ACL 2019开源论文 | 基于Attention的知识图谱关系预测

作者丨王文博
学校丨哈尔滨工程大学硕士生
研究方向丨知识图谱、表示学习


动机
由于传统方法都将三元组进行独立的处理,忽略了其相邻的三元组之间隐藏的固有信息的缺点,使得无论是转化模型还是较新的基于卷积神经网络(CNN)的模型都不能获取在给定三元组附近的丰富的潜在结构信息。因此本文为解决上述问题尝试用图神经网络(GNN),从以下两方面进行创新:
通过不断迭代注意力机制网络,来为与给定节点具有不同距离的邻居结点赋予不同注意力值,使得最终该节点的嵌入向量包含多跳邻居节点信息在其中。通过以上方法构建出了针对知识图谱关系预测的嵌入模型。
为了解决距离越远连接的实体数量呈指数增长的问题为 n 跳实体引入辅助边作为辅助关系。
模型
背景知识补充
知识图谱可以表示为 ζ=(ϵ,R),其中 ϵ 和 R 分别表示集合中的实体(结点)和关系(边)。对于三元组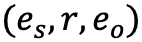
之间存在边 r。嵌入模型试图学习实体、关系以及得分函数的有效表示,以达到当给定一个三元组
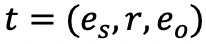
图注意力神经网络(GATs)
图注意力神经网络 (GANs)不同于图卷积神经网络(GCNs)将所有邻居实体的信息赋予相同权重的策略,采用了按照邻居实体结点对给定实体结点的不同重要程度分配不同权重的策略。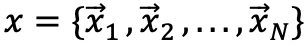
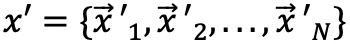
和
分别表示实体
的输入嵌入向量与输出嵌入向量,N 表示实体(结点)的个数。单独的 GAT 层可以描述为下述公式:
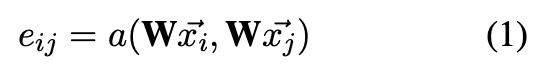
其中表示知识图谱中边
的注意力值,W 是一个可以将输入特征映射到更高维的输出特征空间中的参数化的线性转化矩阵,a 是所选择的注意力函数。
