【导读】机器学习顶会 NeurIPS 2020, 是人工智能领域全球最具影响力的学术会议之一,因此在该会议上发表论文的研究者也会备受关注。据官方统计,今年NeurIPS 2020 共收到论文投稿 9454 篇,接收 1900 篇(其中 oral 论文 105 篇、spotlight 论文 280 篇),论文接收率为 20.1%。近期,所有paper list 放出,小编发现**对比学习(Contrastive Learning)**相关的投稿paper很多,这块研究方向这几年受到了学术界的广泛关注,并且在CV、NLP等领域也应用颇多。
为此,这期小编为大家奉上NeurIPS 2020必读的七篇对比学习相关论文——对抗自监督对比学习、局部对比学习、难样本对比学习、多标签对比预测编码、自步对比学习、有监督对比学习
NeurIPS 2020 Accepted Papers:https://neurips.cc/Conferences/2020/AcceptedPapersInitial
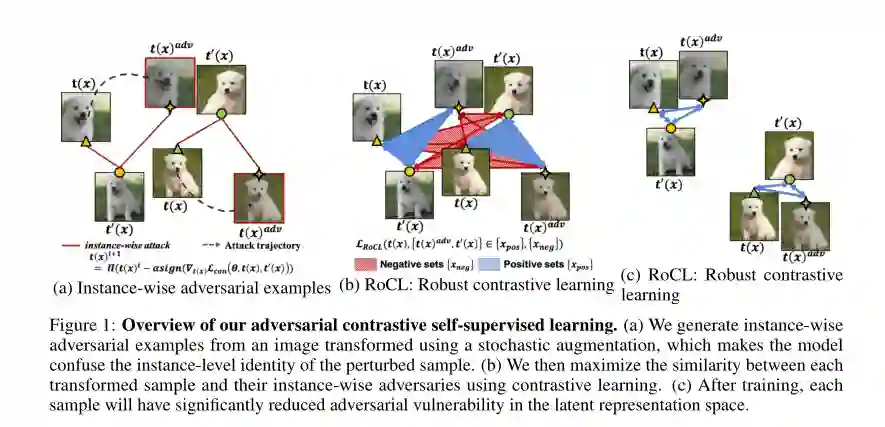
1. Adversarial Self-Supervised Contrastive Learning
作者: Minseon Kim, Jihoon Tack, Sung Ju Hwang
摘要: 现有的对抗性学习方法大多使用类别标签来生成导致错误预测的对抗性样本,然后使用这些样本来增强模型的训练,以提高鲁棒性。虽然最近的一些工作提出了利用未标记数据的半监督对抗性学习方法,但它们仍然需要类别标签。然而,我们真的需要类别标签来进行反向的深度神经网络的健壮训练吗?本文提出了一种新的针对未标记数据的对抗性攻击,使得该模型混淆了扰动数据样本的实例级身份。此外,我们还提出了一种自监督对比学习(Contrastive Learning)框架来对抗性地训练未标记数据的鲁棒神经网络,其目的是最大化数据样本的随机扩充与其实例对抗性扰动之间的相似度。我们在多个基准数据集上验证了我们的方法-鲁棒对比学习(RoCL),在这些数据集上,它获得了与最新的有监督对抗性学习方法相当的鲁棒准确率,并且显著地提高了对黑盒和不可见类型攻击的鲁棒性。此外,与单独使用自监督学习相比,RoCL进一步结合有监督对抗性损失进行联合微调,获得了更高的鲁棒精度。值得注意的是,RoCL在稳健的迁移学习方面也显示出令人印象深刻的结果。
网址: https://arxiv.org/abs/2006.07589
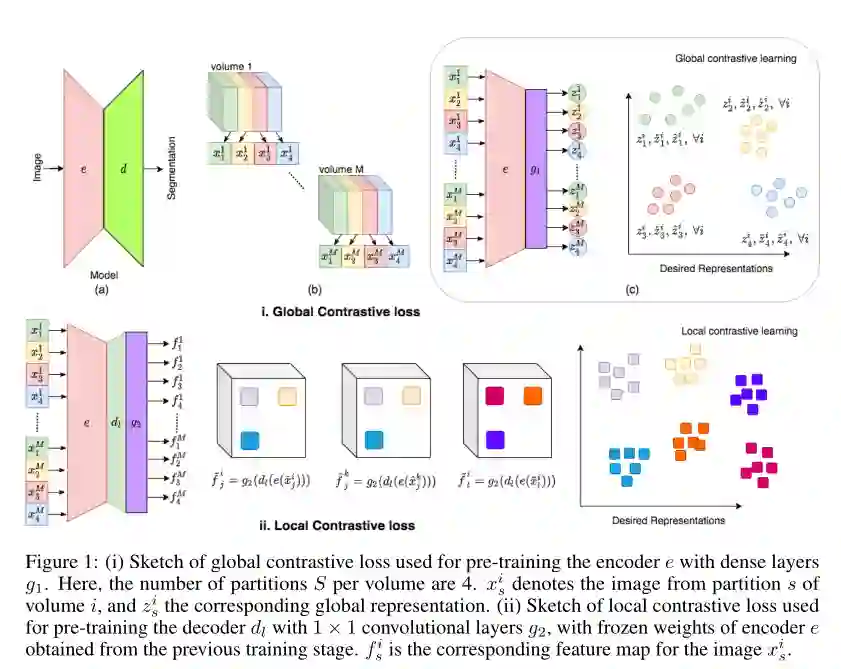
2. Contrastive learning of global and local features for medical image segmentation with limited annotations
