OpenAI科学家一文详解自监督学习

新智元报道
新智元报道
来源:kguttag
编辑:张佳、鹏飞
【新智元导读】本文中,OpenAI机器人科学家介绍了自监督学习。自监督学习为以监督学习提供了巨大的机会,可以更好地利用未标记数据。这篇文章涵盖了关于图像,视频和控制问题的自我监督学习任务的许多有趣的想法。来新智元 AI 朋友圈和AI大咖们一起讨论吧。
自监督学习为监督学习方式提供了巨大的机会,可以更好地利用未标记的数据。这篇文章涵盖了关于图像、视频和控制问题的自监督学习任务的许多有趣想法。
对于给定任务,使用足够的数据标签,监督学习可以很好地解决问题。要想实现良好的性能,通常需要相当数量的数据标记,但是收集手工标记数据的成本很高(如ImageNet),并且难以扩展。
考虑到未标记的数据量(例如,免费文本,网上的所有图像)远远超过了数量有限的人类标记的数据集,对这些数据弃置不用是一种很大的浪费。但是,无监督学习并不容易,并且通常比监督学习效率低得多。
如果我们可以免费获得未标记数据,并以监督方式训练无监督数据集,应该如何做?可以通过一种特殊的形式来安排有监督的学习任务,使其仅依赖剩余的信息来预测一部分信息,从而实现训练目标。这就是所谓的自监督学习。
