【速览】ICCV 2021 | FedU: 如何从分布式数据中进行无监督表示学习?
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
FedU: 如何从分布式数据中进行无监督表示学习?
*通讯作者:庄伟铭
◆ ◆ ◆ ◆
在 ICCV 2021 上,商汤科技-南洋理工大学联合 AI 研究中心 S-Lab 的研究者提出了分布式无监督表示学习新范式 FedU --- 从分布式无标签的图片数据中,在隐私保护的前提下,进行表示学习。FedU 采用分布式联邦学习的方式,从多个数据源进行无监督表示学习,从而能被进一步用在下游任务上。
最近几年来,无监督/自监督视觉表示学习的研究已经取得了一定的成果,在 ImageNet 数据集上,一些自监督学习的方法已经可以媲美监督学习,而多数的这些方法基于一个假设 -- 数据采集和存储在一个中心的服务器上。随着近几年边端设备数量的暴增,这些设备产生了海量的数据,比如手机拍照和路边摄像头产生了大量图片,如果将这些图片都上传收集到一个中心服务器,会产生一定的隐私泄露的隐患,比如会泄露个人的敏感信息和位置信息。此外,这些图片产生之后天然不带有标签,对这些图片进行人工标注费时费力。因此,如何能在不上传图片的情况下,联合多个边端设备进行无监督表示学习至关重要,通过这些数据学到的模型,将会更加适用于这些边端的场景。此外,因为手机和摄像头的角度、环境等不同,带来了数据异构性的问题。
为了解决上述问题,我们提出了联邦无监督视觉表示学习框架 FedU。FedU 用一个云端服务器联合多个边端设备进行训练,在训练初始时,云端服务器初始化一个编码器 (Encoder) 和一个预测器 (Predictor),并发送给多个边端,初始化边端模型。再次之后,整个训练流程包括四个步骤(参考下图):
1. 本地训练:每个边端采用孪生神经网络使用本地数据进行无监督对比学习。
