论文浅尝 - ICML2020 | 对比图神经网络解释器
论文笔记整理:方尹,浙江大学在读博士,研究方向:图表示学习。
Contrastive Graph Neural Network Explanation

动机与贡献
本文主要关注图神经网络的解释性问题,这样的解释有助于提升GNN的可信度,能够更好的理解输入中的哪些部分对预测结果的影响最大。本文主要的贡献有三个:
1)提出了Distribution Compliant Explanation (DCE)主张,要求做模型解释所用到的数据要和训练数据服从相同的分布,即具有一致性;
2)基于DCE,他们提出了一种方法,Contrastive GNN Explanation (CoGE),用于解释GNN在图分类问题中的预测结果;
3)在真实数据集和合成数据集上证明了这种方法的有效性。
相关工作
之前已经有过一些用于解释网络的方法:
1)Occlusion: 它是通过遮挡一个节点或者一条边,通过这样做对预测结果的影响大小,来判断该节点或边的重要性程度。
2)GNNExplainer: 通过最大化预测结果和子图结构之间的互信息,找到最重要的结构和特征。
3)Image attribution methods: 计算每个节点的相关性得分,并把这个相关性得分反向传播到输入层,以得到节点和输入之间的相关性。
DCE主张
以上提到的方法中有一些是基于图像的方法,它们考察的是像素而不是边。如果直接迁移到GNN上来会有一些弊端。直接移除边可能会得到disconnected graph. 而且很小的扰动也会导致图的拓扑结构发生很大的变化,从而导致模型的预测结果的变化,不利于判断到底哪些节点或者边对模型预测起关键性作用。
因此文章中提出,做模型解释的时候用到的数据必须和训练数据的分布具有一致性,而不能使用拓扑结构差异很大的数据。
模型与算法
根据DCE,文章提出了一种对比的方法,一个图的graph embedding远离和它具有不同label的图,靠近和它具有相同label的图,是因为图中某些parts在起作用。