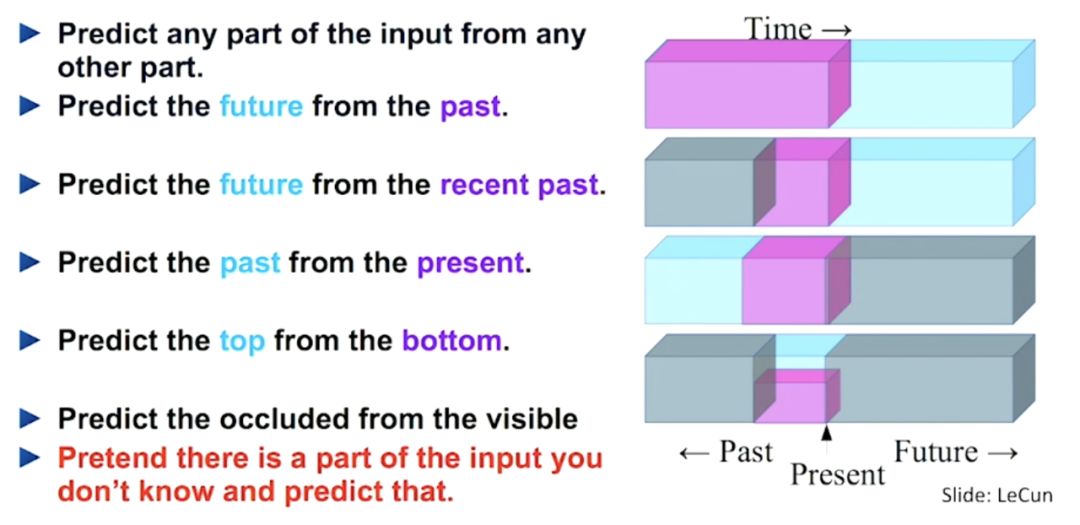
自监督学习使我们能够免费利用数据附带的各种标签。用干净的标签生产数据集很昂贵,但未标记的数据却无时无刻不在产生。为了利用大量的未标记数据,一种方法是正确设置学习目标,以便从数据本身获得监督。
提到自监督任务(也称为pretext任务)就要提到监督损失函数。但是,我们通常不关心任务的最终执行情况;而只对学习的中间表示感兴趣,我们期望这些中间表示可以涵盖良好的语义或结构含义,并且能够有益于各种下游的实际任务。
广义上讲,所有生成模型都可以被认为是自监督的,只不过目标不同:生成模型侧重于创建各种逼真的图像,而自监督的表示学习的侧重点是如何产生对多个任务有用的良好特征。
对于图像的自监督表示学习,已经提出了许多想法。常见的工作流程是在一个或多个带有未标记图像的pretext任务上训练模型,然后使用该模型的一个中间特征层,为ImageNet分类提供多项逻辑回归分类器。
最近,一些研究人员提议在标记数据上训练监督学习,在未标记数据上使用共享权重,并同时训练自监督的pretext任务。
失真
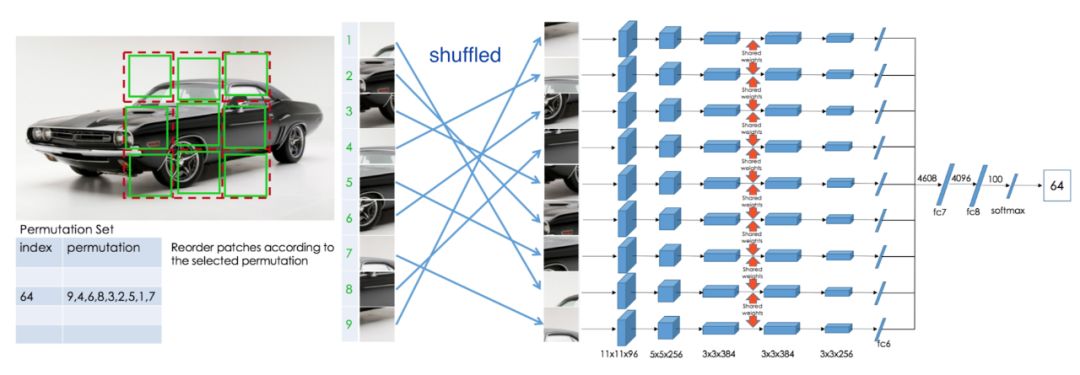