2. 模型上传:每个边端将训练好的模型上传到云端。
3. 模型融合:云端聚合模型,产生新的模型。
4. 模型更新:云端使用新的模型更新边端的模型。
这四个步骤组成了一回合的训练,FedU 不断迭代这四个步骤,直到完成训练。在这个过程中,我们采用了当时最新的 BYOL[1] 对比学习方法进行本地训练,并设计了云边通信协议和发散感知的网络更新策略。
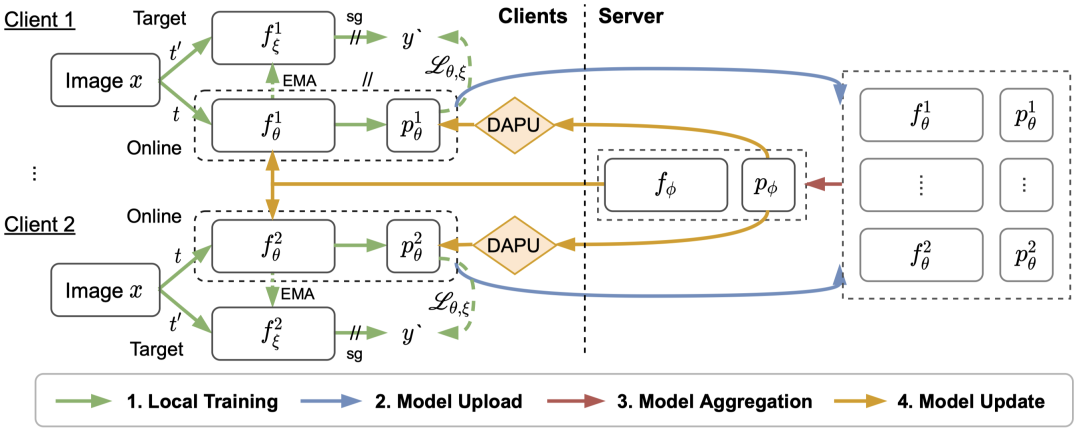
图 1 FedU 训练流程图
1. 本地训练
每个边端每回合都会用本地的数据进行训练。传统的联邦学习假设每个边端的数据是有标签的,所以使用一个网络模型进行训练。FedU 框架中,每个边端采用 BYOL[1] 进行无监督对比学习,每个边端端有孪生神经网络,孪生神经网络由两个网络组成:在线网络
本地无监督对比学习的方法如下:
1. 对于一张图片,取两种不同的随机图像变换(剪裁、水平翻转、颜色变换等)
2. 将两个不同的变换分别通过在线网络和目标网络。在线网络中通过一个编码器和预测器,输出一个预测向量;目标网络通过一个编码器输出一个维度相同的向量,对比学习目标是让在线网络与目标网络的输出尽可能相近,所以对两个向量计算损失函数:
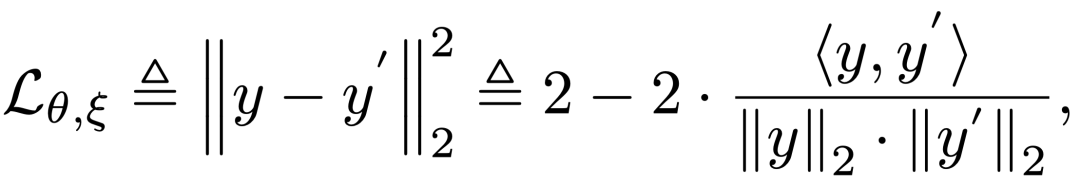
3. 更新在线网络的编码器和预测器。
4. 在线网络更新完成后,在线网络的编码器通过指数移动平均更新目标网络的编码器:
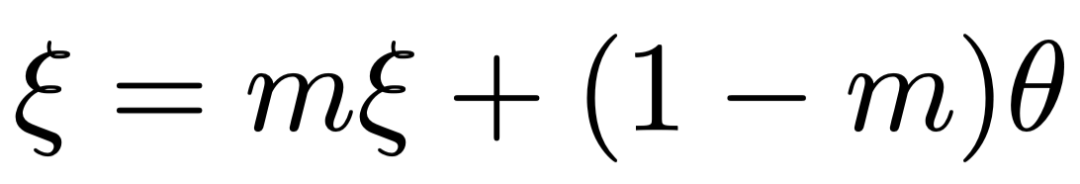
2. 通信协议设计
FedU 的训练过程中,云端和边端之间需要频繁通信,而每个边端本地有两个网络模型,因此两个关键的问题是:
1. 在模型上传时,是上传在线网络、目标网络、还是二者都上传?
2. 在模型更新时,是更新在线网络、目标网络、还是二者都更新?