每个边的注意力值表示边的特征对源结点
的重要程度。此处相对注意力值
通过对邻居集合中得出的所有注意力值进行 softmax 运算得出。公式(2)展示了一个输出层。
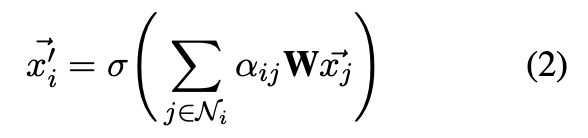
GAT 运用多头注意力来稳定学习过程。连接 K 个注意头的多头注意过程如公式(3)所示:
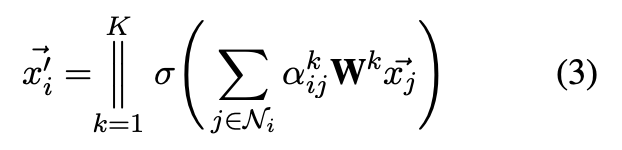
其中 || 表示连结方式,σ 表示任意的非线性函数,表示由第 k 个注意力机制计算的边
的归一化系数,
表示第 k 个注意力机制对应的线性转化矩阵。为达到多头注意的目的,在最终层的输出嵌入向量是通过计算平均值得出的而不是采用连接操作得出的。如公式(4)所示:
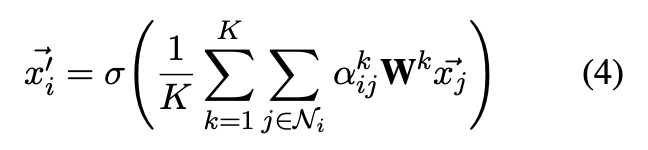
关系十分重要
虽然 GAT 取得了成功,但是由于忽略了知识图谱构成中不可或缺的关系(边)上所具有的特征,所以 GATs 方法并不适用于知识图谱。在知识图谱中,实体依据与它们相连的关系在三元组中具有不同的作用。因此作者提出了一种将关系与相邻节点特征相结合的新型方法构建潜入模型。据此,定义了一个单独的注意层,它是构成本文中提出的模型的构建单元。与 GAT 类似,本文中的框架对注意力机制的特定选择是不可知的。
本文提出的模型中的每一层都将两个嵌入矩阵作为输入。实体嵌入矩阵用矩阵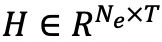
的嵌入向量,
表示实体总数,T 表示每个实体嵌入向量的特征维数。用一个相同结构的矩阵
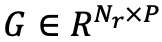
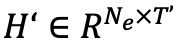
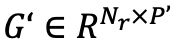
为获得实体的新的嵌入向量,学习了一种与
相连的每一个三元组的表示。如公式(5)所示,通过对实体和关系特征向量的连接进行线性变换来学习这些嵌入,这些特征向量对应于一个特定的三元组
