超Mask RCNN速度4倍,仅在单个GPU训练的实时实例分割算法 | 技术头条

作者 | Daniel Bolya Chong Zhou Fanyi Xiao Yong Jae Lee
译者 | 刘畅
责编 | Jane
出品 | AI科技大本营(id:rgznai100)
【导读】在论文《YOLACT:Real-time Instance Segmentation》中,作者提出了一种简洁的实时实例分割全卷积模型,仅使用单个 Titan Xp,以 33 fps 在MS COCO 上实现了 29.8 的 mAP,速度明显优于以往已有的算法。而且,这个结果是就在一个 GPU 上训练取得的!
引言
一开始,作者提出了一个疑问:创建实时实例分割算法需要什么?
在过去的几年中,在实例分割方向取得了很大进展,部分原因是借鉴了物体检测领域相关的技术。比如像 mask RCNN 和 FCIS 这样的实例分割方法,是直接建立在像Faster R-CNN 和 R-FCN 这样的物体检测方法之上。然而,这些方法主要关注图像性能,而较少出现 SSD,YOLO 这类关注实时性的实例分割算法。因此,本文的工作主要是来填补这一空白。SSD 这类方法是将 Two-Stage 简单移除成为 One-Stage 方法,然后通过其它方式来弥补性能的损失。而这类方法在实例分割领域扩充起来却并不容易,由于 Two-Stage 的方法高度依赖于特征定位来产生 mask,而这类方法不可逆。而 One-Stage 的方法,如 FCIS,由于后期需要大量的处理,因此也达不到实时。
YOLACT 介绍
基于此,作者在这项研究中提出一种放弃特征定位的方法——YOLACT(You Only Look At CoefficienTs)来解决实时性问题。
YOLACT 将实例分割分解为两个并行任务:(1)在整副图像上生成非局部原型 mask 的字典;(2)为每个实例预测一组线性组合系数。 从这两部分内容生成全图像实例分割的想法简单:对于每个实例,使用预测的系数线性组合原型,然后用预测边界框来 crop。作者通过这种方式来让网络学会如何定位实例mask本身,这些在视觉上,空间上和语义上相似的实例,在原型中却不同。
作者发现,由于这个过程不依赖于 repooling,因此此方法可以产生高质量和高动态稳定性的 masks。尽管本文使用了全卷积网络实现,但模板 mask 可以自己在具有平移变换情况下对实例进行定位。最后,作者还提出了 Fast NMS,这比标准 NMS 的快12ms,并且性能损失很小。
这种方法有是三个优点:第一,速度非常快。第二,由于没使用类似“repool”的方法,mask的质量非常高。第三,这个想法可以泛化。生成原型和mask系数的想法可以添加到现有的目标检测的算法里面。
算法
算法介绍
为了提高实例分割的速度,作者提出了一种快速、单阶段的实例分割模型——YOLACT。主要思想是将 Mask 分支添加到单阶段目标检测框架中。因此,研究人员将实例分割任务分解为两个更简单的并行任务,将其组合以形成最终的 Mask。YOLACT 的网络结构图如下图所示。
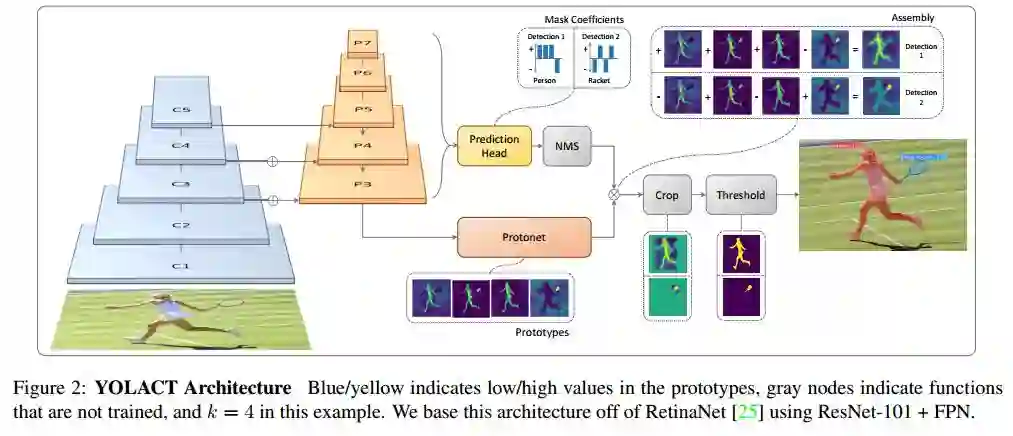
作者将实例分割的复杂任务分解为两个更简单的并行任务,这些任务可以组合以形成最终的 mask。 第一个分支使用 FCN 生成一组图像大小的“原型掩码”(prototype masks),它们不依赖于任何一个实例。第二个是给目标检测分支添加额外的 head ,用于预测每个 anchor 的“掩码系数”(mask coefficients)的向量,其中 anchor 是在编码原型空间中的实例表示。最后,对经过NMS后的每个实例,本文通过线性组合这两个分支来为该实例构造mask。
YOLACT 将问题分解为两个并行的部分,利用 fc 层(擅长产生语义向量)和 conv 层(擅长产生空间相干掩模)来分别产生“掩模系数”和“原型掩模” 。因为原型和掩模系数可以独立地计算,所以 backbone 检测器的计算开销主要来自合成(assembly)步骤,其可以实现为单个矩阵乘法。通过这种方式,论文中的方法可以在特征空间中保持空间一致性,同时仍然是 One-Stage 和快速的。
原型生成

