
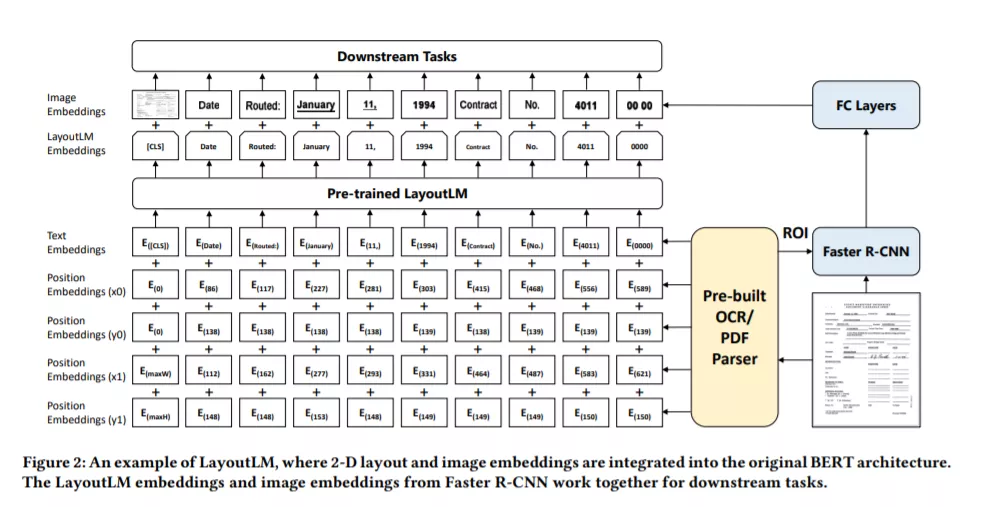
大量的研究成果表明,大规模预训练语言模型通过自监督任务,可在预训练阶段有效捕捉文本中蕴含的语义信息,经过下游任务微调后能有效的提升模型效果。然而,现有的预训练语言模型主要针对文本单一模态进行,忽视了文档本身与文本天然对齐的视觉结构信息。为了解决这一问题,研究员们提出了一种通用文档预训练模型LayoutLM[1][2],选择了文档结构信息(Document Layout Information)和视觉信息(Visual Information)进行建模,让模型在预训练阶段进行多模态对齐。
在实际使用的过程中,LayoutLM 仅需要极少的标注数据即可达到行业领先的水平。研究员们在三个不同类型的下游任务中进行了验证:表单理解(Form Understanding)、票据理解(Receipt Understanding),以及文档图像分类(Document Image Classification)。实验结果表明,在预训练中引入的结构和视觉信息,能够有效地迁移到下游任务中,最终在三个下游任务中都取得了显著的准确率提升。
成为VIP会员查看完整内容
相关内容

专知会员服务
99+阅读 · 2020年7月3日
Arxiv
13+阅读 · 2020年8月11日
Arxiv
4+阅读 · 2020年2月13日
Arxiv
12+阅读 · 2019年9月26日

相关VIP内容
专知会员服务
99+阅读 · 2020年7月3日
相关资讯
相关论文
Arxiv
13+阅读 · 2020年8月11日
Arxiv
4+阅读 · 2020年2月13日
Arxiv
12+阅读 · 2019年9月26日