GraphSAGE: GCN落地必读论文

来源 | NIPS17
导读:图卷积网络(Graph Convolutional Network,简称GCN)最近两年大热,取得不少进展。作为 GNN 的重要分支之一,很多同学可能对它还是一知半解。PinSAGE( PinSage: 第一个基于 GCN 的工业级推荐系统)为 GCN 落地提供了实践经验,而本文是 PinSAGE 的理论基础,同样出自斯坦福,是 GCN 非常经典和实用的论文。
1. 概括
在大规模图上学习节点 embedding ,在很多任务中非常有效,如学习节点拓扑结构的 DeepWalk 以及同时学习邻居特征和拓扑结构的 semi-GCN 。
但是现在大多数方法都是直推式学习, 不能直接泛化到未知节点。这些方法是在一个固定的图上直接学习每个节点 embedding ,但是大多情况图是会演化的,当网络结构改变以及新节点的出现,直推式学习需要重新训练(复杂度高且可能会导致 embedding 会偏移),很难落地在需要快速生成未知节点embedding的机器学习系统上。
本文提出归纳学习— GraphSAGE(Graph SAmple and aggreGatE) 框架,通过训练聚合节点邻居的函数(卷积层),使 GCN 扩展成归纳学习任务,对未知节点起到泛化作用。
直推式 ( transductive ) 学习:从特殊到特殊,仅考虑当前数据。在图中学习目标是学习目标是直接生成当前节点的 embedding,例如 DeepWalk、LINE,把每个节点 embedding 作为参数,并通过 SGD 优化,又如 GCN,在训练过程中使用图的拉普拉斯矩阵进行计算。
归纳 ( inductive ) 学习:平时所说的一般的机器学习任务,从特殊到一般:目标是在未知数据上也有区分性。
2.GraphSAGE框架
本文提出 GraphSAGE 框架的核心是如何聚合节点邻居特征信息,本章先介绍 GraphSAGE 前向传播过程(生成节点 embedding ),不同的聚合函数设定;然后介绍无监督和有监督的损失函数以及参数学习。
2.1 前向传播
a. 可视化例子:下图是 GraphSAGE 生成目标节点(红色)embededing 并供下游任务预测的过程:
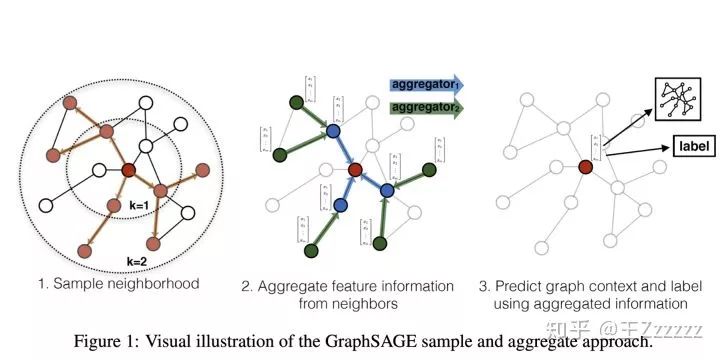
先对邻居随机采样,降低计算复杂度(图中一跳邻居采样数=3,二跳邻居采样数=5)
生成目标节点 emebedding:先聚合 2 跳邻居特征,生成一跳邻居 embedding ,再聚合一跳邻居embedding,生成目标节点embedding,从而获得二跳邻居信息。(后面具体会讲)。
将 embedding 作为全连接层的输入,预测目标节点的标签。
b. 伪代码:

4-5 行是核心代码,介绍卷积层操作:聚合与节点v相连的邻居(采样)k-1 层的 embedding,得到第 k 层邻居聚合特征 


2.2 聚合函数
伪代码第 5 行可以使用不同聚合函数,本小节介绍五种满足排序不变量的聚合函数:平均、GCN 归纳式、LSTM、pooling 聚合器。(因为邻居没有顺序,聚合函数需要满足排序不变量的特性,即输入顺序不会影响函数结果)
a.平均聚合:先对邻居 embedding 中每个维度取平均,然后与目标节点embedding 拼接后进行非线性转换。

b. 归纳式聚合:直接对目标节点和所有邻居 emebdding 中每个维度取平均(替换伪代码中第5、6行),后再非线性转换:

c. LSTM 聚合:LSTM 函数不符合“排序不变量”的性质,需要先对邻居随机排序,然后将随机的邻居序列 embedding 
d. Pooling 聚合器:先对每个邻居节点上一层 embedding 进行非线性转换(等价单个全连接层,每一维度代表在某方面的表示(如信用情况)),再按维度应用 max/mean pooling ,捕获邻居集上在某方面的突出的/综合的表现 以此表示目标节点 embedding 。

