAACL.[11] Guoliang Ji, Kang Liu, Shizhu He, and Jun Zhao. 2017. Distant supervision for relation extraction with sentence-level attention and entity descriptions. In Proc. of AAAI.[12] Pushpankar Kumar Pushp and Muktabh Mayank Srivastava. 2017. Train once, test anywhere: Zero-shot learning for text classification. CoRR, arXiv:1712.05972.[13] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021. Pre- train, prompt, and predict: A systematic survey of prompting methods in natural language processing. CoRR, arXiv:2107.13586.[14] Giovanni Paolini, Ben Athiwaratkun, Jason Krone, Jie Ma, Alessandro Achille, Rishita Anubhai, Ci- cero Nogueira dos Santos, Bing Xiang, and Stefano Soatto. 2020. Structured prediction as translation between augmented natural languages. In Proc. of ICLR.[15] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Lan- guage models are unsupervised multitask learners. OpenAI.[16] Mike Lewis, Yinhan Liu, Naman Goyal, Mar- jan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. Bart: Denoising sequence-to-sequence pre- training for natural language generation, translation, and comprehension. In Proc. of ACL.[17] Jue Wang and Wei Lu. 2020. Two are better than one: Joint entity and relation extraction with table- sequence encoders. In Proc. of EMNLP.[18] Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. 2018. Fewrel: A large-scale supervised few-shot relation classifica- tion dataset with state-of-the-art evaluation. In Proc. of EMNLP.