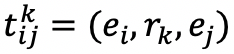
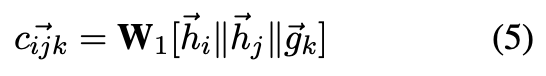
其中是一个三元组
的一个向量表示。向量
、
与
分别是实体
、
和关系
的嵌入向量。除此之外,
表示线性转化矩阵。该模型学习了每一个三元组
的重要程度,用
表示。之后用一个权矩阵
作为参数进行线性变换,然后应用 LeakyRelu 非线性得到三元组的绝对注意值(如公式(6))。
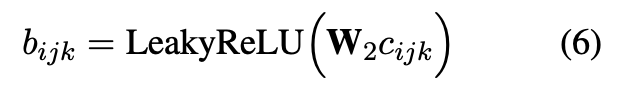
如公式(7)所示,为了获得相对注意力值,对所有进行 softmax 运算。图三展示了对于一个三元组相对注意力值
的计算过程:
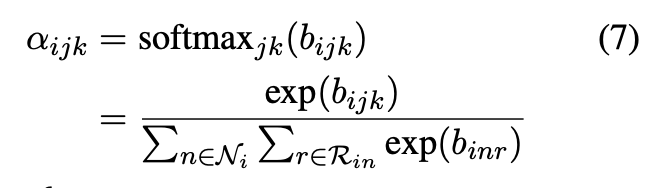
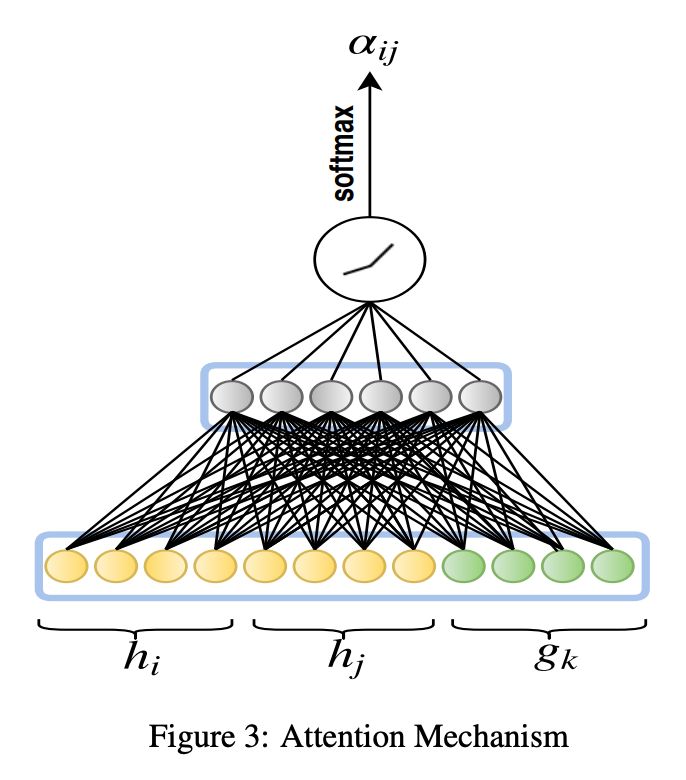
其中表示所有与实体
相邻的实体的集合,
表示连接实体
与
的关系的集合。实体
的新的嵌入向量是由对每一个三元组表示向量按注意力值进行加和得到的。如公式(8)所示:
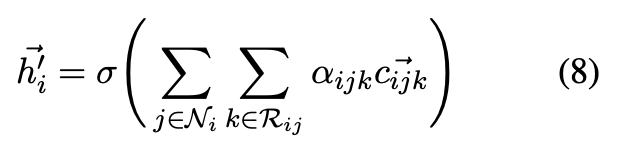
为了稳定学习过程,且压缩更多的有关邻居结点的信息,采用多头注意力机制。将 M 个独立的注意力机制用来计算,将其连接,可以表示如下:
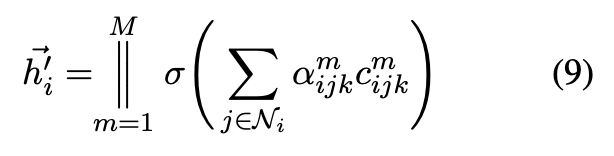
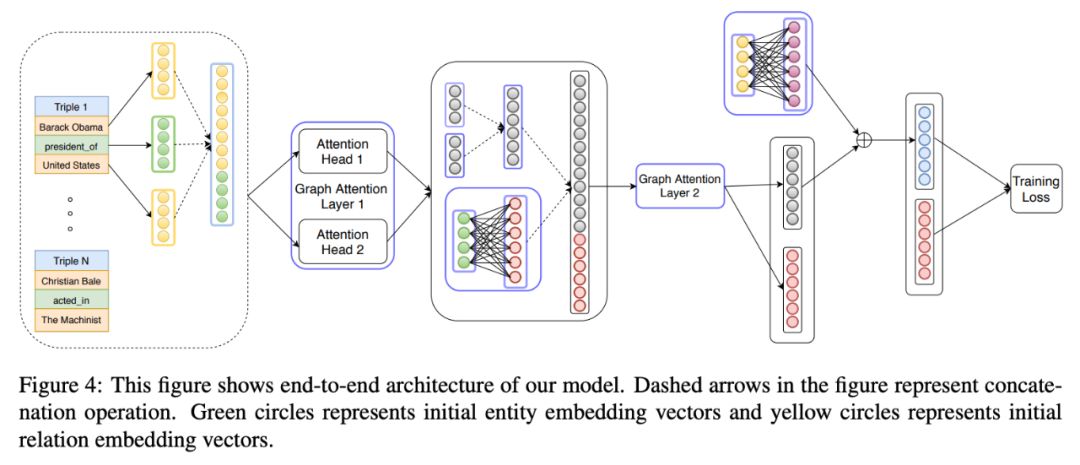
图四展示了图注意力层结构。如公式(10)所示,将一个权重矩阵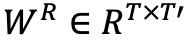

在模型的最后一层作者采用对最终的实体的嵌入向量取平均的方式而不是像多头嵌入一样采用连接嵌入。具体公式如下:
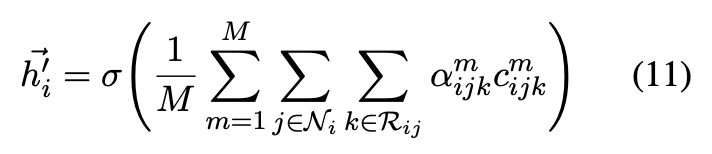
