

摘要——大型语言模型(LLMs)的快速发展加剧了对高效机制的需求,以将连续的多模态数据转换为适用于语言处理的离散表示。离散标记化(Discrete Tokenization),以向量量化(Vector Quantization, VQ)为核心方法,兼具计算效率与对LLM架构的良好适配性。尽管其重要性日益凸显,目前尚缺乏系统梳理VQ技术在LLM背景下应用的全面综述。本文填补了这一空白,首次提出了面向LLM的离散标记化方法的结构化分类体系与系统分析。我们归纳了8种具有代表性的VQ变体,涵盖经典与现代范式,剖析其算法原理、训练机制及在LLM流程中的集成挑战。除算法层面的探讨外,本文还从三类典型应用出发进行研究综述:非LLM的传统场景、基于LLM的单模态系统,以及基于LLM的多模态系统,重点分析量化策略如何影响对齐(alignment)、推理(reasoning)与生成(generation)性能。此外,我们还指出当前面临的关键挑战,如码本崩溃(codebook collapse)、梯度估计不稳定以及模态特定的编码约束等。最后,本文讨论了若干新兴研究方向,包括动态与任务自适应量化、统一的标记化框架,以及受生物机制启发的码本学习方法。本综述旨在搭建传统向量量化与现代LLM应用之间的桥梁,为构建高效且具有泛化能力的多模态系统提供基础性参考。本文的持续更新版本可访问:https://github.com/jindongli-Ai/LLM-Discrete-Tokenization-Survey。
关键词——离散标记化,向量量化(VQ),多模态,大型语言模型(LLMs)。
https://arxiv.org/abs/2507.22920 1 引言
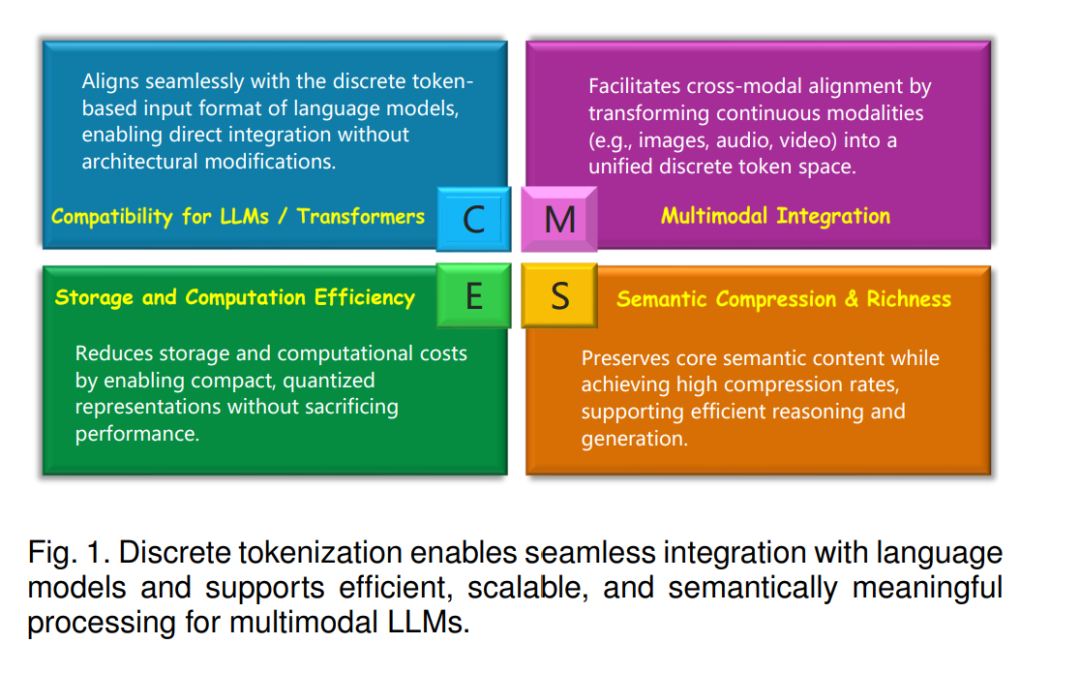
近年来,大型语言模型(LLMs)[30, 50, 52, 141, 149, 150, 232] 的飞速发展显著改变了机器理解与生成自然语言的方式。这些模型在语言理解与生成方面表现出卓越能力,推动其在众多应用场景中的广泛部署。随着研究的持续推进,学术界和工业界愈发关注将LLM的能力从文本扩展到多模态数据,例如图像 [62, 276]、音频 [33, 59] 和视频 [81, 87],这也带来了在统一异构模态方面的全新挑战。 基于向量量化(Vector Quantization, VQ)的离散标记化(Discrete Tokenization)已成为应对这些挑战的关键技术,在多模态LLM系统中展现出显著优势 [19, 100]。如图1所示,该技术通过将高维连续输入转换为紧凑的离散标记,使非文本模态能够以语言模型固有的标记结构进行处理。这种设计不仅通过压缩提升了计算效率,同时保留了对跨模态推理至关重要的语义粒度。正因如此,离散标记化已成为多个最先进多模态LLM系统中的核心组件。 尽管离散标记化的重要性日益增强,现有综述在覆盖范围与技术深度方面仍显不足。一些早期的综述工作 [9, 92, 142, 188, 221] 多聚焦于LLM兴起之前的研究内容,已难以适应当前快速演进的AI研究格局。近期虽有部分工作对多模态学习系统进行了较广泛综述 [77],但对量化技术的处理仍流于表面。其他综述则受限于狭窄的应用范围,仅覆盖特定模态或任务。例如,Lin等人 [102] 针对图结构数据的量化方法进行了详尽分析,但其方法难以推广到其他领域;又如 [111] 专注于推荐系统中的表示效率与质量,而 [56] 则聚焦于语音的离散表示学习。这种碎片化与缺乏跨模态整合的问题,给设计通用LLM多模态系统的研究者带来了不小的挑战。 为此,本文系统性地探讨了基于VQ的离散标记化方法,旨在更深入地理解其在克服当前多模态LLM系统局限性中的作用。我们的分析将标记化设计选择与LLM集成的关键需求(如保持标记对齐、确保量化表示中有效的梯度传播)联系起来。通过在统一分析框架下考察主流模态的应用情况,本综述弥补了现有文献中缺乏横向比较的不足。此外,本文还明确指出当前实现中存在的主要挑战,并提供可行的技术见解,以提升量化质量和系统鲁棒性。本文结构如图2所示,主要贡献如下: * 提出了一套全面的分类体系,按照码本学习范式与LLM集成适配性对现有离散标记化方法进行组织; * 回顾了非LLM场景下的代表性应用,揭示其设计原则如何为构建面向LLM的模态特定标记化策略提供启发; * 提供了细致的模态级分析,比较了LLM系统中不同数据类型下的离散标记化方法; * 识别了当前技术中的关键挑战,并指出未来研究方向,包括缓解码本崩溃、实现动态与自适应量化的策略等。