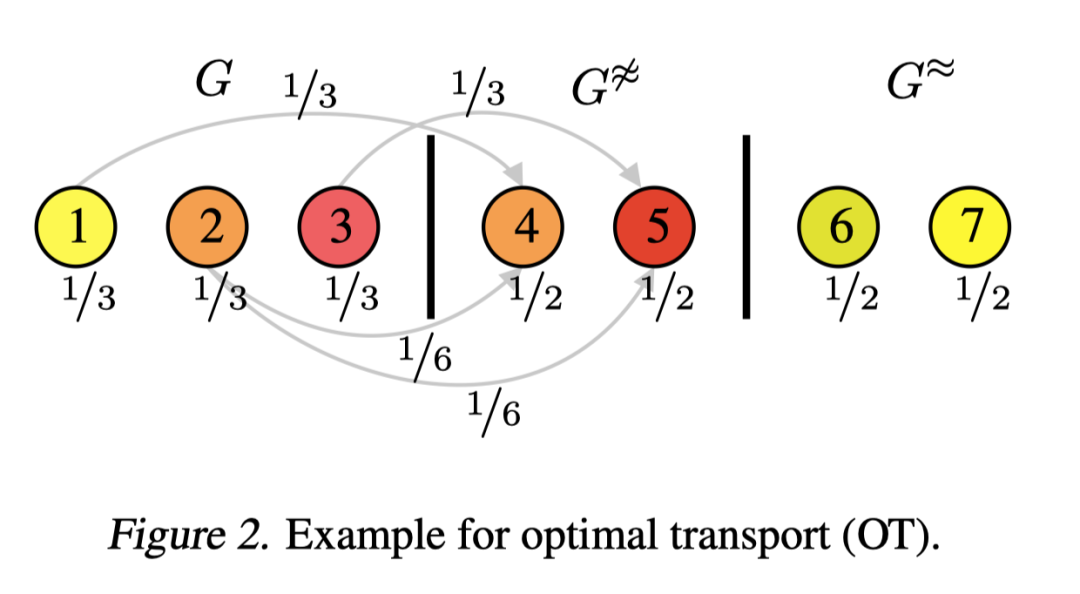
这里用到了最优传输距离OT,图2展示了如何计算第一张图和第二张图之间的OT.首先给每个节点分配了一个权重,并且保证每个图的所有节点的权重之和为1,每个source node都要把自己的权重传输给target nodes, target nodes可以有一个或多个。每一个权重表示它们的最大容量,就是target nodes接收到的权重不能大于它本身的最大容量。一个传输过程的cost是传输权重乘以两节点的表示之间的距离。这里node embedding之间距离用L2距离计算。最优运输就是找到全局的最优权重分配,在这个过程中可能会涉及到某些节点的次优选择,比如图2中,节点2没有把所有权重都传输到节点4,即使他俩的node embedding是相同的,不会有cost. OT使得我们能够在节点的粒度上去对比两个图的表示。
Source node的权重也可以是不相等的,如果要最小化OT,那么在target图中没有对应项的节点的权重就会比较低。如节点2的对应项是4,2有对应项,1和3没有,那么1和3的权重就会比2低。若节点有对应项,source node和target node之间的距离为0,如果要最小化OT,其他source node的权重就会比较低。同理,如果要最大化OT,那么在target图中有对应项的节点的权重就会比较低。(让其他不为0的项更大)
CoGE的基本思想就是同时最大化具有相同label的图之间的OT和最小化不同label的图之间的OT,并寻找其中具有最小权重的那些节点,那些点就是explanation nodes.
第一部分是最大化同一类图之间的OT,又因为在最大化OT时,在target图中有对应项的节点的权重比较低,如图中2的权重比较低,去找其中具有最小权重的节点,就是在找有对应项的节点,相当于在找两个图中的共性,这些节点解释了为什么两个图可以被归为一类;
