【速览】ICCV 2021 | 翻转卷帘快门相机:从卷帘快门图像恢复高帧率全局快门视频
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
翻转卷帘快门相机:从卷帘快门图像恢复高帧率全局快门视频
*通讯作者:戴玉超(daiyuchao@nwpu.edu.cn)
◆ ◆ ◆ ◆
近几年,使用CMOS传感器的相机装置以其价格更便宜、功耗更低、帧速率更高等特点得到了广泛应用。尤其是,目前几乎市面上所有的消费级摄像机都使用CMOS传感器。CMOS相机大都采用卷帘式快门工作机制,通过逐行曝光的方式实现数据采集,不同行的像素点具有不同的曝光时间,同时也对应着不同的相机位姿。当相机在移动中对所处场景进行拍摄或者拍摄运动的物体时,得到的图像会出现图形倾斜、晃动、扭曲等卷帘快门效应。这不仅造成了摄影中成像质量的严重退化,而且使得大多数针对全局快门相机模型设计的三维视觉模型变得失效。
单张分辨率为H×W的卷帘快门图像可以被视为由h张连续的全局快门图像依次按行进行像素拼合形成的,其逆过程可以被看作从卷帘快门图像中提取出这些虚拟的全局快门图像序列,即实现卷帘快门图像时间超分辨(Rolling shutter temporal super-resolution, RSSR),比如从两张h=720像素高度的卷帘快门图像中恢复出1440张全局快门图像。同时卷帘快门图像校正和时间超分辨是极具挑战的一项任务,当前在深度学习框架下还远未能得以解决。
(1) 揭示了卷帘快门图像校正问题的内在几何性质,做出了三个理论贡献:a)在匀速运动模型下,建立了去除卷帘快门畸变的双向卷帘快门去畸变流;b)通过简单的缩放操作建立了连续帧之间的光流和对应于任意扫描线的去畸变流之间的几何联系;c)建立了对应于不同扫描线的不同去畸变流之间的相互转换方法。
(2) 通过将本文所建立的几何模型有机地融合到深度学习网络中,我们设计了第一个卷帘快门图像时间超分辨网络架构,可以从连续两帧卷帘快门图像中提取出对应于这两帧中任意时刻的全局快门图像。
(3) 所提方法不仅在卷帘快门校正和推理速度上都优于目前最先进的方法,而且可以恢复出高帧率、高质量的全局快门视频序列,这是目前基于深度学习的方法远不能及的。
由于从单张卷帘快门图像进行畸变校正是一个严重的病态问题,本文主要关注于从两张连续的卷帘快门图像中恢复潜在的全局快门图像序列。为了这个目的,在基于几何模型的方法中,DiffSfM[1]使用微分建模提出了一种相机全运动估计方法,从而实现对第一帧中任意扫描线全局快门图像的恢复。但是,由于过于依赖初始光流估计和复杂的非线性优化,该方法的鲁棒性较差,计算效率较低。随后,DiffHomo[2]提出了一种基于平面假设的微分卷帘快门单应模型,可用于进行卷帘快门图像的拼接和校正。综上,它们都仅仅对前向卷帘快门几何进行建模,导致无法用于恢复对应第二帧扫描线的全局快门图像,而且该几何模型也无法直接有效地拓展至深度学习模型。在基于深度学习的方法中,当前最先进的DeepUnrollNet[3]使用连续两帧卷帘快门图像作为输入,设计了一个深度快门展开网络来仅仅预测一张与第二帧图像的中间行相对应的全局快门图像。最近提出的RSCD[4]可用于同时卷帘快门校正和去模糊,能够从输入的连续三帧模糊的卷帘快门图像中估计出一张清晰的全局快门图像。值得一提的是,它们都不具备恢复多张连续全局快门图像的能力。据我们所知,我们所提的方法是第一个用于学习从两张连续卷帘快门图像到全局快门视频的映射的深度学习模型。
(1)卷帘快门几何建模
假设相机在成像过程中经历匀速运动
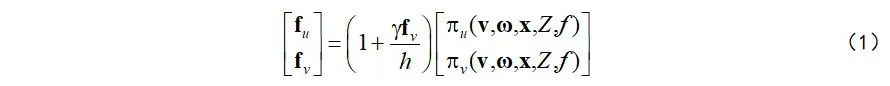
这儿
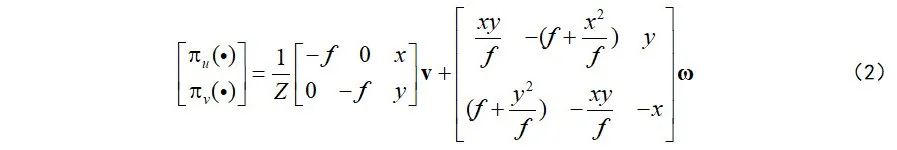
表示潜在的卷帘快门时空几何模型。消去式(1)中的垂直光流分量