但是当学习新的嵌入向量时,实体丢失了它们最初的嵌入向量信息。因此为了解决这个问题,作者通过用一个权重矩阵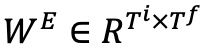
进行线性变换得到
。其中
表示本文模型中作为输入的实体嵌入向量,
表示转化后的实体嵌入向量,
表示初始实体嵌入向量的维度,
表示最终实体嵌入向量的维度。作者将最初的实体嵌入向量的信息加到从模型最终注意力层获得的实体嵌入向量矩阵上,公式如下:
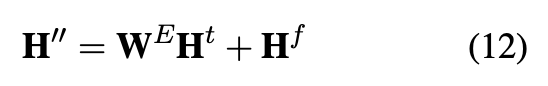
在本文的架构中,作者通过将两个实体间存在的多跳关系作为辅助关系的方式将边的定义扩充为有向路径。这个辅助关系的嵌入是路径中所有关系的嵌入之和。本文的模型迭代地从一个实体的遥远邻居那里积累知识。
如图 2 所述,在本文中模型的第一层,所有实体捕捉了与它们直接相连的邻居信息,在第二层中,U.S 结点从实体 BarackObama、EthanHorvath、Chevrolet 和 WashingtonD.C 结点聚集信息,这些节点中已经从之前层中获得了他们邻居节点 MichelleObama 和 SamuelL.Jackson 的信息。
总之,对于一个 n 层模型来说,传入的信息是根据 n 跳相邻的邻居计算得出的。学习新的实体嵌入向量的聚合过程和相邻多跳结点间的辅助边的引入在图二中都有所展示。对于每一个主要的迭代过程,在第一层之前,在每一个广义的 GAT 层之后,作者对实体的嵌入向量进行了规范化处理。
训练目标
作者提出的模型借鉴了平移得分函数的思想,使得在学习嵌入向量的过程中,假设给定一个真实的三元组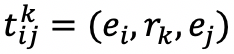
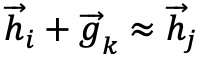
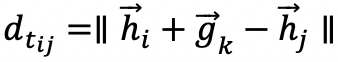
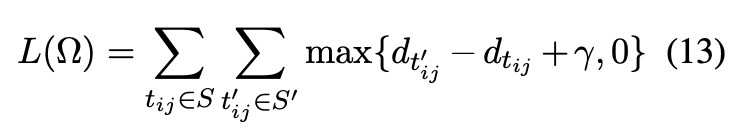
其中 γ>0 是一个边缘超参数,S 是正确的三元组集合,S' 表是不正确的三元组集合。S' 按照如下形式给出:
解码
