即插即用!掩码表示新形态!DCT-Mask用离散余弦变换提升实例分割性能
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达


本文提出了一种新的掩码表示:DCT-Mask,可以轻松地集成到大多数基于像素的实例分割方法中,显著涨点!性能优于HTC、SOLOv2和CondInst等网络;
作者单位:浙江大学, 阿里巴巴达摩院
1 简介
二值 Grid Mask 表示法广泛用于实例分割中。代表性的实例分割网络模型 Mask R-CNN,它可以在预测28×28二进制网格上的mask。而在实际的场景中低分辨率网格不足以捕获细节,而高分辨率网格会大大增加训练的复杂性。
在本文中,作者通过应用离散余弦变换(DCT)将高分辨率二值Grid Mask编码为紧凑的向量,提出了一种新的 Mask 表示,称为 DCT-Mask,该方法可以集成到大多数基于像素的实例分割方法中。
DCT-Mask 可以在不同的 Structure、Backbone、Dataset 以及训练中获得显著的效果,同时它不需要任何预处理或预训练,并且几乎不会影响速度。特别是对于更高质量的注释和更复杂的Backbone,该方法有很好的效果。DCT-Mask工作良好的主要原因是它获得了具有低复杂度的高质量蒙版表示。
2 相关工作
2.1 动机来源
计算机视觉中的离散余弦变换广泛应用于经典的计算机视觉算法,该算法将空域的RGB图像编码为频域的分量。随着深度学习的发展,许多研究都在研究如何将DCT集成到基于深度学习的计算机视觉框架中。有研究者使用CNN对DCT编码后的图像进行分类;也有学者提出了DCT域的ResNet;也有学者通过将重新排列的DCT系数送给卷积神经网络来对DCT表示进行语义分割;更有人探索了DCT用于目标检测和实例分割,它使用DCT系数作为CNN模型的输入,而不是RGB输入。
在前面所提到的工作中都是使用DCT来提取模型输入的特征。而在本文的实例分割中,作者使用DCT来表示Mask的Ground Truth。
2.2 相关研究与局限
Mask R-CNN:预测了 网格上的Mask,而不考虑对象的大小,正如前面说的一样,低分辨率网格Mask表示质量低,高分辨率网格复杂度高。

Mask Scoring R-CNN:提出了MaskIoU head来学习预测实例Mask的质量。它校准掩模质量和掩模评分之间的不校准;
PointRend:将图像分割作为一个渲染问题,通过在自适应选择的位置对低分辨率预测的掩模进行迭代训练,得到高分辨率的分割预测。它达到了 的分辨率,从 开始,通过5次迭代得到了非常详细的结果。但是多次迭代也增加了推理时间。
降低掩码表示复杂性的研究:有研究者使用去噪卷积自动编码器学习低维形状嵌入空间,通过深度卷积网络直接回归到编码矢量。这种形状预测方法很难适应较大的形状和对象种类;MEInst使用PCA将二维掩码编码为一个紧凑的向量,并将其合并到一个Single-Shot实例分割框架中。但是它只编码 分辨率的Mask,由于Mask的表现质量很低,所以在大目标上表现很差;PolarMask用极坐标下的轮廓表示Mask,将实例分割问题定义为极坐标下通过实例中心分类和稠密距离回归来预测实例的轮廓。
以上研究虽然通过设计紧凑的掩模表示实现了更高的运行速度,但它们的掩码质量下降,实例分割的性能也不理想。因此在本文中,作者探索如何提高掩码质量同时可以降低复杂度,以达到性能和运行速度之间的平衡。
3 本文方法
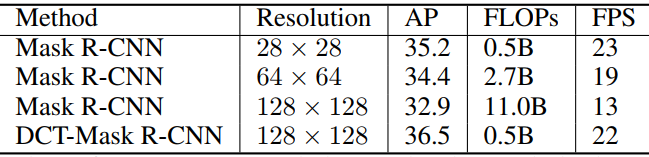
通过下表可以看出,当二进制掩码表示的分辨率从28×28增加到128×128时,掩码质量提高,但是由于训练复杂度的大幅增加,掩模AP显著降低。基于此,作者提出DCT掩码表征来降低复杂度。