FedU 中提出应该上传并更新在线网络。首先从模型上传对于本地数据的视觉表示学习的有效性来看,在线网络的参数由于在每个训练的轮次都使用梯度下降进行更新,因此可以更好地捕获本地数据集的特征。其次,从模型更新的角度来看,在云端执行的模型融合是为了更好的泛化能力,而本地的目标网络只是提供本地数据集相关的监督信号,如果使用全局模型来更新本地的目标网络,则无法提供有效的本地数据集相关的监督信号供在线网络学习,降低了训练的效率。此外,如果同时更新本地的在线和目标网络则会导致本地模型需要去适应在异构数据上训练得到的全局模型,也会影响训练的结果。因此 FedU 中涉及的通信协议只上传并更新在线网络。
3. 发散感知的网络更新策略
模型更新时,除了需要考虑更新哪个网络的编码器之外,还需要考虑如何更新边端的预测器。预测器是神经网络的最后一层,所以包含了更多本地异构性数据的特征,如何更新预测器会起到至关重要的作用。为了解决非独立同分布的异构数据,FedU 提出了发散感知的预测器更新策略。
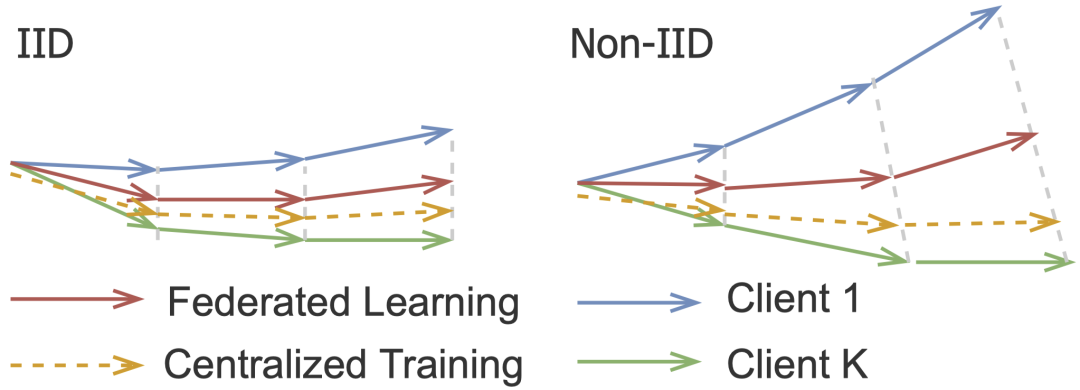
图 2 展示了用独立同分布和非独立同分布数据在联邦学习训练中产生的模型发散的现象
为了解决这个问题,FedU 提出了发散感知的预测器更新,公式如下:
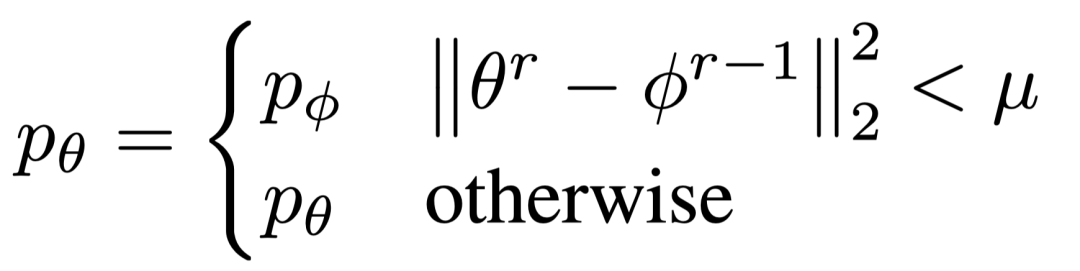
这个设计是基于卷积神经网络的特性,预测器是在线网络的最后一层,包含了与数据集分类最为相关的信息,由于每个边端数据有异构性,预测器之间差别较大。所以,当云端模型和边端模型相似度高于阈值时,说明两个模型之间的离散较大,为了更加适应边端的情况,保留边端的预测器;当云端模型和边端模型的相似度低于某个阈值时,说明模型之间的离散较小,用云端的预测器能更好的学到多个边端的知识。
表 1 Linear Evaluation 的结果对比