本篇模型采用 ConvKB 作为解码器,卷积层的目的是分析三元组各个维度上的全局嵌入特性,并归纳出模型中的转化特性。根据多个特征映射得到的得分函数可以写成如下形式:
其中表示第 m 个卷积过滤器,Ω 是表示过滤器数量的超参数,* 是卷积运算符,
当时,
;当
时,
。
实验与结果
数据集
WN18RR
FB15k-237
NELL-995
Unified Medical Language Systems(UMLS)
Alyawarra Kinship
训练方法
通过每次随机用一个无效实体替换有效三元组的头实体或尾实体来产生两个无效三元组集合,并从这两个集合中随机抽取数目相等的无效三元组,以确保头尾实体检测的鲁棒性。用 TransE 方法获得的实体与关系的嵌入向量来初始化本模型。
本文采用一个两步过程来进行训练。首先训练广义 GAT 来编码关于图实体和关系的信息,然后训练诸如 ConvKB 模型作为解码器来进行关系预测任务。传统的 GAT 模型只根据一跳邻居的信息对公式 3 进行更新,但本文的泛化 GAT 则运用多跳邻居对公式 3 进行更新。并通过引入辅助关系来收集稀疏图中邻居的更多信息。采用 Adam 优化器,将其学习率设置为 0.001。最终层得到的实体、和关系的嵌入向量设置为 200 维。
评估方法
在关系预测任务中,通过用其他所有实体对有效三元组中的头实体或尾实体进行替换,并在产生一个(N-1)三元组集合,其中 1 为被替换之前的有效三元组,N 表示经过替换后产生的三元组。最后移除该三元组集合中所有经过替换产生的有效三元组,只保留由替换产生的无效三元组,与替换之前的唯一一个有效三元组组成一个三元组集合。对该集合中的所有三元组进行打分,并根据分数进行排序。用平均倒数排名(MRR),平均排名(MR)以及 Hits@N(N = 1, 3, 10) 指标来对模型进行评估。
结果分析
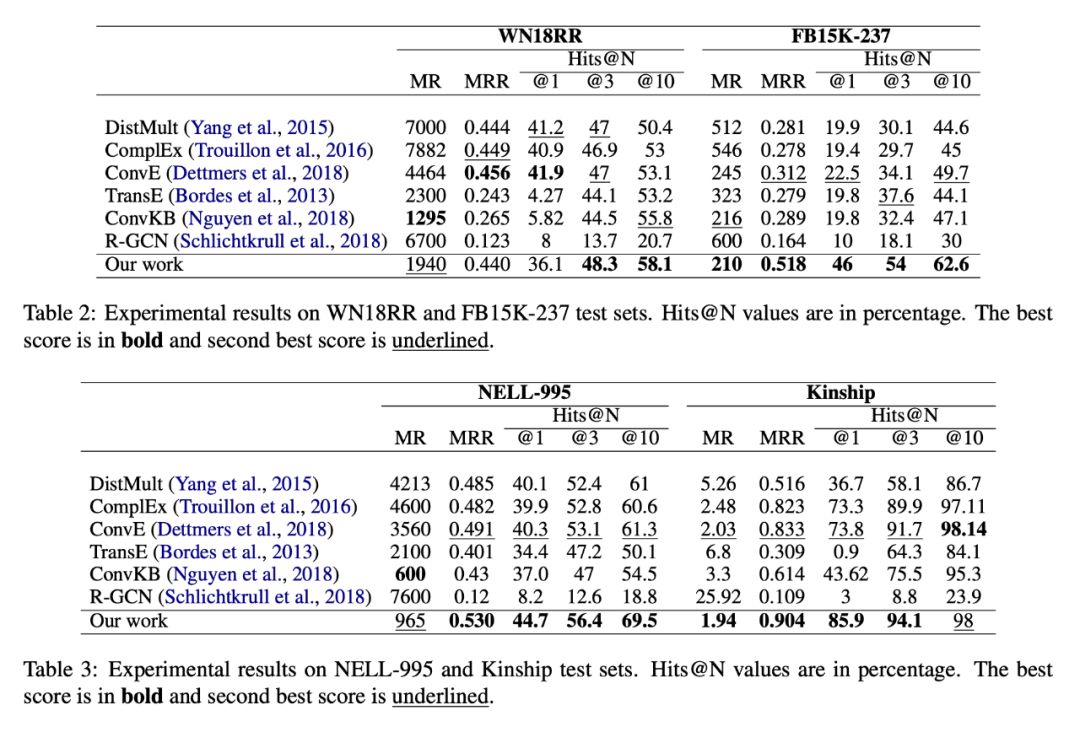
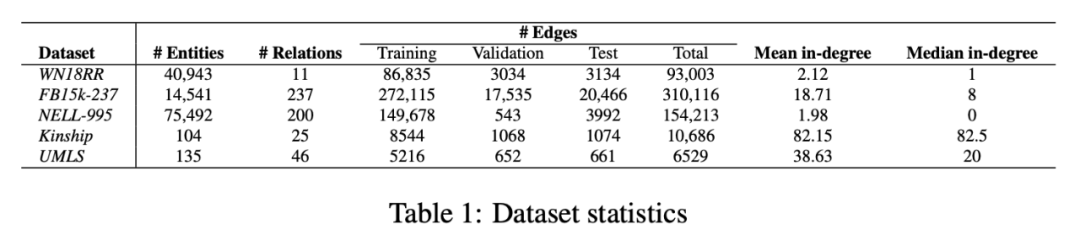