然后,为了得到将卷帘快门图像的第
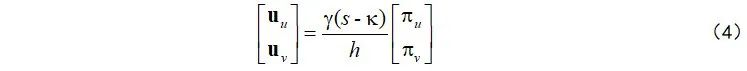
接下来,基于式(3)和(4),通过简单的缩放操作即可建立双向去畸变流和双向光流之间的几何关联方法:
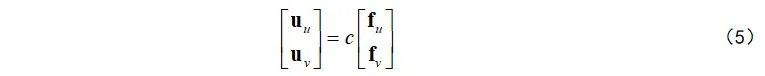
这儿
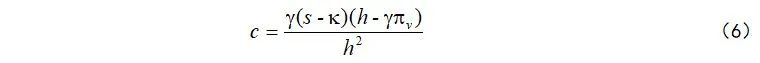
注意:本文证明了将卷帘快门图像校正至第
最后,基于式(4),我们提出了对应于扫描线
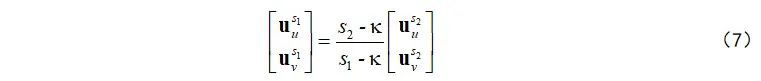
式(7)仅包含简单的矩阵运算,可以确保较高的计算效率。而且,从式(7)可以看出去畸变流具有强烈的行依赖特性,如下图所示:不同于光流的各向同性分布,去畸变流的大小和方向均与待校正的目标扫描线紧密相关。
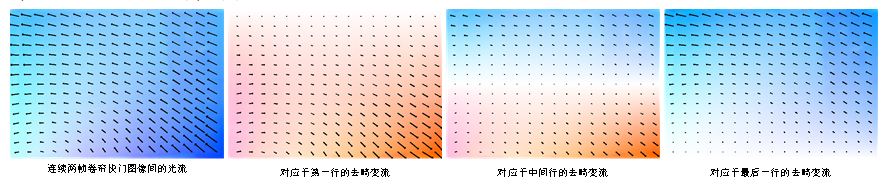
图 1 去畸变流与光流的可视化比较
综上,利用式(5)和(7)中建立的统一有效的几何模型和几何框架,可以为发展基于深度学习的卷帘快门图像时间超分辨方法提供理论支持。
(2)卷帘快门时间超分辨(RSSR)深度学习模型
如下图所示,所提出的级联式RSSR深度网络架构的大致流程为:基于PWC-Net的双向光流估计 → 基于UNet预测光流与对应于中间扫描线的去畸变流之间的关联图 → 显式计算与中间扫描线相对应的去畸变流 → 显式进行传播得到对应于任意扫描线的去畸变流 → 使用前向翘曲估计对应于任意扫描线的卷帘快门图像序列。所提的RSSR模型封装了潜在的卷帘快门时空几何模型,具有较好的可解释性。我们在训练阶段仅使用对应于中间扫描线的全局快门图像作监督,在测试阶段可以较为高效地泛化至估计对应于任意扫描线的全局快门图像,即实现卷帘快门图像时间超分辨。
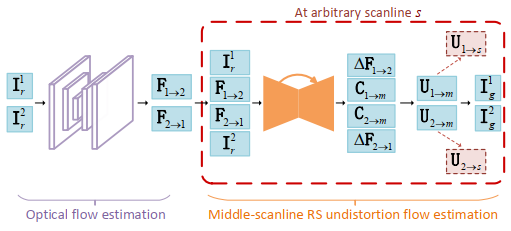
图 2 RSSR的网络架构
(1)定性结果

