详解Facebook AI 小样本学习技术突破FSL,向更有效学习的类人人工智能迈进

有害的内容可以迅速发展——无论是由当前的事件推动的,还是由寻找新方法来逃避我们系统的人推动的——而人工智能系统与之一起发展,至关重要。然而,人工智能要学会如何去寻找,往往要花上数月的时间,才能收集并标记数以千计,甚至数以百万计的必需实例,以便让每一个人工智能系统都能发现一种新类型的内容。
为了克服这一瓶颈,我们构建和部署了一种名为 Few-Shot Learner(FSL)的新型人工智能技术,它能够在数星期之内,而非数个月之内,针对新的或者不断变化的、有害的内容类型采取行动。它不但可以用于 100 多种语言,还可以从各种数据中学习,比如图像和文本。它可以加强已部署的现有人工智能模型,从而检测其他类型的有害内容。
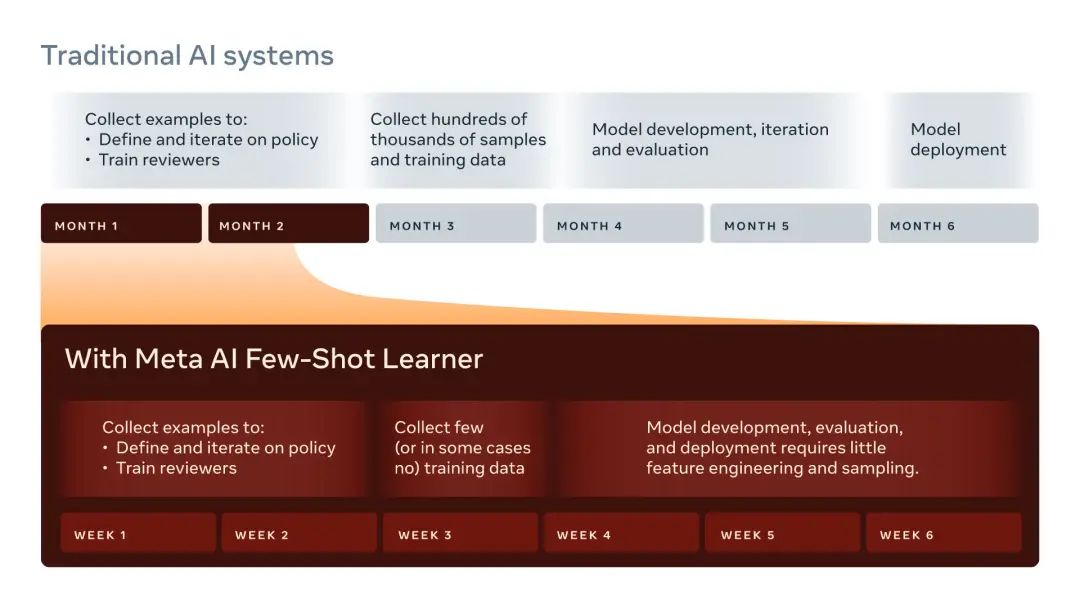
这种新的人工智能系统使用了一种相对较新的方法,称为“小样本学习”(few-shot learning),即模型通过大量的、一般性的理解,再通过少量的、在某些情况下为零的标记样本,来学习新任务。如果说传统的系统类似于可以钓上某种鱼类的鱼线,那么 FSL 就是一张额外的渔网,可以捕捞其他鱼类。
近来的科技突破,例如我们的 自监督学习技术 以及 新型超效率的基础设施,使得这个领域从 传统的、定制的人工智能系统 转向更大、更综合、更通用的系统,减少对标记数据的依赖。首先,它从数以十亿计的通用和开源语言样本上进行训练。接着,我们用多年来标记的违反策略的内容和 边界内容 对人工智能系统进行了训练。最后,对解释新策略的压缩文本进行了训练。与以往依靠标记数据进行模式匹配的系统不同,FSL 是基于通用语言以及违反策略和边界内容语言进行预训练的,因此它可以隐式地学习策略文本。
