斯坦福AI实验室机器学习编程新范式:弱监督
选自ai.stanford.edu
作者:Alex Ratner 等
机器之心编译
参与:Nurhachu Null、Chita
深度学习模型有多好用是众所周知的,高质量的机器学习模型也并不难得。难得的是获取大量人工标注的训练数据,这些数据既昂贵又费时费力。因此,越来越多专业人士开始寻求弱监督范式,斯坦福 AI 实验室对此进行了一些综述,并描述了关于建模和整合各种监督来源的研究。
近年来,机器学习对现实世界的影响突飞猛进。这主要是因为深度学习模型的出现,它让从业者在没有任何手动设计特征的情况下就能够在基准测试数据集上得到当前最佳得分。由于有多个可用的开源机器学习框架(如 TensorFlow 和 pytorch 等)以及大量可用的先进模型,可以说高质量的机器学习模型现在几乎是商品化的资源。但是还有一个隐藏的问题:这些模型要依赖于大量人工标注的训练数据。
创建这些人工标记的训练数据集既昂贵又耗时——通常需要数月或者数年的时间来收集、清洗和调试,尤其是在需要领域专业知识的时候。除此之外,现实世界中的任务通常会变化和发展。例如,标注指南、粒度以及下游用例经常会变化,然后需要重新标注(例如,不能把评论仅分为积极和消极,还要加入中性类别)。鉴于这些原因,从业者越来越多地转向较弱的监督形式,例如,利用外部知识库、模式/规则或者其他分类器来启发式地生成训练数据。从本质上来讲,这些都是以编程方式生成训练数据的方法,或者更简洁地说就是编程训练数据。
本文先是对机器学习中由标注训练数据问题所驱动的领域进行综述,然后描述了本文关于建模和整合各种监督来源的研究。研究人员还讨论了用成百上千个以复杂和变化的方式进行交互的弱监督动态任务为大规模多任务机制构建数据管理系统的愿景。
综述——如何获得更多的标注训练数据?
机器学习中很多传统研究路线同样受到深度学习模型对标注训练数据依赖的驱动,这些学习模型都需要标注数据。本文绘制了一张图来表示这些方法和高级弱监督方法的核心区别:弱监督是使用来自主题专家(SME)的更高级和/或更嘈杂的输入。
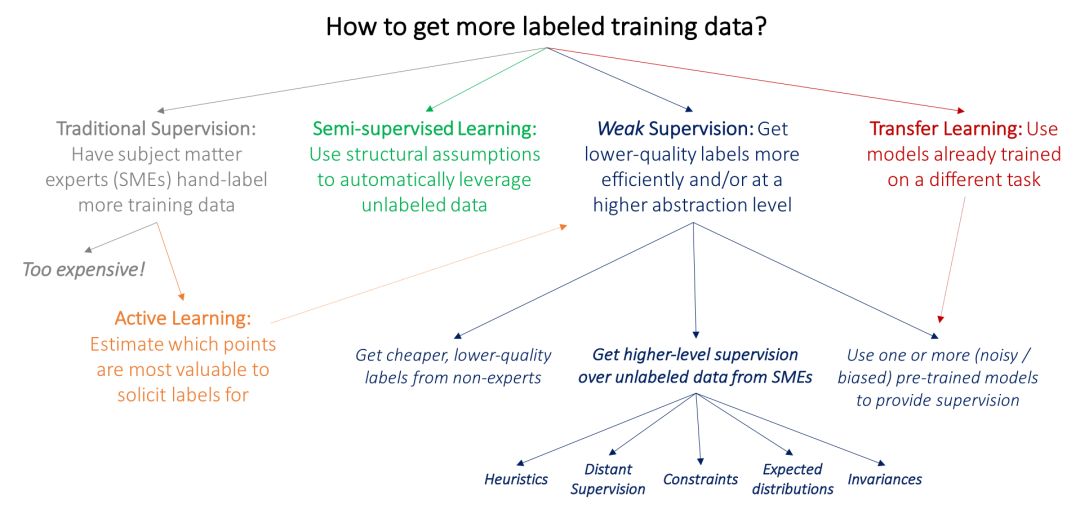
目前流行的方法是让主题专家直接标注大量数据,它的关键问题就是太昂贵了:例如,在医学成像领域获得大规模数据集很困难——不像研究生,放射科的医师可不会接受墨西哥卷饼和免费 T 恤作为报酬!因此,机器学习中很多经过充分研究的问题都遇到了标注数据的瓶颈,并受此驱动:
在主动学习中,其目标是更高效地利用 SME,让他们标注预计对模型来说最有价值的数据点。在标准的监督学习设置中,这意味着选择需要标注的新数据。例如,我们可能会选择接近当前模型决策边界的乳房 X 光片,然后让放射医师仅标注这些点。但是,我们也可以只要求与这些数据点相关的较弱监督,在这种情况下主动学习能够与弱监督进行完美的互补。