作者: Krishna Chaitanya, Ertunc Erdil, Neerav Karani, Ender Konukoglu
摘要: 有监督深度学习成功的一个关键要求是一个大的标记数据集——这是医学图像分析中难以满足的条件。自监督学习(SSL)可以在这方面提供帮助,因为它提供了一种用未标记的数据预训练神经网络的策略,然后用有限的样本标注对下游任务进行微调。对比学习是SSL的一种特殊变体,是一种学习图像级表征的强大技术。在这项工作中,我们提出了一种策略,通过利用领域内一些特点,在标注有限的半监督场景下来扩展volumetric 医疗图像分割的对比学习框架。具体地,我们提出了:(1)新颖的对比策略,它利用volumetric 医学图像之间的结构相似性(领域特定线索);(2)对比损失的局部信息来学习对每个像素分割有用的局部区域的独特表示(问题特定线索)。我们在三个磁共振成像(MRI)数据集上进行了广泛的评估。在有限的标注环境下,与其他的自监督和半监督学习技术相比,本文提出的方法有了很大的改进。当与简单的数据增强技术相结合时,该方法仅使用两个标记的MRI体积用于训练,达到基准性能的8%以内,相当于用于训练基准的训练数据ACDC的4%。
网址: https://arxiv.org/abs/2006.10511
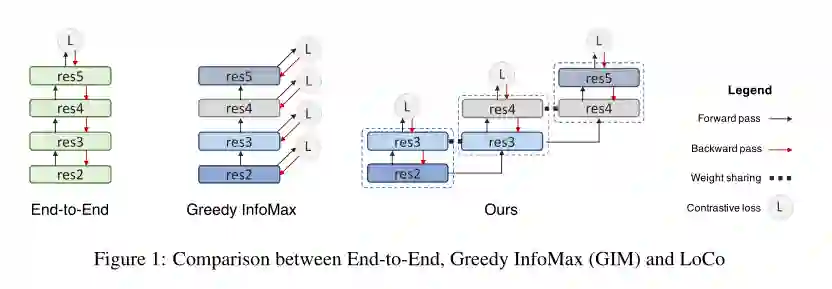
3. LoCo: Local Contrastive Representation Learning
作者: Yuwen Xiong, Mengye Ren, Raquel Urtasun
摘要: 深度神经网络通常执行端到端反向传播来学习权重,该过程在跨层的权重更新步骤中创建同步约束(synchronization constraints),并且这种约束在生物学上是不可信的。无监督对比表示学习的最新进展指出一个问题,即学习算法是否也可以是局部的,即下层的更新不直接依赖于上层的计算。虽然Greedy InfoMax分别学习每个块的局部目标,但我们发现,在最新的无监督对比学习算法中,可能是由于贪婪的目标以及梯度隔离,会一直损害readout的准确性。在这项工作中,我们发现,通过重叠局部块堆叠在一起,我们有效地增加了解码器的深度,并允许较高的块隐式地向较低的块发送反馈。这种简单的设计首次缩小了局部学习算法和端到端对比学习算法之间的性能差距。除了标准的ImageNet实验,我们还展示了复杂下游任务的结果,例如直接使用readout功能进行对象检测和实例分割。
网址: https://arxiv.org/abs/2008.01342
4. Hard Negative Mixing for Contrastive Learning