我们期望图像上的轻微失真不会改变其原始语义或几何形式。带有轻微失真的图像可以认为与原始图像相同,因此预计学习到的特征并不会失真。使用Exemplar-CNN创建带有未标记图像补丁的替代训练数据集。
 上图:一只可爱的鹿的原始补丁在左上角。应用随机变换,导致各种失真的补丁。在pretext任务中,所有这些都应归为同一类
上图:一只可爱的鹿的原始补丁在左上角。应用随机变换,导致各种失真的补丁。在pretext任务中,所有这些都应归为同一类
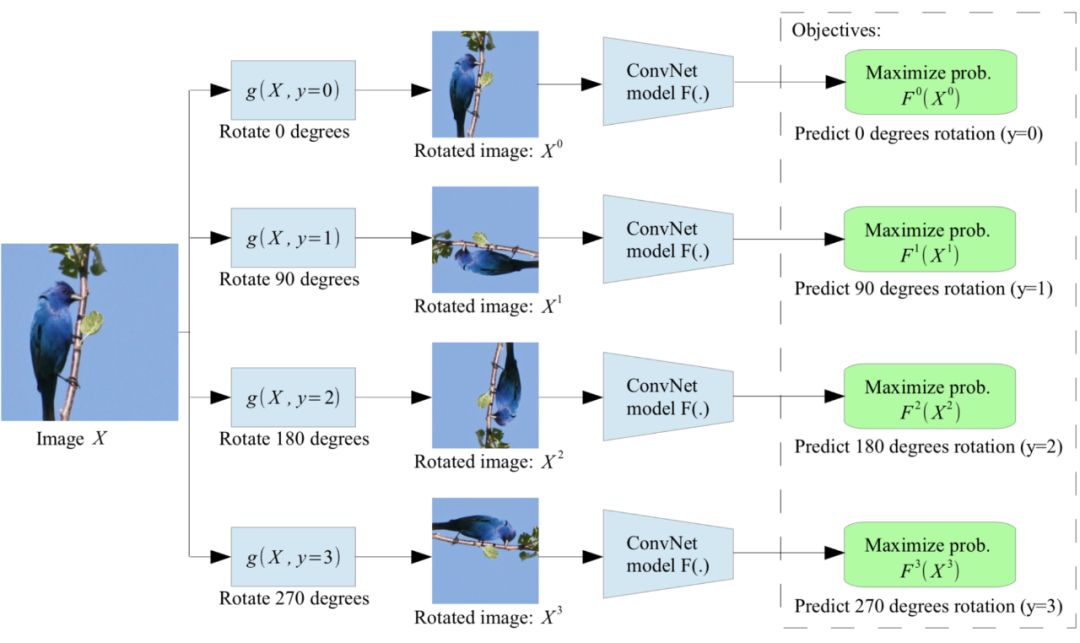
旋转整个图像是另一种有趣且低成本的方法,可在语义内容保持不变的情况下修改输入图像。每个输入图像首先随机旋转90度的倍数,分别对应于[0∘,90∘,180∘,270∘]。模型经过训练可以预测应用了哪种旋转角度,从而得出4类分类问题。
为了识别旋转了不同角度的同一图像,模型必须学会识别高级对象部分,如头部,鼻子和眼睛,以及这些部分的相对位置,让使模型以这种方式学习对象的语义概念。
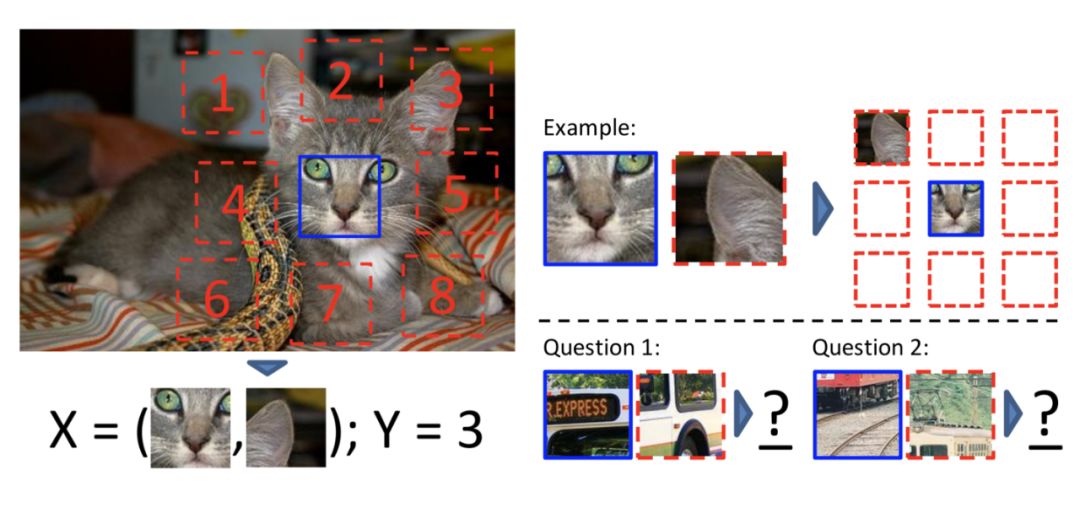
补丁