在半监督学习设置中,它的目标是使用小规模标注训练数据集和较大规模的未标注数据集。然后我们在较高层次上使用关于平滑度、低维结构或距离指标的假设来利用未标注数据(要么作为生成模型的一部分,作为判别模型的正则化器,要么学习紧凑的数据表征);从广义上讲,半监督学习的理念不是从主题专家中吸收更多输入,而是利用领域和任务不可知的假设来开发未标注数据,这些数据通常比较廉价,而且可以大量获得。最近的方法使用生成对抗网络、启发式转换模型和其它生成方法来有效地帮助正则化决策边界。
在典型的迁移学习设置中,其目标是利用一个或多个在不同数据集上训练好的模型,然后将它们应用到我们的数据集和任务中;例如,我们可能有一个用于检测身体另一个部位肿瘤的大规模数据集,以及在这个数据集上训练得到的分类器,我们现在希望把它们用在我们的乳房 X 光片检测任务中。现在深度学习社区中一个常用的迁移学习方法就是在大规模数据集上「预训练」一个模型,然后在目标任务上对其进行「精调」。另一个相关的研究领域是多任务学习,其中几个任务是联合学习的(Caruna 1993; Augenstein, Vlachos, and Maynard 2015)。
上述范例有可能能够让我们避免向主题专家寻求额外的训练标签。但是,标注一些数据的需求是不可避免的。倘若我们要求他们提供各种较高层次,或较低精度的监督形式(这些会更快、更容易实现)呢?例如,倘若放射科医师花一下午检查一组启发式或其它资源,那么,如果处理得当的话,是否可以有效地替代数千个训练标签?
向 AI 注入领域知识
从历史层面来看,尝试「编写」人工智能(即为其注入领域知识)并不是一件新鲜事——而现在提这个问题的新颖之处在于,人工智能从未如此强大,而就其可解释性和控制性而言仍然是一个「黑盒子」。
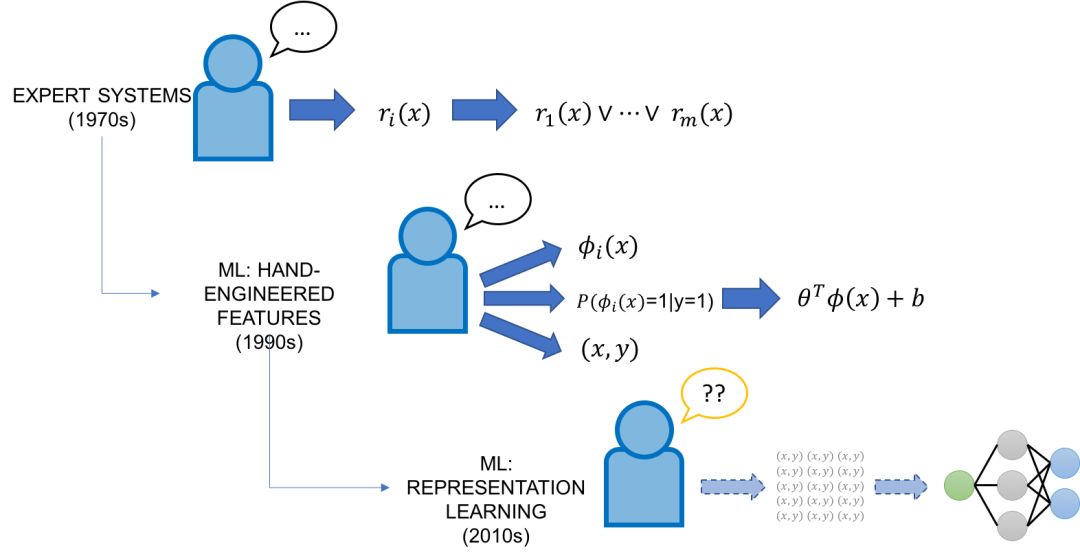
在上世纪七八十年代,人工智能的焦点是专家系统,它将领域专家手动整理的知识库和规则与推理引擎结合起来应用。20 世纪 90 年代,作为将知识整合到人工智能系统中的工具,机器学习开始飞速发展,它承诺以强大而灵活的方式根据标注训练数据自动完成这些事情。经典的机器学习方法(无表征学习)通常有个领域专家输入端口。第一,这些模型相比现代模型具有更低的复杂性,这意味着它们使用更少的人工标注数据。第二,这些模型依靠人工设计的特征,这提供了一种直接的方式编码、修改以及与模型的基本数据表征进行交互。但是,特征工程曾经且现在仍然被普遍认为是机器学习专家的任务,他们经常会在整个博士期间为特定任务制定特征。
深度学习模型:因其在不同领域和任务中自动学习表征的惊人能力,深度学习模型在很大程度上都避免了特征工程的任务。但是,它们大部分都是完全的黑盒子,除了要标注大量训练数据和调整网络架构之外,普通的开发者几乎无法没有控制权。在很多意义上,它们与旧专家系统脆弱但易于控制的规则完全相反——它们灵活且难以控制。这让我们从一个稍微不同的角度去思考最初的问题:如何利用我们的领域知识和任务专长来编写现代的深度学习模型?是否可以将基于规则的旧专家系统的直接性与现代机器学习方法的灵活性结合起来?