作者: Yannis Kalantidis, Mert Bulent Sariyildiz, Noe Pion, Philippe Weinzaepfel, Diane Larlus
摘要: 对比学习已成为计算机视觉中自监督学习方法的重要组成部分。通过学习将同一图像的两个增强版本相互靠近地图像嵌入,并将不同图像的嵌入分开,可以训练高度可迁移的视觉表示。最近的研究表明,大量的数据增强和大量的负样本集对于学习这样的表征都是至关重要的。同时,无论是在图像层面还是在特征层面,数据混合策略都通过合成新的示例来改进监督和半监督学习,迫使网络学习更健壮的特征。在这篇文章中,我们认为对比学习的一个重要方面,即hard negatives的影响,到目前为止被忽视了。为了获得更有意义的负样本,目前最流行的对比自监督学习方法要么大幅增加batch sizes大小,要么保留非常大的内存库;然而,增加内存需求会导致性能回报递减。因此,我们从更深入地研究一个表现最好的框架开始,并展示出证据,为了促进更好、更快的学习,需要更难的难样本(harder negatives)。基于这些观察结果,并受到数据混合策略成功的激励,我们提出了特征级别的难例混合策略,该策略可以用最小的计算开销在运行中进行计算。我们在线性分类、目标检测和实例分割方面对我们的方法进行了详尽的改进,并表明使用我们的难例混合过程提高了通过最先进的自监督学习方法学习的视觉表示的质量。
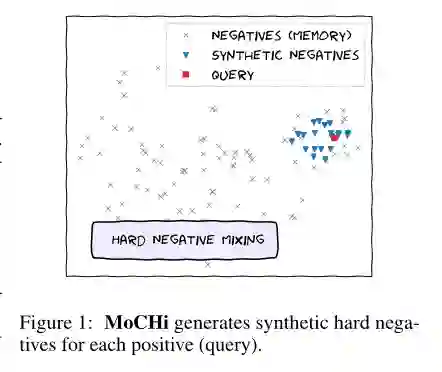
代码: https://europe.naverlabs.com/mochi
网址: https://arxiv.org/abs/2010.01028
5. Multi-label Contrastive Predictive Coding
作者: Jiaming Song, Stefano Ermon
摘要: 变量互信息(mutual information, MI)估计器广泛应用于对比预测编码(CPC)等无监督表示学习方法中。MI的下界可以从多类分类问题中得到,其中critic试图区分从潜在联合分布中提取的正样本和从合适的建议分布中提取的(m−1)个负样本。使用这种方法,MI估计值超过log m,因此有效下界可能会严重低估,除非m非常大。为了克服这一局限性,我们引入了一种新的基于多标签分类问题的估计器,其中critic需要同时联合识别多个正样本。我们证明了在使用相同数量的负样本的情况下,多标签CPC能够超过log m界,同时仍然是互信息的有效下界。我们证明了所提出的方法能够带来更好的互信息估计,在无监督表示学习中获得经验上的改进,并且在13个任务中超过了最先进的10个知识提取方法。