图 3 与SOTA方法的定性比较结果
我们的方法恢复的全局快门图像具有更好的几何一致性。
(2)定量结果
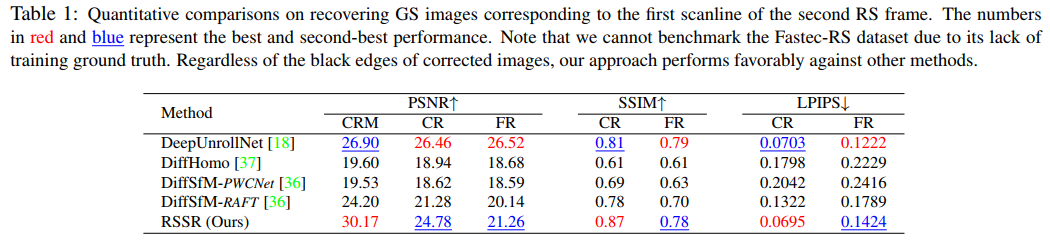
表 1 与SOTA方法的定量比较结果
(3)产生高帧率全局快门视频

图 4 恢复连续8张全局快门图像序列的可视化结果






图 5 恢复高帧率全局快门视频的动态结果
(4)与SOTA视频插帧方法和两阶段方法的对比
两阶段方法:先使用DeepUnrollNet[3]执行卷帘快门校正得到全局快门图像,再使用视频插帧方法:DAIN[5]得到全局快门视频。

图 6 与SOTA视频插帧和两阶段方法的比较结果
(5)计算效率
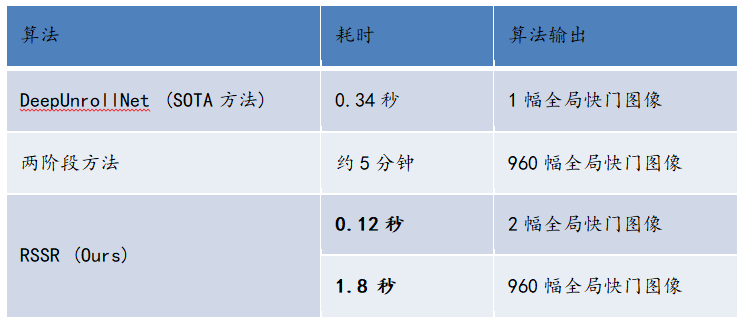
使用分辨率为640×480的图像在NVIDIA GeForce RTX 2080Ti GPU上进行测试
[1] Zhuang B, Cheong L F, Hee Lee G. Rolling-shutter-aware differential sfm and image rectification. Proceedings of the International Conference on Computer Vision. 2017: 948-956.
[2] Zhuang B, Tran Q H. Image stitching and rectification for hand-held cameras. Proceedings of theEuropean Conference on Computer Vision. 2020: 243-260.
[3] Liu P, Cui Z, Larsson V, et al. Deep shutter unrolling network. Proceedings of the Conference on Computer Vision and Pattern Recognition. 2020: 5941-5949.
[4] Zhong Z, Zheng Y, Sato I. Towards Rolling Shutter Correction and Deblurring in Dynamic Scenes. Proceedings of the Conference on Computer Vision and Pattern Recognition. 2021: 9219-9228.
[5] Bao W, Lai W S, Ma C, et al. Depth-aware video frame interpolation. Proceedings of the Conference on Computer Vision and Pattern Recognition. 2019: 3703-3712.