3.1 DCT Mask 表征
DCT掩码表示类似于JPEG,它将二进制掩码编码成一个紧凑的向量。如下图所示,对于二进制Ground Truth Mask ,其中H和W分别表示高度和宽度。文中用双线性插值将它调整为 ,其中K是Mask的大小。本文中设置K=128。值得注意的是Mask R-CNN中的K=28。

1)、转换到频域:
2-D DCT-II将
转换为频域
:

其中,当 时, ;否则, 。
由于DCT具有较强的能量压缩特性,文中以锯“齿形”的方式从 中选取第一个N维向量 。这里DCT掩模向量 就是掩模表示。
2)、恢复到原始域:
通过将其它部分填入0从
中恢复
。然后采用二维逆DCT(2D DCT):

3)、双线性插值
采用双线性插值将
调整为
。
通过以上3步便可以将掩模 的GT编码为一个紧凑向量V,然后对V进行解码重构掩模 。这样便可以使用一个n维向量V作为Mask,而不是二值图像,这大大减少了冗余。从Figure 2可以看出,DCT掩模可以准确地捕捉到物体的形状,丢弃的高频分量距离边界也非常少。

通过上表可以看出, 和 之间的IoU度量来评价掩模表示的质量。DCT掩码表示采用100维和700维向量,实现与二进制网格掩码表示中的 和 矩阵相同的IoU。这表明了DCT掩码表示的有效性。
3.2 Mask R-CNN+DCT Mask
1)、模型结构
Mask R-CNN是一种两阶段的实例分割方法。第一阶段通过区域建议网络(RPN)生成关于区域的建议。第二阶段包括检测分支和掩码分支。检测分支基于R-CNN Head的第一阶段建议,预测对象的类别并细化边界框。掩模分支通过Mask Head进行像素分类生成目标的Mask。

利用DCT掩码表示,掩码分支的预测是一个紧凑的向量,而不是二进制网格。如上图所示使用4个卷积层来提取掩模的特征,使用3个全连接层来回归DCT掩模向量。卷积层的设置与Mask R-CNN相同,其中kernel size为3,filter number为256。前两层全连接层的输出大小为1024,最后一层的输出大小为DCT掩模向量的维数。此外,Mask Head的预测是class-agnostic的,通过保持较小的输出规模来降低训练复杂度。
2)、损失函数
Mask分支损失函数:
在DCT掩模表示中,Mask分支的Ground Truth是由DCT编码的向量。这就会带来回归问题。这里定义Mask分支的损失函数如下:

其中,式中,
,
分别表示GT真值和预测向量的第i个元素。
为正样本的指标函数。D是距离度量。
模型损失函数:

其中,其中 为检测分支的损失。 是Mask分支相应的权值。
3)、模型推理:
在推理过程中遵循标准的Mask R-CNN推理过程。在NMS之后,top-k得分框被选择并用RoIAlign后送入Mask分支。Mask分支预测每个边界框的DCT Mask向量。Box内的Mask由DCT掩码向量解码生成。
总之,保持其他部分完全不变,这里只修改Mask分支,使用3层FC替换最后2个卷积层。同样,该方法方法也可以很容易地应用到其他基于像素的实例分割框架中。
4 实验
4.1 不同权重的结果
l1损失和平滑l1损失在不同权重下的结果:

最终设置权重为0.007。
4.2 Mask R-CNN与DCT-Mask

4.3 消融实验


4.4 SOTA模型精度对比

参考
[1].DCT-MASK: DISCRETE COSINE TRANSFORM MASK REPRESENTATION FOR INSTANCE SEGMENTATION
上述论文PDF下载
后台回复:DCT-Mask,即可下载上述论文
目标检测综述下载
后台回复:目标检测二十年,即可下载39页的目标检测最全综述,共计411篇参考文献。
下载2
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4000人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!