我们已经在一些相对较新的事件上测试了 FSL。举例来说,最近的一项任务就是,识别分享误导性或耸人听闻的信息的内容,其方式很可能会阻止新冠肺炎疫苗的接种(例如,“疫苗或 DNA 改变器?”)。在另一项独立的任务中,新的人工智能系统对现有的分类器进行了改进,标记出接近煽动暴力的内容(例如,“那家伙需要所有的牙齿吗?”)。传统的方法可能会漏掉这类煽动性帖子,因为没有太多标记的样本使用 DNA 的语言来制造疫苗恐慌,或者引用牙齿来暗示暴力。
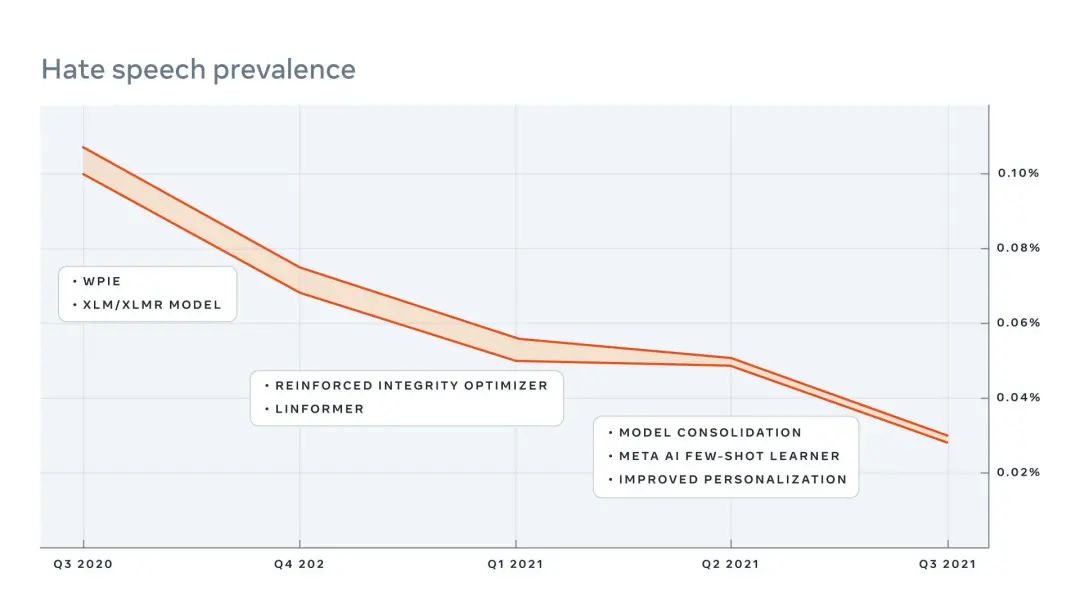
为了测量这个模型的性能,我们制定了一个标准的离线和在线 A/B 测试协议。这些测试中,在 Facebook 和 Instagram 上应用 FSL 前后,我们对有害内容的流行率(即人们看到的违规内容的浏览比例)进行了研究。Meta AI Few-shot Learner 可以准确地检测那些在传统系统中漏掉的帖子,并且有助于降低这类有害内容的流行。它通过主动检测潜在的有害内容,从而阻止其在我们的平台上扩散。我们也发现,FSL 与现有的分类器相结合,有助于降低诸如 仇恨言论 等其他有害内容的泛滥。
我们还在做更多的实验,来改善能够从更多标记的数据中获益的分类器,例如,在没有大量标记训练数据的语言的国家中,我们会继续对这些新的违反内容模式进行测试。当然,这些都是智能、通用的人工智能的雏形。
在人工智能可以读懂几十页的策略文本,并且立刻就能明确地了解它的具体实施方法之前,要实现这一目标,任重而道远。我们一直在推动人工智能技术的发展,并尽快进行部署,以更好地服务于我们的社区,我们相信 FSL 将会是一个非常有前途的发展。
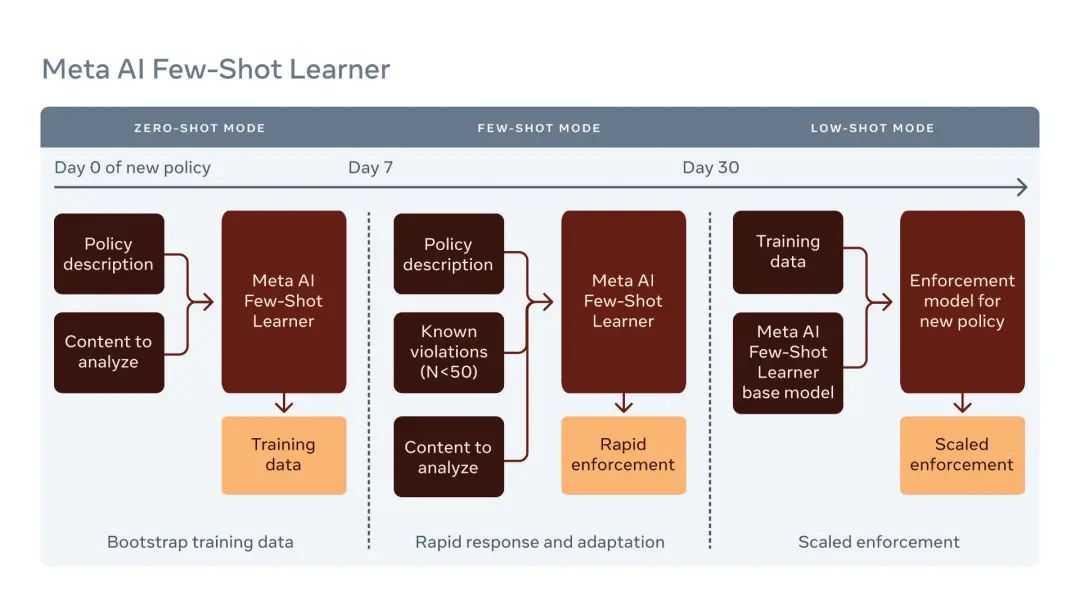