第二类自监督学习任务从一张图像中提取多个补丁,并要求模型预测这些补丁之间的关系。
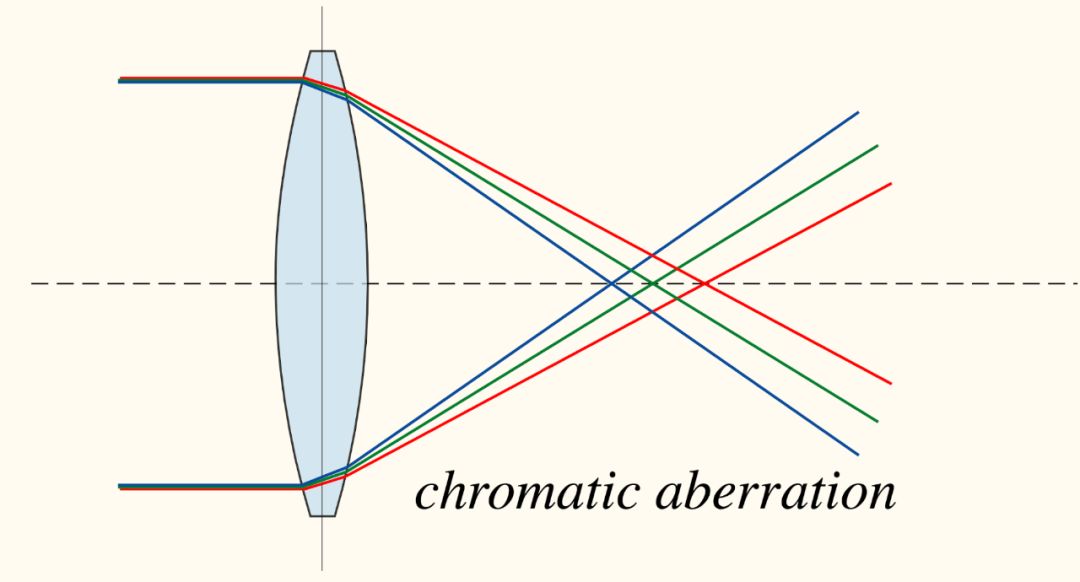
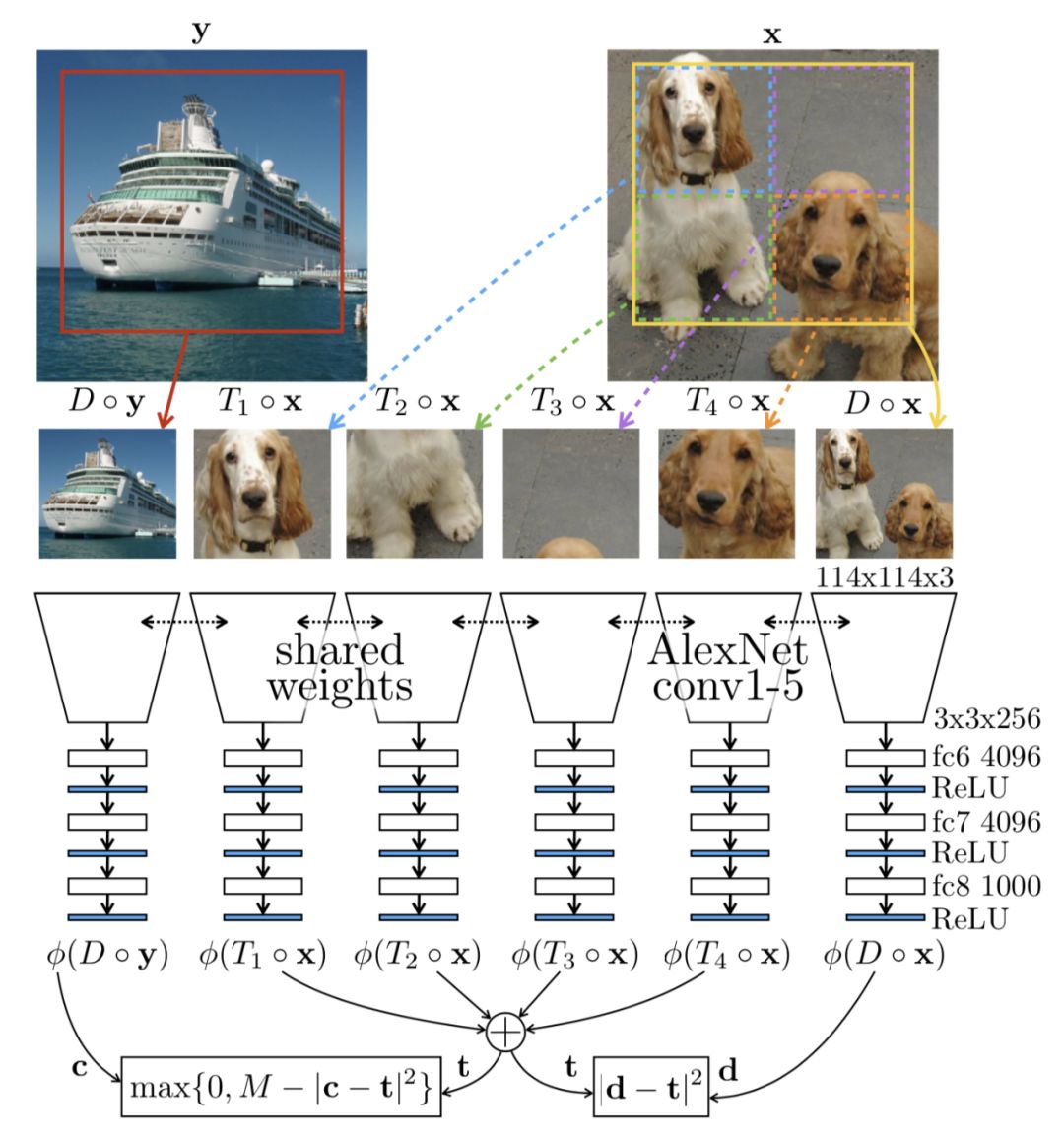
除了诸如边界图案或纹理之类的琐碎信号不断出现之外,还发现了另一个有趣且琐碎的解决方案,称为“色差”。它是由穿过透镜的不同波长的光的不同焦距触发的。在此过程中,颜色通道之间可能存在微小偏移。
因此,该模型可以通过简单比较绿色和品红色在两个不同色块中的区分方式,来学习分辨相对位置。这是一个简单的解决方案,与图像内容无关。
另一个想法是将“功能”或“视觉图元”视为一个标量值属性,可以对多个补丁进行汇总,并在不同补丁之间进行比较。然后通过计算特征和简单的算术来定义补丁之间的关系。
着色
着色可以用来完成强大的自监督任务:训练模型以对灰度输入图像进行着色;确切的任务是,将该图像映射到量化的色彩值输出上的分布。
为了在常见颜色和可能与图像中的关键对象相关联的稀有颜色之间取得平衡,可以通过权重项对损失函数进行重新平衡。
生成建模
生成建模的pretext任务是在学习有意义的潜在表示的同时重建原始输入。