2.3 无监督和有监督损失设定
损失函数根据具体应用情况,可以使用基于图的无监督损失和有监督损失。
a. 基于图的无监督损失:希望节点 u 与“邻居”v 的 embedding 也相似(对应公式第一项),而与“没有交集”的节点 
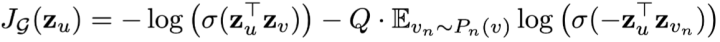
为节点 u 通过 GraphSAGE 生成的 embedding 。
节点 v 是节点 u 随机游走访达“邻居”。
表示负采样:节点
是从节点u的负采样分布
采样的,Q 为采样样本数。
embedding 之间相似度通过向量点积计算得到


b. 有监督损失:无监督损失函数的设定来学习节点 embedding 可以供下游多个任务使用,若仅使用在特定某个任务上,则可以替代上述损失函数符合特定任务目标,如交叉熵。
2.4 参数学习
通过前向传播得到节点 u 的 embedding 

3.实验
3.1 实验目的
比较 GraphSAGE 相比 baseline 算法的提升效果;
比较 GraphSAGE 的不同聚合函数。
3.2 数据集及任务
Citation 论文引用网络(节点分类)
Reddit web 论坛 (节点分类)
PPI 蛋白质网络 ( graph 分类)
3.3 比较方法
随机分类器
手工特征(非图特征)
deepwalk(图拓扑特征)
deepwalk+手工特征
GraphSAGE 四个变种 ,并无监督生成 embedding 输入给 LR 和端到端有监督
(分类器均采用 LR )
3.4 GraphSAGE 设置
K=2,聚合两跳内邻居特征
S1=25,S2=10:对一跳邻居抽样 25 个,二跳邻居抽样 10 个
RELU 激活单元
Adam 优化器
对每个节点进行步长为 5 的 50 次随机游走
负采样参考 word2vec,按平滑 degree 进行,对每个节点采样 20 个。
保证公平性:所有版本都采用相同的 minibatch 迭代器、损失函数、邻居抽样器。
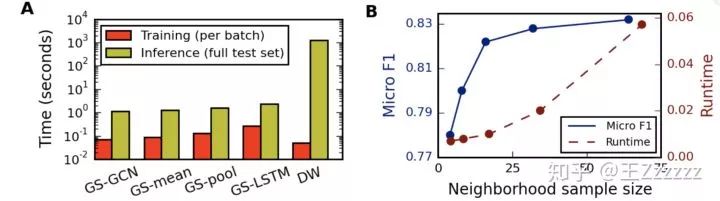
3.5 运行时间和参数敏感性
计算时间:下图A中 GraphSAGE 中 LSTM 训练速度最慢,但相比DeepWalk,GraphSAGE 在预测时间减少 100-500 倍(因为对于未知节点,DeepWalk 要重新进行随机游走以及通过 SGD 学习 embedding )
邻居抽样数量:下图 B 中邻居抽样数量递增,边际收益递减(F1),但计算时间也变大。平衡 F1 和计算时间,将 S1 设为 25 。
聚合K跳内信息:在 GraphSAGE, K=2 相比 K=1 有 10-15% 的提升;但将 K 设置超过 2 ,边际效果上只有 0-5% 的提升,但是计算时间却变大了 10-100 倍。
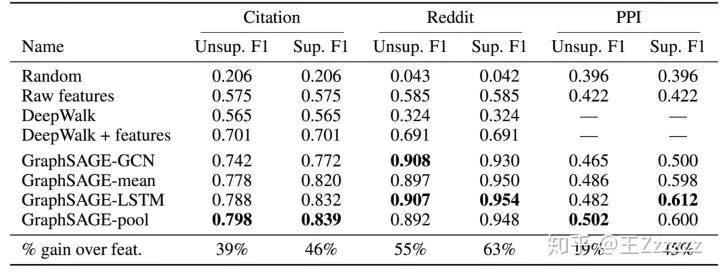
3.6 效果
GraphSAGE 相比 baseline 效果大幅度提升
GraphSAGE 有监督版本比无监督效果好。
LSTM 和 pool 的效果较好
原文链接:https://zhuanlan.zhihu.com/p/62750137
(*本文为 AI科技大本营转载文章,转载请联系作者)
◆
精彩推荐
◆


社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五 更新学习资源、技术福利,还有抽奖活动~

最前沿:堪比E=mc2,Al-GA才是实现AGI的指标性方法论
1万+字原创读书笔记,机器学习的知识点全在这篇文章里
开源之战
别再造假数据了,来试试Faker这个库吧!
国外大神制作的超棒NumPy可视化教程
突发!Python再次第一,Java和C下降,凭什么?
白话中台战略:中台是个什么鬼?
伟创力回应扣押华为物资;谷歌更新图片界面;Python 3.8.0b3 发布 | 极客头条
沃尔玛也要发币了,Libra忙活半天为他人做了嫁衣?