Few-Shot Learner 是一个大规模、多模态、多语言、零样本或小样本的模型,可以理解联合策略和内容,可以在不调整模型的情况下,对完整性问题进行概括。我们正在积极开展研究,以训练使用简单的策略语句而非数百个有标记的样本的模型。
我们的新系统在三种不同的场景下工作,每个场景都需要不同级别的标记的样本:
零样本:没有样本的策略描述。
有示范的小样本:有少量样本的策略描述(少于 50 个)。
带有微调的小样本:机器学习开发者可以在 FSL 的基础模型上进行微调,训练的样本数量很少。
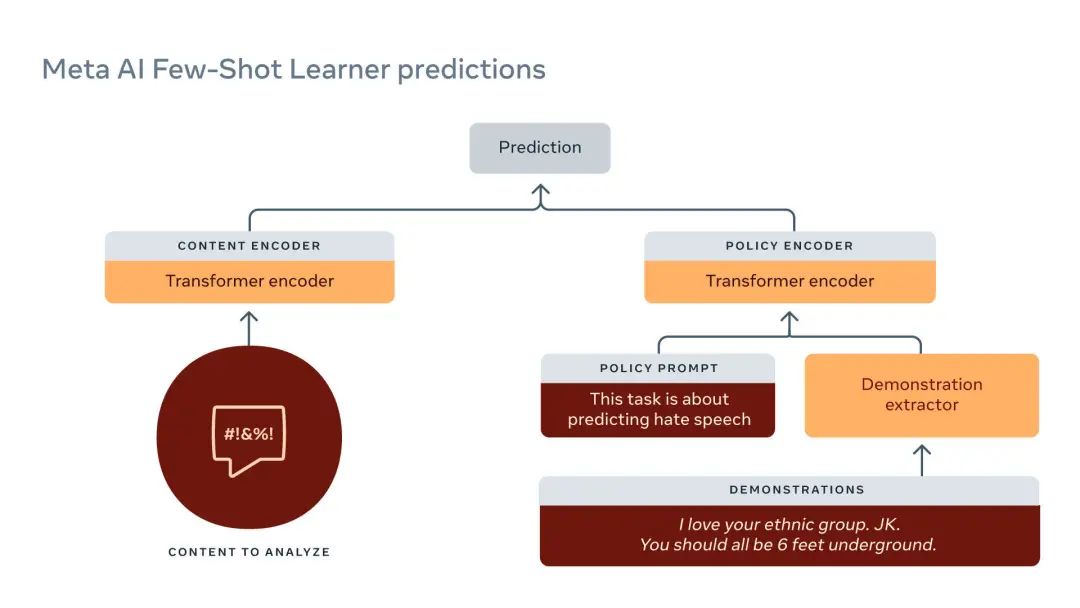
FSL 的整体投入由三部分组成。首先,在我们以前使用整帖的完整性嵌入(Whole Post Integrity Embeddings,WPIE)的工作基础上,它从整个帖子中学习多模态信息,包括文本、图像、URL 等。第二,它分析与策略相关的信息,如策略的定义,或表明某一特定帖子是否违反该策略定义的有标签的样本。第三,如果有的话,我们还采取额外的标记样本作为示范。
作为我们的新方法的一部分,即所谓的 Entailment Few-Shot Learning,其关键思想是将类别标签转换成可用于描述标签的自然语言句子,并确定该例子是否蕴含标签描述。例如,我们可以重新表述一个明显的情感分类输入和标签对。
[x : “我爱你的种族。JK。你们都应该去死。”y : 积极] 作为下面的文本蕴含样本:
[x : 我爱你的种族。JK。你们都应该去死。这是仇恨言论。y : 积极]。
我们将我们提出的方法与目前已有的一些最先进的小样本学习方法进行了比较。经过一系列的系统评估,我们发现我们的方法比各种最先进的小样本学习方法高出 55%(平均为 12%)。在 这里:https://arxiv.org/pdf/2104.14690.pdf ,可以阅读我们研究论文的全部细节。
自动执行之间的差距