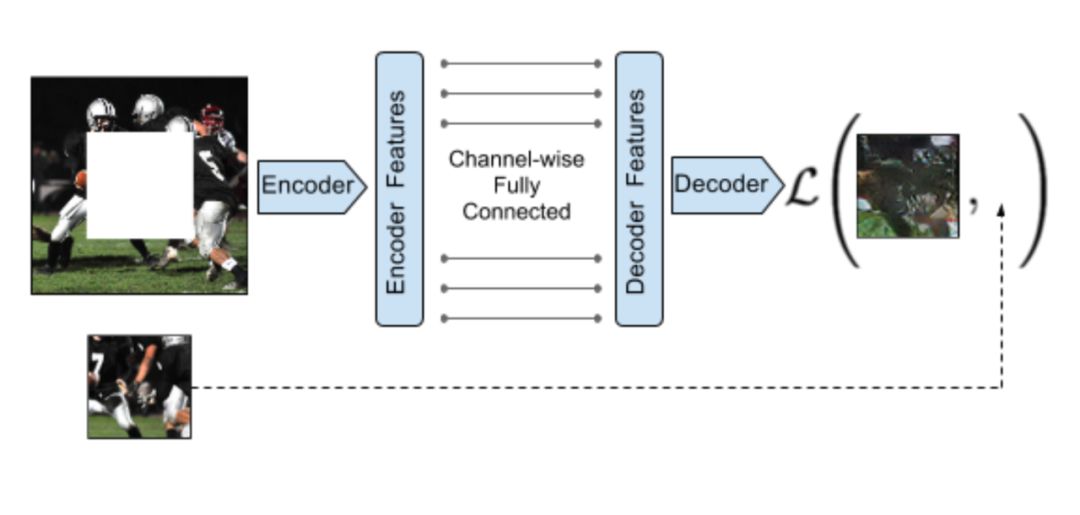
去噪自动编码器的任务是学习从部分损坏或带随机噪声的图像中恢复原图像。该设计的灵感源于这样一个事实:即使有噪声,人类也可以轻松识别图片中的对象,这表明,算法可以提取关键的视觉特征,并将其与噪声分离。
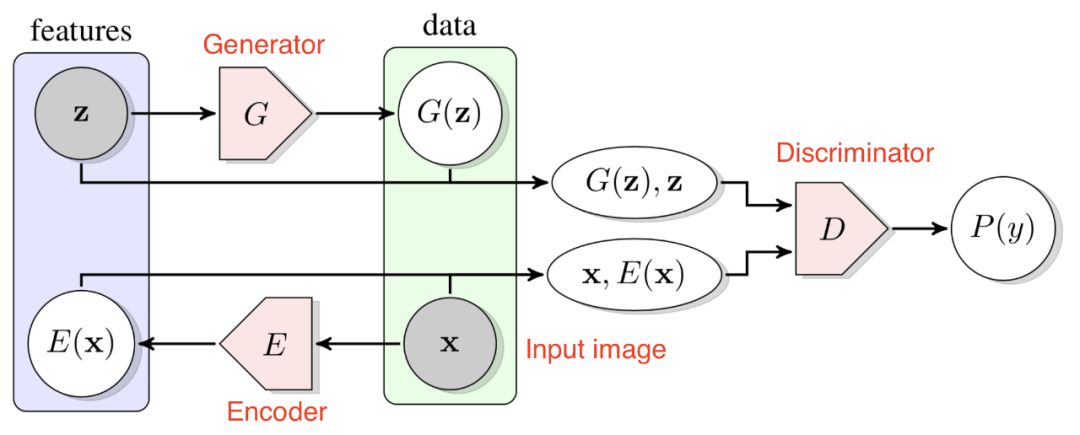
生成对抗网络(GAN)能够学习从简单的潜在变量映射到任意复杂的数据分布。研究表明,此类生成模型的潜在空间可以捕获数据中的语义变化;比如在人脸上训练GAN模型时,一些潜在变量与面部表情,是否戴眼镜,性别不同等因素相关。
视频包含一系列语义关联帧,而相邻帧在时间上更接近、这些相邻帧比距离更远的的帧更具相关性。算法框架的顺序描述了推理和物理逻辑的某些规则:例如物体的运动应该是平稳的,重力是向下的。
常见的流程是,在一个或多个带有未标记视频的pretext任务上训练模型,然后提供该模型的一个中间特征层,在基于动作分类、分段或对象跟踪的下游任务对模型进行微调。
追踪
物体的运动情况可以通过一系列视频帧进行跟踪。在临近帧中捕获同一物体的特征方式之间的差异并不大,这些差异通常是由物体或摄像机的微小运动触发的。Wang&Gupta在2015年提出了一种通过跟踪视频中的移动对象来实现无监督学习视觉表示的方法。