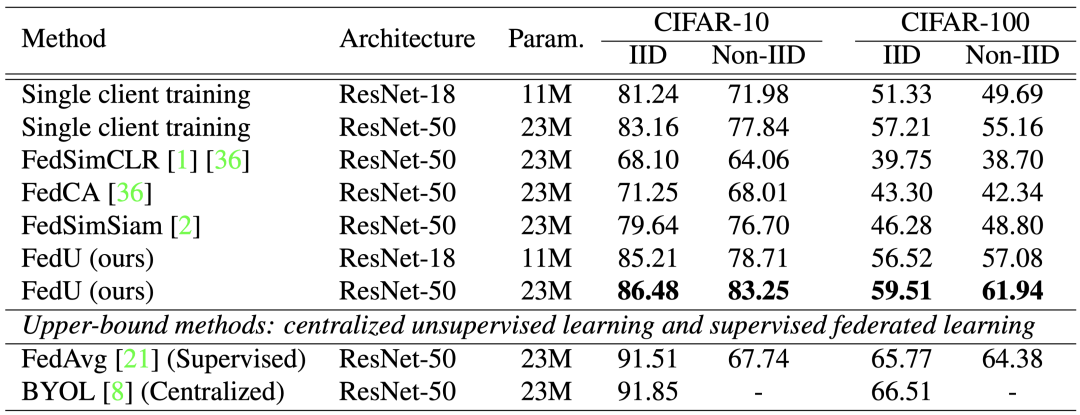
上表是 Linear Evaluation 的结果对比,实验模拟了5个边端的场景,使用无监督对比训练了 100 回合得到模型骨干,然后取在线网络的模型骨干,使用监督的方法训练一个分类器。FedU 的性能比其他的方法以及单个边端训练的结果有显著的提升。
表 2 在模型上传和更新时,使用在线网络和目标网络的结果对比
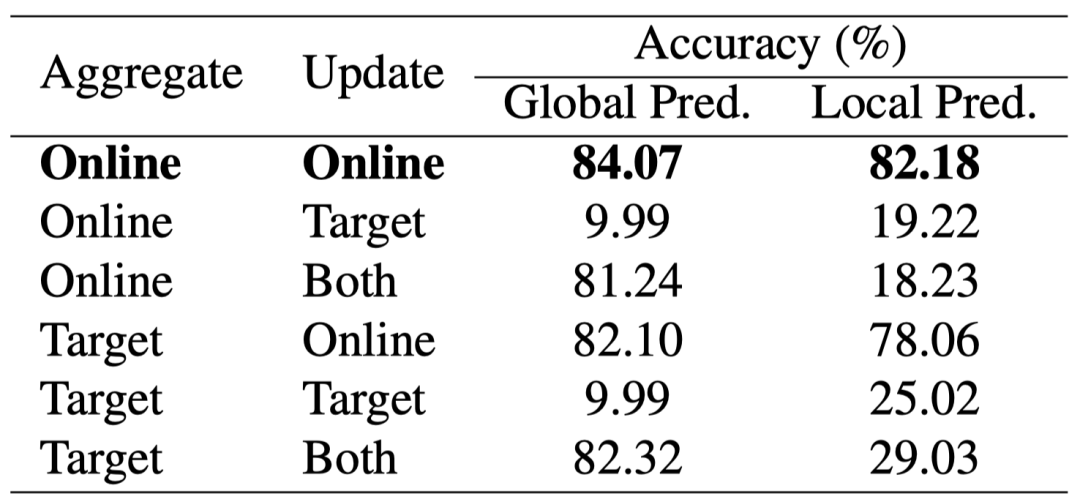
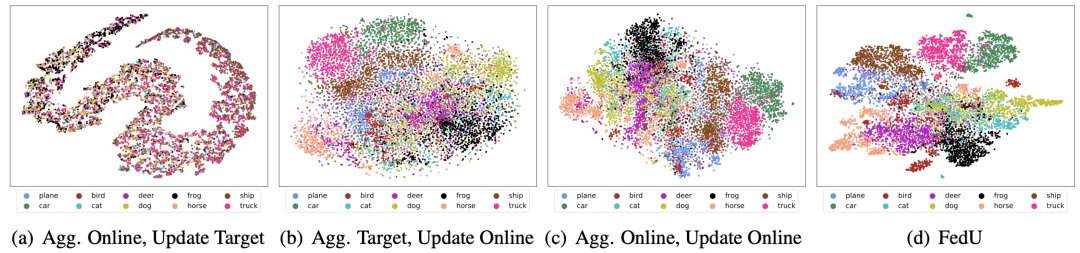
图 3 使用不同模型上传和更新学到的表示可视化对比
另外,FedU 还分析对比了模型上传和模型更新时,用在线编码器或者目标编码器的效果。使用在线编码器进行模型上传和更新的效果显著。
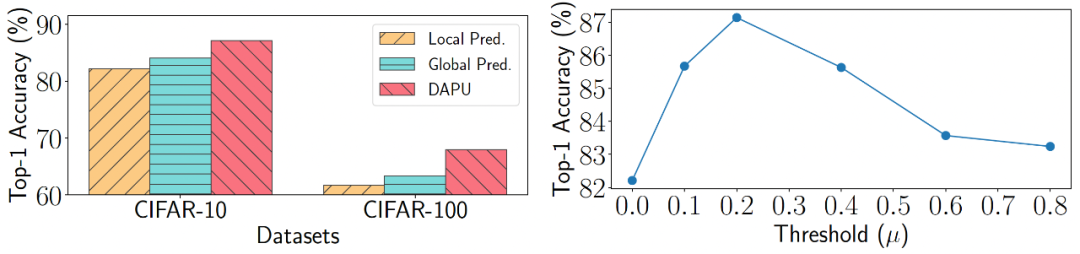
图 4 使用发散感知的预测器、本地预测器、全局预测器更新的结果对比,以及 发散感知的预测器中阈值 μ 的取值分析
除此之外,FedU 还对比了使用不同的预测器的结果,使用发散感知的预测器更新策略(DAPU)在两个数据集上能得到最好的结果。另外,阈值
在这项工作中,我们提出了联邦无监督视觉表示学习框架 FedU,为解决数据异构性的问题,我们对其中的通信协议及网络更新机制进行深入的分析和研究,并取得了显著的性能提升。我们希望这个工作能够鼓励并促进在隐私保护的情况下,从分布式数据中进行表示学习方面的研究。此外,可以考虑在更大的数据集比如 ImageNet 上做进一步的验证和研究。
[1] Grill, Jean-Bastien, et al. "Bootstrap your own latent-a new approach to self-supervised learning." NIPS, 2020.




