题目: 鲁棒的跨语言知识图谱实体对齐
会议: KDD 2020
论文地址: https://dl.acm.org/doi/pdf/10.1145/3394486.3403268
代码地址: https://github.com/scpei/REA
推荐理由: 这篇论文首次提出了跨语言实体对齐中的噪音问题,并提出了一种基于迭代训练的除噪算法,从而进行鲁棒的跨语言知识图谱实体对齐。本工作对后续跨语言实体对齐的去噪研究具有重要的开创性意义。
跨语言实体对齐旨在将不同知识图谱中语义相似的实体进行关联,它是知识融合和知识图谱连接必不可少的研究问题,现有方法只在有干净标签数据的前提下,采用有监督或半监督的机器学习方法进行了研究。但是,来自人类注释的标签通常包含错误,这可能在很大程度上影响对齐的效果。因此,本文旨在探索鲁棒的实体对齐问题,提出的REA模型由两个部分组成:噪声检测和基于噪声感知的实体对齐。噪声检测是根据对抗训练原理设计的,基于噪声感知的实体对齐利用图神经网络对知识图谱进行建模。两个部分迭代进行训练,从而让模型去利用干净的实体对来进行节点的表示学习。在现实世界的几个数据集上的实验结果证明了提出的方法的有效性,并且在涉及噪声的情况下,此模型始终优于最新方法,并且在准确度方面有显著提高。
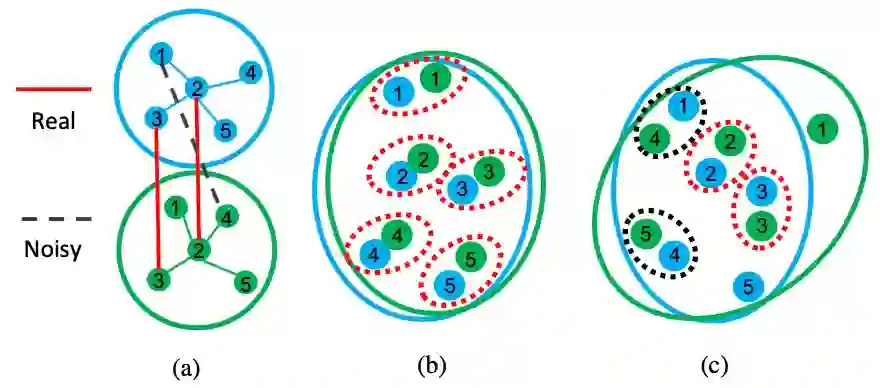
1 引言 现有方法在进行跨语言实体对齐时没有考虑噪音问题,而这些噪音可能会损害模型的效果。如图1所示,(a)中的两个不同语言的知识图谱存在实体对噪音(虚线表示的实体对1-4),(b)是理想状况下节点在特征空间中的表示,可以看出不同语言知识图谱中具有相似语义的实体在特征空间中也相近。(c)是利用含有噪音的训练数据得到的节点特征表示,由于噪音的存在,节点的表示存在了一定的偏差。我们希望跨语言实体对齐是鲁棒性的,即使训练数据中存在噪音,模型也能尽量减少噪音的消极影响,得到如图(b)中的表示。为了克服现有的跨语言实体对齐方法在处理带噪标签实体对时存在的局限性,本文探讨了如何将噪声检测与实体对齐模型结合起来,以及如何共同训练它们以对齐不同语言知识图谱中的实体。