NAACL 2018 | 最佳论文:艾伦人工智能研究所提出新型深度语境化词表征
选自arXiv
机器之心编译
参与:路、张倩
不久之前,NAACL 2018 最佳论文公布,机器之心曾介绍了其中一篇(共四篇)。此文介绍了来自艾伦人工智能研究所和华盛顿大学的研究者所著论文《Deep contextualized word representations》,该研究提出了一种新型深度语境化词表征,可对词使用的复杂特征(如句法和语义)和词使用在语言语境中的变化进行建模(即对多义词进行建模)。这些表征可以轻松添加至已有模型,并在 6 个 NLP 问题中显著提高当前最优性能。
1 引言
预训练词表征(Mikolov et al., 2013; Pennington et al., 2014)是很多神经语言理解模型的关键部分。然而,学习高质量词表征非常有难度。它们应该完美建模单词使用方面的复杂特征(如句法和语义),以及单词使用在不同语言环境下的变化(即建模一词多义)。本论文介绍了一种新型深度语境化词表征(deep contextualized word representation),可以直接应对这些挑战,且这种表征能够轻松整合进现有模型,极大地提升大量有难度的语言理解问题中每个用例的当前最优性能。
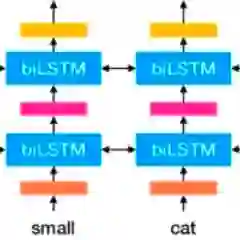
本论文提出的表征与传统的词嵌入不同,每个 token 分配一个表征——即整个输入句子的函数。研究者使用从双向 LSTM 中得到的向量,该 LSTM 是使用成对语言模型(LM)目标在大型文本语料库上训练得到的。因此,该表征叫作 ELMo(Embeddings from Language Models)表征。与之前学习语境化词向量的方法(Peters et al., 2017; McCann et al., 2017)不同,ELMo 表征是深层的,即它们是 biLM 所有内部层的函数。具体来说,对于每个任务,学习堆叠在每个输入单词上的向量线性组合,这可以显著提升性能,效果优于仅使用 LSTM 顶层的表征。
用这种方式组合内部状态可以带来丰富的词表征。研究者使用内在评价进行评估,结果显示更高级别的 LSTM 状态捕捉词义的语境依赖方面(如它们不经修改就可以执行监督式词义消歧任务,且表现良好),而较低级别的状态建模句法结构(如它们可用于词性标注任务)。同时揭示所有这些信号是非常有益的,可以帮助学得的模型选择对每个任务最有帮助的半监督信号。
大量实验证明 ELMo 表征在实践中效果优异。研究者首先展示可在六个不同且有难度的语言理解问题上(包括文本蕴涵、问答和情感分析等),将 ELMo 表征轻松添加至现有模型。添加 ELMo 表征可以显著提高每个用例中的当前最优性能,包括将相对误差降低 20%。对于允许直接对比的任务,ELMo 优于 CoVe(McCann et al., 2017),后者使用神经机器翻译编码器计算语境化表征。最后,对 ELMo 和 CoVe 的分析结果显示深层表征优于仅从 LSTM 顶层获取的表征。本研究中训练的模型和代码已公开,研究者期望 ELMo 为其他 NLP 问题提供类似的帮助。
3. ELMo:来自语言模型的嵌入
与广泛使用的词嵌入(Pennington et al., 2014)不同,ELMo 词表征是整个输入句子的函数。这些表征是在两层 biLM 上使用字符卷积计算出来的,作为内部网络状态的线性函数(如 3.2 所述)。这种设定允许我们进行半监督学习,在学习中,biLM 进行大规模的预训练且能够轻易整合进大量现有神经 NLP 架构。
3.2 ELMo
ELMo 是 biLM 中间层表征的任务特定组合。对于每个 token t_k,L-layer biLM 计算一组表征(包含 2L + 1 个)
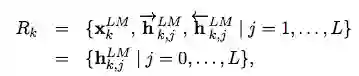
公式中的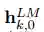
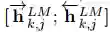
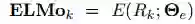
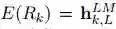
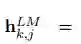
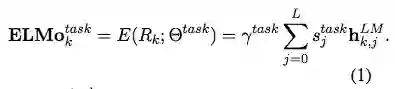
(1)中,s^task 是 softmax 归一化权重,标量参数 γ^task 允许任务模型扩展至整个 ELMo 向量。在实践中,γ 对优化过程有益(详见补充材料)。鉴于每个 biLM 层的激活函数都有不同的分布,在一些情况下,γ 还有助于在加权之前对每个 biLM 层应用层归一化(Ba et al., 2016)。
4 评估
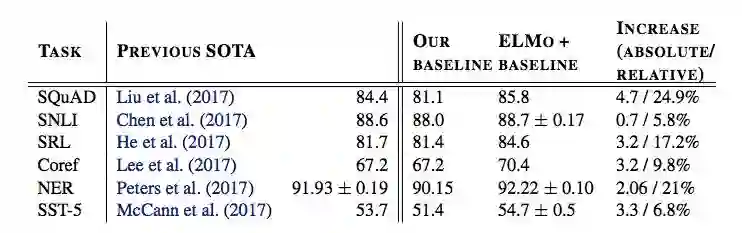
表 1:ELMo 增强神经模型和当前最优(SOTA)单个模型基线在六个 NLP 基准任务上的测试集性能对比。不同任务的性能指标不同:对于 SNLI 和 SST-5 是准确率,对于 SQuAD、SRL 和 NER 是 F1,对于 Coref 是平均 F1。由于 NER 和 SST-5 的测试集较小,研究者的报告结果是使用不同的随机种子进行的五次运行的均值和标准差。「INCREASE」列是基线模型的绝对和相对改进。
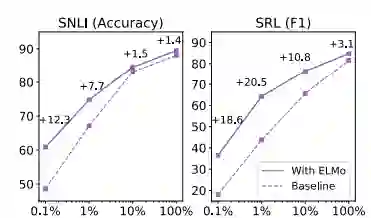
图 1:基线和 ELMo 在 SNLI 和 SRL 上的性能对比,训练集规模的变化幅度是 0.1% 到 100%。
论文:Deep contextualized word representations

论文链接:https://arxiv.org/pdf/1802.05365.pdf
摘要:在本论文中,我们介绍了一种新型深度语境化词表征,可对词使用的复杂特征(如句法和语义)和词使用在语言语境中的变化进行建模(即对多义词进行建模)。我们的词向量是深度双向语言模型(biLM)内部状态的函数,在一个大型文本语料库中预训练而成。本研究表明,这些表征能够被轻易地添加到现有的模型中,并在六个颇具挑战性的 NLP 问题(包括问答、文本蕴涵和情感分析)中显著提高当前最优性能。此外,我们的分析还表明,揭示预训练网络的深层内部状态至关重要,可以允许下游模型综合不同类型的半监督信号。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com