第二部分是最小化不同类图之间的OT,在最小化OT时,在target图中没有对应项的节点的权重比较低,比如图中1和3,去找其中具有最小权重的节点就是在找没有对应项的节点,相当于在找两个图中的特性,这些节点解释了为什么两个图不是同一类。
CoGE就是要同时做这两件事,可以归纳为公式1:
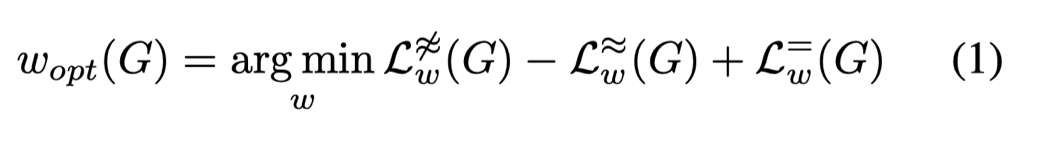
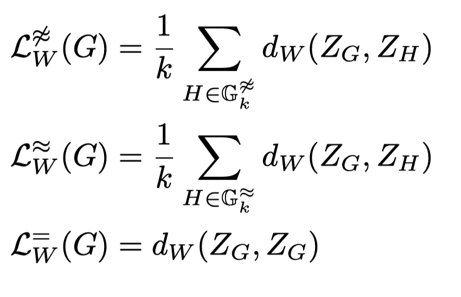
第一项损失,这里d指的是G和H两个不同类别的图之间的OT,其中G是权重不是均等的,H的权重是均等的,计算出G和所有不同类别的图之间的OT,选出其中最相似的k个,取平均;第二项损失是k个最相似的相同类别的图之间OT的平均。因为要最大化同一类图之间的OT,所以第二项损失前面取负号。第三项损失是一个惩罚项,它计算的是G和均等权重的G之间的OT,它惩罚了偏离均等权重的情况,因此会使w只做出有实质性好处的微小调整。
实验与结果
文章在两个用于图形分类的真实数据集上做了explanation:
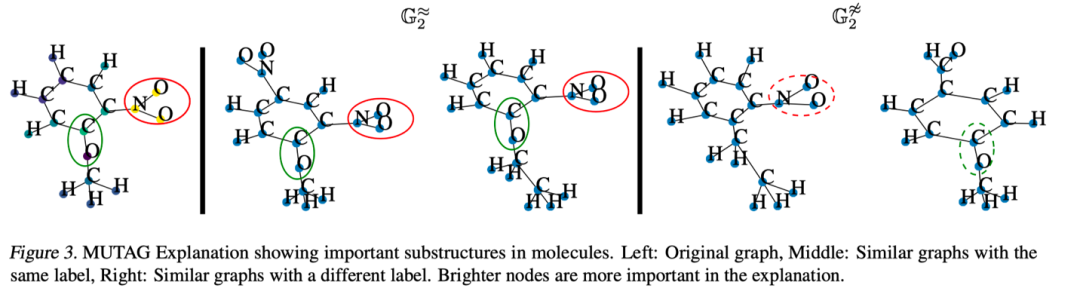
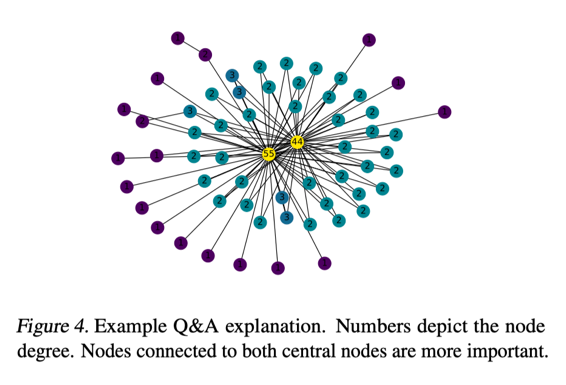
2、REDDIT-BINARY是一个论坛讨论数据集。节点是用户,边是对另一个用户评论的响应,两个label分别为Q&A和discussion。如图4所示,CoGE认为中心节点以及与中心节点相连的节点对分类起重要作用。事实上,Q&A是大多数用户向极少数的专家提问并且得到答复。而Online Discussion具有深度比较大的树状结构。
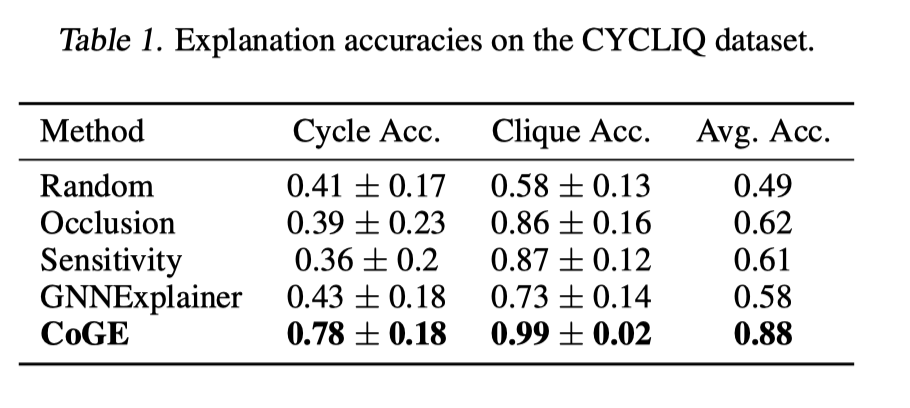
3、本文还在一个合成数据集CYCLIQ上进行了实验。这是一个用于二分类的数据集,它的label是图里是含有环或含有团。这个问题中正确的explanation应是包含在团或者环结构中的边。边的重要性是边两头的节点的重要性之和。