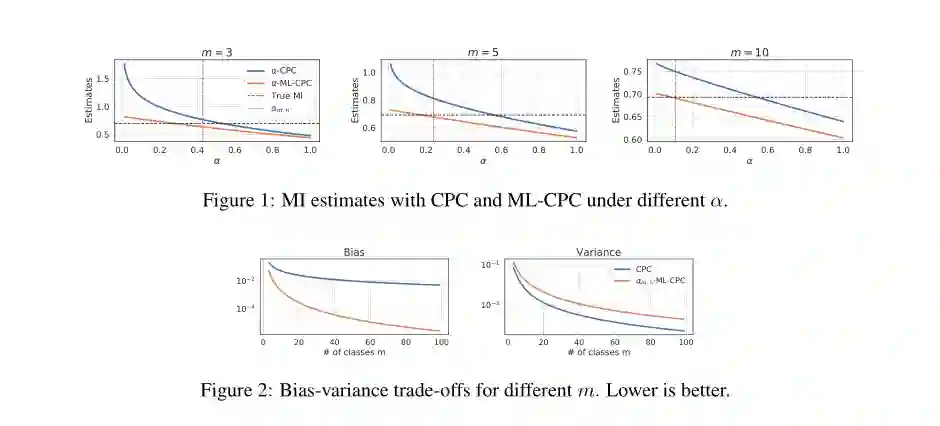
网址:
https://arxiv.org/abs/2007.09852
6. Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID
作者: Yixiao Ge, Feng Zhu, Dapeng Chen, Rui Zhao, Hongsheng Li
摘要: 域自适应目标Re-ID旨在将学习到的知识从已标记的源域转移到未标记的目标域,以解决开放类(open-class)的重识别问题。虽然现有的基于伪标签的方法已经取得了很大的成功,但是由于域的鸿沟和聚类性能的不理想,它们并没有充分利用所有有价值的信息。为了解决这些问题,我们提出了一种新的具有混合记忆的自适应对比学习框架。混合存储器动态地生成用于学习特征表示的源域类级、目标域簇级和未聚类实例级监督信号。与传统的对比学习策略不同,该框架联合区分了源域类、目标域簇和未聚类实例。最重要的是,所提出的自适应方法逐渐产生更可靠的簇来提炼混合记忆和学习目标,这被证明是我们方法的关键。我们的方法在目标 Re-ID的多域适配任务上的性能优于现有技术,甚至在源域上不需要任何额外的标注就能提高性能。在Market1501和MSMT17数据上,我们的无监督目标Re-ID的通用版本分别比最先进的算法高出16.7%和7.9%。

代码: https://github.com/yxgeee/SpCL
网址: https://arxiv.org/abs/2006.02713
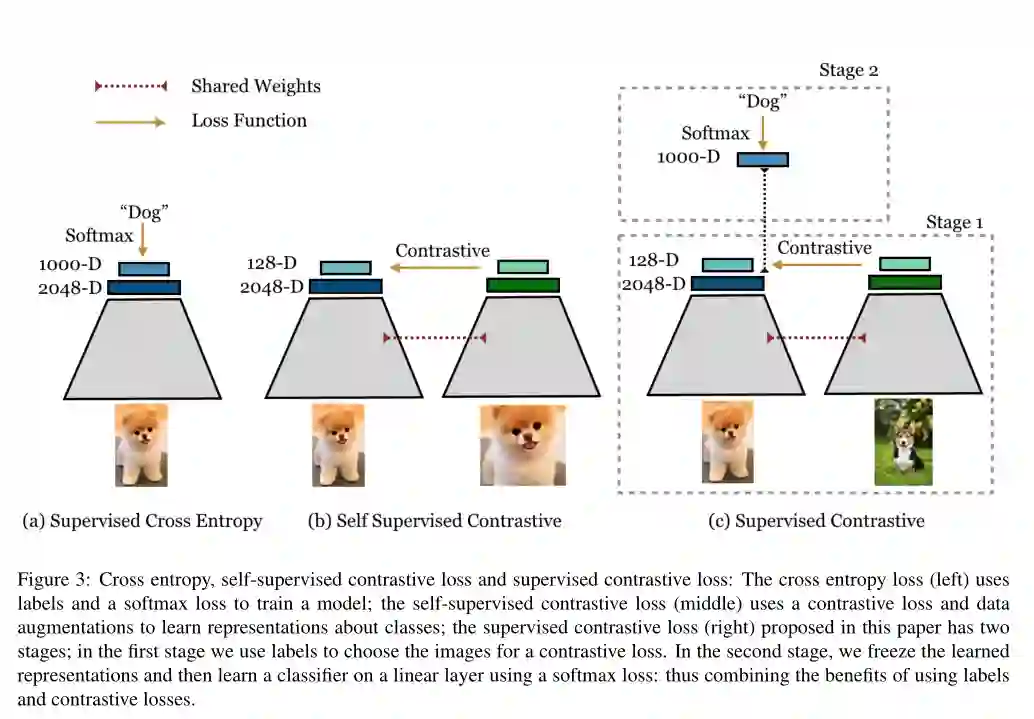
7. Supervised Contrastive Learning
作者: Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, Dilip Krishnan
摘要: 交叉熵是图像分类模型监督训练中应用最广泛的损失函数。在本文中,我们提出了一种新的训练方法,该方法在不同的体系结构和数据增强的监督学习任务中始终优于交叉熵。我们修正了批量对比损失,它最近被证明在自监督环境下学习强大的表示是非常有效的。因此,我们能够比交叉熵更有效地利用标签信息。属于同一类的点簇在嵌入空间中被拉在一起,同时推开来自不同类的样本簇。除此之外,我们还利用了大的batch sizes和标准化嵌入等关键因素,这些因素已被证明有利于自监督学习。在ResNet-50和ResNet-200上,我们的性能都比交叉熵高出1%以上,在使用 AutoAugment数据增强的方法中创造了78.8%的新技术水平。在校准和准确度方面,这一损失也显示出在标准基准上对自然损坏的稳健性有明显的好处。与交叉熵相比,我们的监督对比损失对诸如优化器或数据增强等超参数设置更稳定。