编码为监督:通过编程来训练机器学习
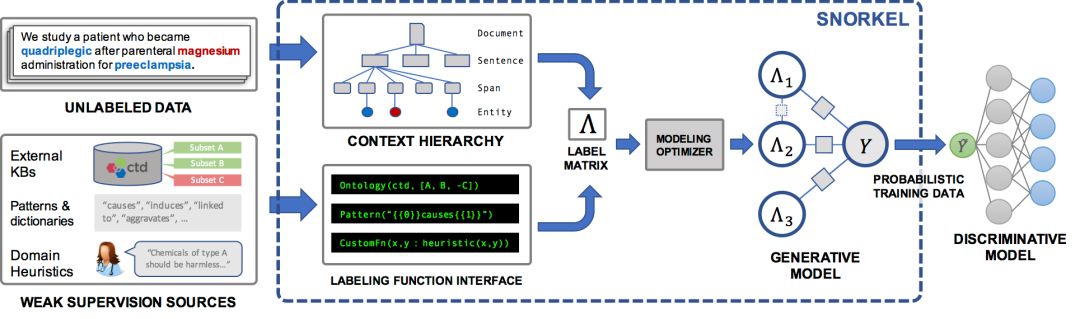
Snorkel 是我们开发的一个系统,用来支持和探索这种与机器学习交互的新类型。在 Snorkel 中,我们使用没有人工标注的数据,但会要求用户写一些标签函数(LFs),它们是用来标记未标注数据子集的黑盒代码片段。
然后我们就可以使用一组这样的标签函数来为机器学习模型标注训练数据。因为标签函数只是任意的代码片段,所以它们可以编码任意的信号:模式、启发式方法、外部数据资源、来自人群的噪声标签、弱分类器等等。并且,作为代码,我们可以获得所有其他相关的好处,例如模块化、可重用性、可调试性。例如,如果我们的建模目标改变了,我们可以调整标签函数来快速适应。
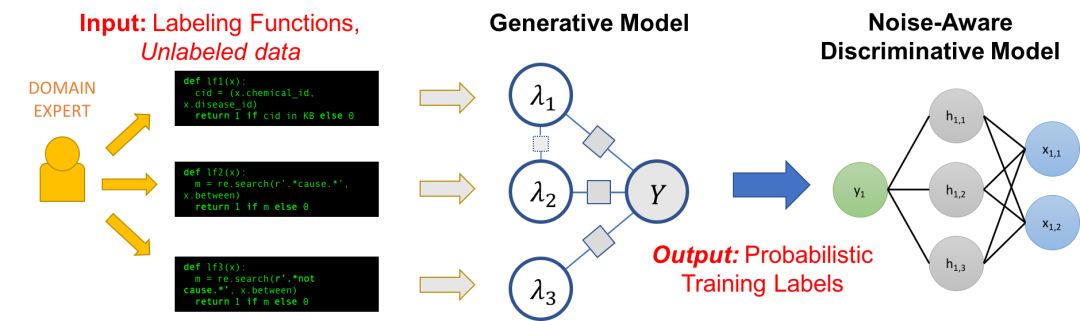
当然,一个问题是,标签函数会产生噪声输出,这些输出有可能会重叠或者冲突,导致不太理想的训练标签。在 Snorkel 中,我们使用数据规划方法来给这些标签去噪,这包含三个步骤:
将标签函数应用在未标注数据上。
在没有任何标注数据的情况下,利用生成模型来学习标签函数的准确率,并相应地加权它们的输出。我们甚至可以自动学习他们之间的相互关系。
生成模型输出一组概率训练标签,我们可以利用这组标签来训练强大又灵活的判别模型(例如深度神经网络),这个判别模型将会泛化到标签函数中表达的信号之外。
这整个过程可以被视为提供了一个简单、鲁棒和模型不可知的方法来「编写」机器学习模型。
标签函数
从生物医学文献中提取结构化信息是最能激励我们的应用之一:大量的有用信息被有效地锁在数百万篇科学文献的密集非结构化文本中。我们想利用机器学习来提取所有的内容,以便我们的生物合作者可以用它来做类似于诊断遗传疾病的事情。