也可以在一个较小的时间窗口(如30帧)内精确跟踪目标运动。选择第一个补丁x和最后一个补丁x+并将其用作训练数据点。
如果直接训练模型,在对两个特征向量之间的差异实现最小化,那么该模型可能只会学会将所有内容映射到相同的值。
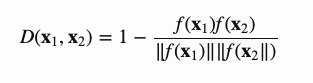
其损失函数为:
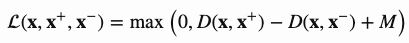
帧的顺序
视频帧会自然地按时间顺序排列。研究人员提出了一些自监督的任务,期望能够足够精确地表示应学习的正确帧序列。
一种方法是对帧的顺序进行验证。pretext任务是确定视频中的帧序列是否以正确的时间顺序排列。模型需要跟踪并推断物体在整个框架中的微小运动,才能完成此任务。
显示视频帧顺序验证的pretext任务,可在用作预训练步骤时,提高执行动作识别等下游任务的性能。
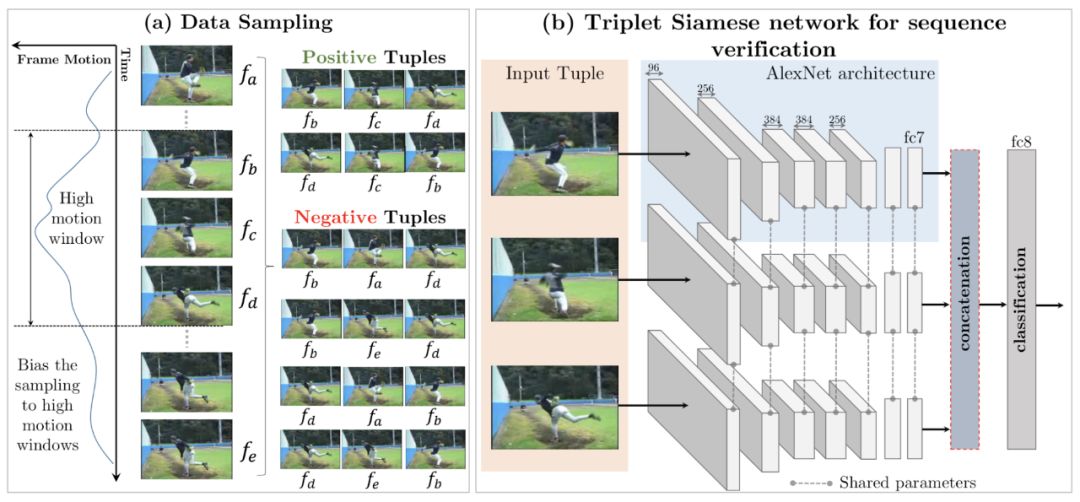
有趣的是,数据集中存在一些人工提示。如果处理不当,它们可能会导致图像分类过于琐碎,而不能有效反映视频内容,比如由于视频压缩,黑色帧可能不是完全黑色,而是可能包含按时间顺序排列的某些信息。因此,在实验中应消除黑框。