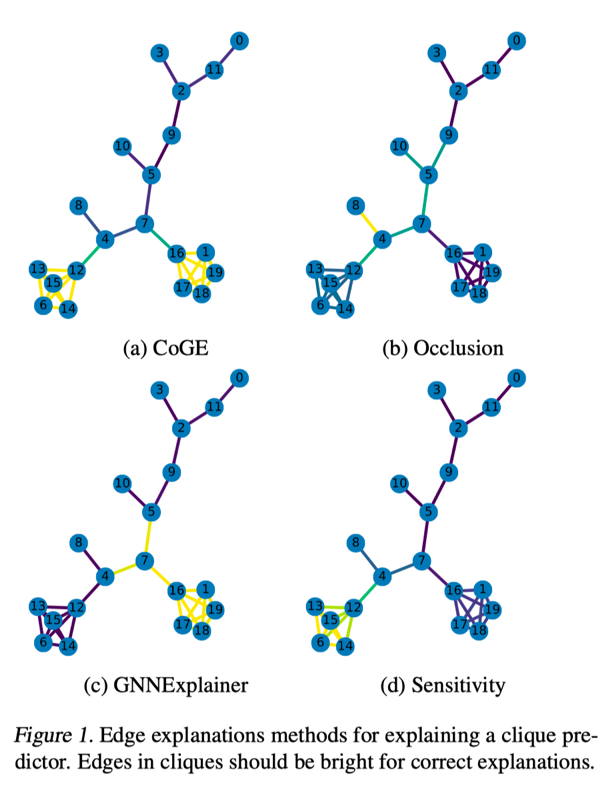
4、explanation的准确性定义如下,用CoGE选出x条最重要的边,找出在这x条边中有多少条在环或者团中,计算两者的比例。实验的baseline是random guessing, 基于节点的occlusion(通过移除或遮挡一些节点,计算它对实验结果的影响),sensitivity analysis(反向传播),GNNExplainer.由表1,解释团的准确率大于解释环的,CoGE产生了最好的结果,对于两种类别来说,准确率都比其他方法高出10%。图1展示了随机抽取的某个示例,CoGE很准确的找到了包含在团中的边。
Ablation Study
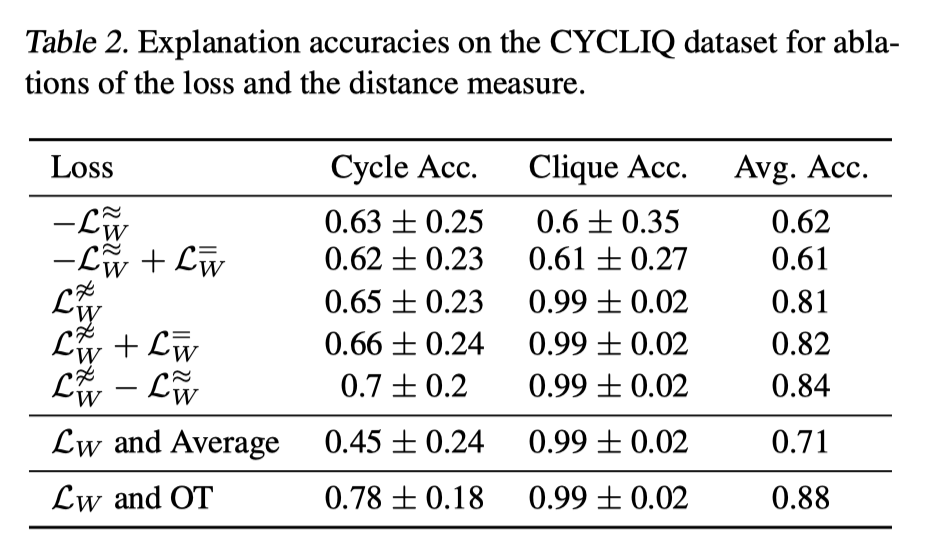
本文又在同样的合成数据集上研究了每个损失项的重要性程度,选择不同的Loss进行实验。对比第一行和第三行可以看到,第一项损失其实具有更多的解释性。在它的基础上,其他两项的加入让它的性能有一定的提高。
除此之外,用欧式距离代替OT距离,计算node embedding的加权平均值之间的欧式距离。这样会导致准确率下降,但还是优于baseline.
Conclusion
1)讨论了GNN的特殊性。图的拓扑结构很重要,少量的修改就会导致图脱离了已知的数据分布。
2)提出了DCE主张:explanation用到的数据应该与训练数据分布保持一致。
3)提出了一种新的解释方法CoGE,它遵循DCE.并且实验结果表明它具有有效性和参数选择的鲁棒性。
4)Future work: 将该方法扩展到node classification上,更深入的理解explanation和对抗攻击之间的联系。
欢迎有兴趣的同学阅读原文。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。