如果是那种从科学文献中提取关于某种化学—疾病关系的任务,我们可能没有足够大(或任何)标注训练数据集。但是,在生物医学领域,有大量精选的本体、词典和其他资源,包括化学和疾病名称的各种本体、各种已知化学—疾病关系的数据库等,我们可以用它们来为我们的任务提供一种弱监督。此外,我们可以与生物合作者一起提出一系列任务特定的启发式方法、正则表达式模式、经验法则和负面标签生成策略。

作为表达工具的生成模型
在我们的方法中,我们认为标签函数隐式地描述了一个生成模型。快速复习一下:给定数据点 x,它具有未知的标签 y,这是我们想要预测的;在一个判别方法中,我们直接地对 P(y|x) 进行建模,但是在生成方法中,我们对 P(x,y) = P(x|y)P(y) 进行建模。在本文中,我们将训练集标注过程建模为 P(L,y),其中 L 是对象 x 的标签函数生成的标签,y 是对应的真实标签(未知的)。通过学习生成模型并直接估计 P(L|y),基于它们如何重叠和冲突(需要注意的是,我们不需要知道 y),我们实际上学习的是标签函数的相对准确率。
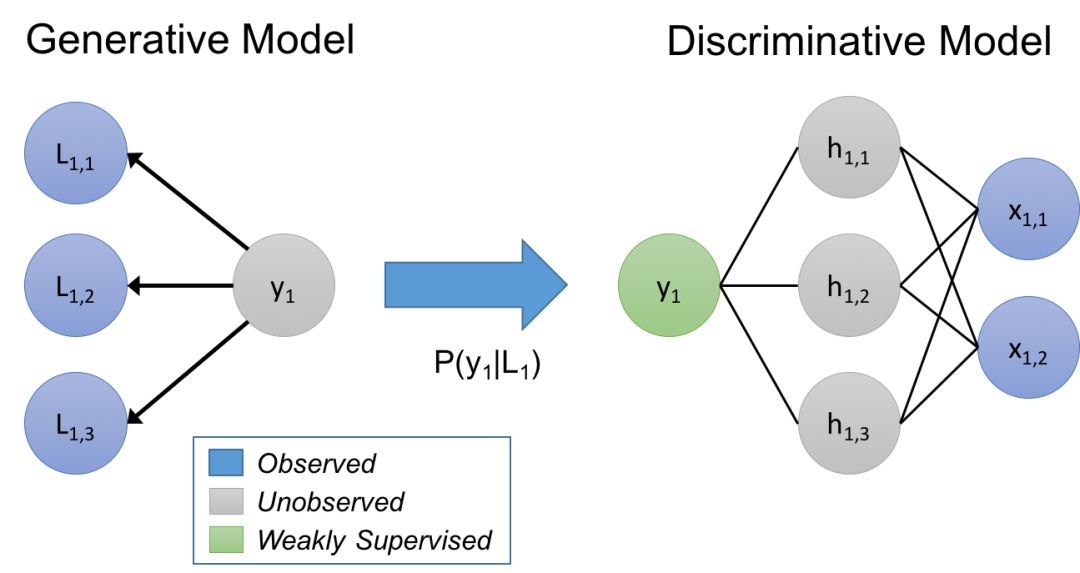
我们在标签函数上用这个估计的生成模型来训练最终判别模型的噪声感知版本。为此,生成模型在训练数据的未知标签上推断概率,然后我们最小化判别模型关于这些概率的期望损失。
估计这些生成模型的参数可能会相当棘手,尤其是当使用的标签函数(用户表达的或者是推断的)之间存在统计相关性的时候。在本文中,我们证明,给定足够的标签函数,就可以得到与监督式方法(除了在我们的情况中,关于未标注数据)相同的渐进缩放。我们还研究了如何在不使用标注数据的情况下学习标签函数之间的相关性,以及如何显著地提升性能。
Snorkel 在实际应用中的一些记录!