视频着色
Vondrick等提出将视频着色作为一种自监督学习课题,从而产生了丰富的表示形式,可用于视频分割和未标记的视觉区域跟踪,而无需进行额外的微调。
与基于图像的着色不同,此处的任务是通过利用视频帧之间颜色的自然时间一致性,将颜色从正常的参考帧复制到另一个灰度目标帧(因此,这两个帧不应相距太远)。为了一致地复制颜色,该模型旨在学习跟踪不同帧中的相关像素。
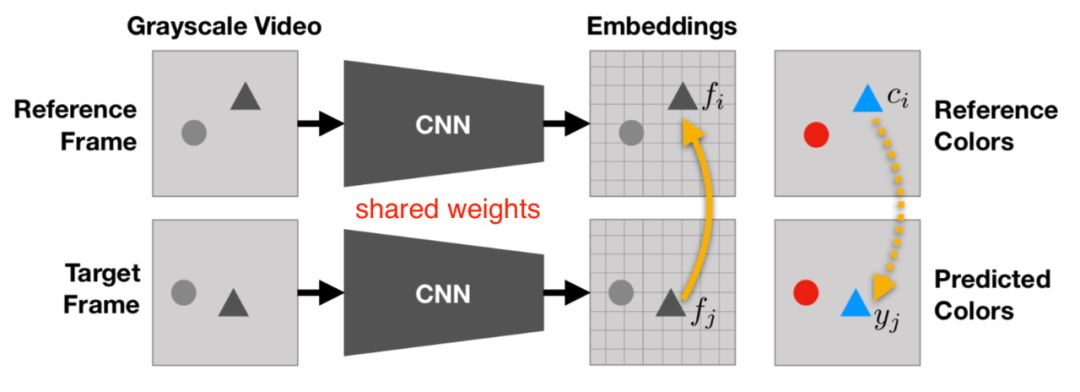
基于参考框的标记方式,该模型可用于完成一些基于颜色的下游任务,例如跟踪分割或及时的人体姿势。无需微调。
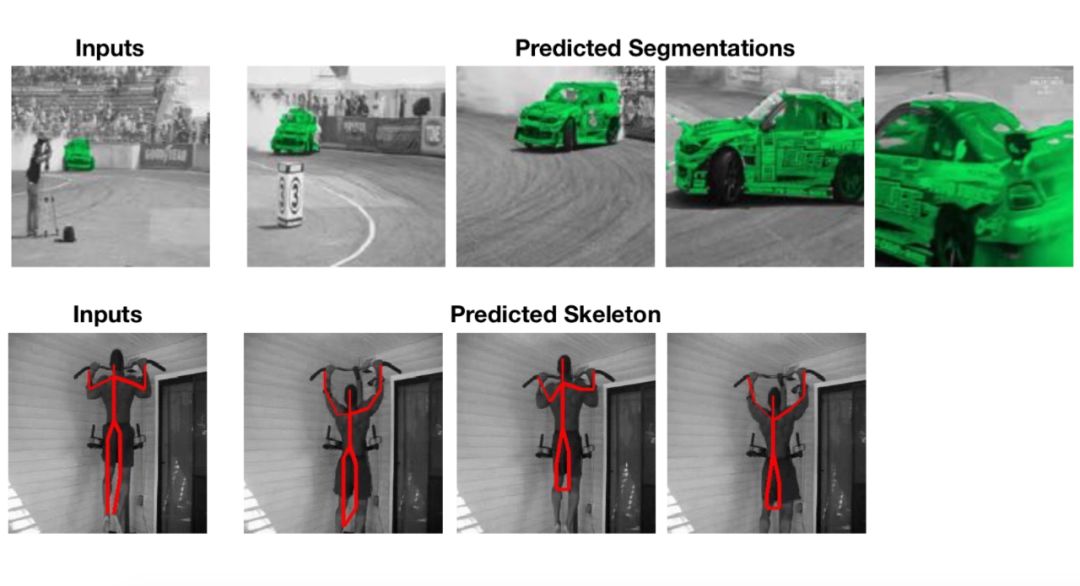
最后是几个常见的结果:
组合多个pretext任务可以提高性能。
使用更深层次的网络可以提高了表示质量;
到目前为止,监督学习的基准仍然优于所有其他基准。
由于篇幅所限,完整文章请移步:
https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html