表 2 表 3 上展示了所有数据集上进行预测的结果。结果说明本文提出的模型在数据集 FB15k-237 上,五个指标均达到最好效果。在 WN18RR 数据集上,只有两个指标达到最好效果。
注意力值 vs 轮数:
本文研究了一个特定节点的注意随轮数间隔增加的分布。图 5 展示了在数据集 FB15k-237 上,注意力值与轮数的关系分布。在学习过程的初始阶段,注意力值随机分布。随着训练过程地进行,并且本文的模型从邻居中获得更多的信息,更多的注意力集中于直接邻居,并且从较远的邻居中获得更少的信息。一旦模型收敛,它就学会从节点的 n-hop 邻居中收集多跳和聚类关系信息。
页面排序分析:
本文假设,相对于稀疏图,在稠密图中更容易捕获实体之间复杂且隐藏的多跳关系。为了验证这个假设,本文采用了一个与 ConvE 相似的分析过程,研究了平均页面排名与相对于 Disrmult 中 MRR 的增长的关系,并发现当相关系数为 r=0.808 时具备极强的关联性。表 4 表明,当平均界面排名得到增长时,MRR 的值也同样会得到增长。并观察到 NELL-995 与 WN18RR 之间的相关性出现异常,并将其归因于 WN18RR 的高度稀疏和层次结构,这对本文的方法提出了挑战,因为本文的方法不能以自上而下的递归方式捕获信息。
腐蚀研究
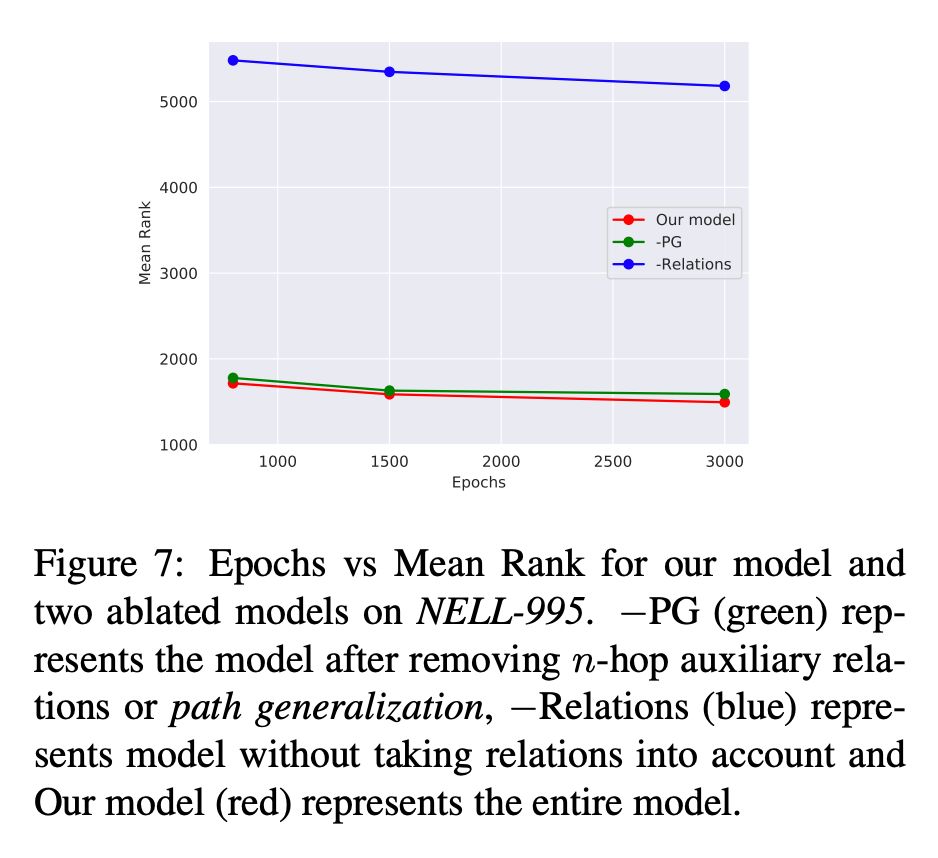
在这里分析了当移除路径信息时(-PG)MR 值的变化。如:移除关系信息和 n 跳信息(-relation)。根据图 7 可以得出当移除关系信息时会对模型产生巨大影响,并可得出关系信息在进行关系与测试至关重要的结论。
总结
本文的贡献:
本文提出的模型学习了新的基于图注意的嵌入,专门用于知识图谱上的关系预测。
本文推广和扩展了图注意机制,以捕获给定实体的多跳邻域中的实体和关系特征。
后续工作方向:
改进本文中的模型以更好地处理层次结构图。
尝试在图注意力模型中捕获实体之间的高阶关系。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码