我们相信,随着时间的推移,FSL 可以提高我们所有的完整性人工智能系统的性能,让它们利用单一的、共享的知识库和主干来处理许多不同类型的违规行为。但是,它也可以帮助人们在策略、标签和调查工作流方面,弥补人类洞察力和分类器进步之间的差距。
FSL 可用来检测出一组新的可能的策略违规行为,并理解所提出的定义的合理性和有效性。它投下了一张更广泛的网,浮现出更多类型的“几乎”内容违规,策略团队在决定或制定训练新分类器的注释者,以及帮助保持我们平台安全的人类审查员的规模指导时,应该了解这些内容。由于它扩展迅速,从策略制定到执行的时间将缩短几个数量级。
能够迅速开始对没有大量标记的训练数据的内容类型进行强制执行是向前迈出的一大步,这将有助于使我们的系统更加灵活,并对新出现的挑战作出反应。
小样本学习和零样本学习是我们一直在进行重大研究投资的许多前沿人工智能领域之一。而且我们没有看到对生产管道的研究放缓的迹象。我们正致力于一些重要的开放研究,这些研究问题不仅要了解内容,还要从文化、行为和对话环境中推理。
虽然还需要完成大量的工作,但是,这些初期的生产成果已经成为了一个具有里程碑意义的标志,它将会向一个更智能、更通用的人工智能系统过渡,能够在同一时间内完成多种任务。
我们的长远目标是,实现类似人类的学习灵活性和效率性,让我们的完整性系统更快、更容易训练,并能更好地处理新信息。像 Few-Shot Learner 这样的可教人工智能系统可以大幅提高我们检测和适应新情况的能力的敏捷性。通过更快、更准确地识别不断演变的有害内容,FSL 有望成为一项关键的技术,帮助我们继续发展和解决我们平台上的有害内容。
原文链接:
https://ai.facebook.com/blog/harmful-content-can-evolve-quickly-our-new-ai-system-adapts-to-tackle-it

你也「在看」吗?👇