在最近关于 Snorkel 的论文中,我们发现在很多现实应用中,这种与当代机器学习模型交互的新方法效果很好!一些亮点包括:
在斯坦福 Mobilize 中心主办的关于 Snorkel 的 workshop(为期两天)中开展了一项用户研究,我们比较了教主题专家用 Snorkel 和花费等价时间来人工标注数据的生产力。我们发现他们构建模型不仅快了 2.8 倍,而且平均预测性能提高了 45.5%。
在两个现实的文本关系抽取任务(与来自斯坦福大学、美国退伍军人事务部和美国食品药物管理局的研究人员合作)中——以及 4 个其它的基准文本和图像任务上,我们发现 Snorkel 相对基准技术带来了平均 132% 的提升。
我们探索了如何对用户提供的标签函数进行建模的新型权衡空间,进而产生了一个基于规则的优化器来加速迭代开发周期。
下一步:大规模多任务弱监督
我们正在努力把在 Snorkel 中设想的弱监督交互模型扩展到其它模态,如格式丰富的数据和图像、用自然语言监督任务和自动生成标签函数!在技术方面,我们感兴趣是扩展 Snorkel 中心的核心数据编程模型,使其更容易用更高级的接口(如自然语言)指定标签函数,同时更易与其它弱监督方法相结合,例如数据增强。
多任务学习场景的日益流行还引发了一个问题:当嘈杂的、可能相关的标签源现在标注多个相关任务时会发生什么?我们能否通过联合建模对这些任务的监督来受益?我们在 Snorkel 的多任务感知新版本中解决了这些问题,也就是 Snorkel MeTaL,它支持为一个或多个相关任务提供噪声标签的多任务弱监督源。
我们考虑的一个例子是设置不同粒度的标签源。例如,假设我们的目标是训练一个细粒度的命名实体识别(NER)模型来标注特定类别人物和地点的提及。我们有一些细粒度的噪声标签,如「律师」vs「医生」,或者「银行」vs「医院」,有些是粗粒度的标签,如「人物」vs「地点」。通过将这些源表示标记不同的分层相关任务,我们可以对它们的准确率进行联合建模,重新加权并组合它们的多任务标签来创建更干净、更加智能聚合的多任务训练数据,这种数据能够提升最终 MTL(多任务学习)模型的性能。
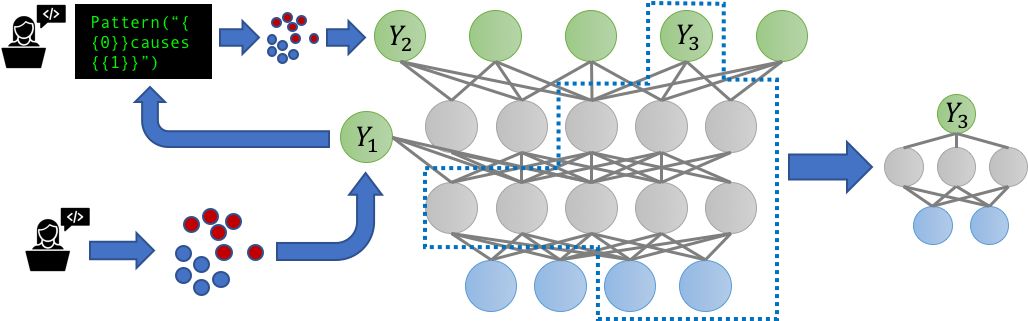
我们认为,在为多任务学习构建数据管理系统时最令人激动的方面将围绕着处理我们所说的大规模多任务机制展开*,*其中数十到数百个弱监督任务以复杂多变的方式交互。尽管迄今为止大多数多任务学习研究都考虑过最多处理几项任务,这些任务由静态手工标注的训练集定。但现在各组织——无论是大企业、学术实验室还是在线社区都要维护数十到数百个变化迅速且相互依赖的弱监督建模任务。此外,因为这些任务是弱监督的,所以开发者能够在数小时或者数天内(而不是数月或者数年)添加、删除或者改变任务(即训练集),不过这可能需要重新训练整个模型。
在最近的论文《The Role of Massively Multi-Task and Weak Supervision in Software 2.0》中,我们概括了一些针对上述问题的初始想法,设想了大规模的多任务设置,其中多任务学习模型能够有效地充当训练数据的中央存储库,这些数据被不同的开发者弱标注,然后在一个中央「母体」多任务模型中结合。无论确切外形如何,在这个设想中多任务学习技术有很多令人兴奋的进步——不仅是新的模型架构,而且还与迁移学习方法、新的弱监督方法以及新的软件开发和系统范式日益统一。

原文链接:https://ai.stanford.edu/blog/weak-supervision/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