原型生成分支是预测整个图像的一组K个原型 mask。采用 FCN 来实现protonet ,其最后一层有 k 个 channels(每个原型一个)并将其附加到 backbone 特征层。
掩码系数(mask coefficients)
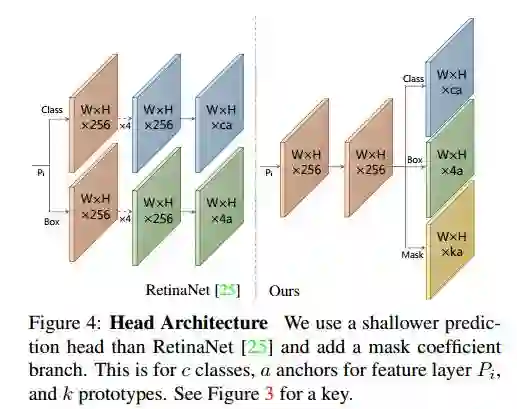
在实验中,YOLACT 为每个Anchor预测(4+C+k)个值,额外 k 个值即为 mask系数。另外,为了能够通过线性组合得到 mask,很重要的一步是从最终的mask 中减去原型 mask。换言之,mask 系数必须有正有负。所以,在 mask系数预测时使用了 tanh 函数进行非线性激活,因为 tanh 函数的值域是(-1,1)。
合成Mask
为了生成实例掩模,通过基本的矩阵乘法配合 sigmoid 函数来处理两分支的输出,从而合成 mask。

其中,P 是 h×w×k 的原型 mask 集合;C 是 n×k 的系数集合,代表有 n 个通过 NMS 和阈值过滤的实例,每个实例对应有 k 个 mask 系数。
Loss 设计:Loss 由分类损失、边界框回归损失和 mask 损失三部分组成。其中分类损失和边界框回归损失同 SSD,mask 损失为预测 mask 和 ground truth mask 的逐像素二进制交叉熵。
Mask 裁剪:为了改善小目标的分割效果,在推理时会首先根据检测框进行裁剪,再阈值化。而在训练时,会使用 ground truth 框来进行裁剪,并通过除以对应 ground truth框面积来平衡 loss 尺度。
Emergent Behavior
在实例分割任务中,通常需要添加转移方差。在 YOLACT 中唯一添加转移方差的地方是使用预测框裁剪 feature map 时。但这只是为了改善对小目标的分割效果,作者发现对大中型目标,不裁剪效果就很好了。
Backbone 检测器
因为预测一组原型 mask 和 mask 系数是一个相对比较困难的任务,需要更丰富更高级的特征,所以在网络设计上,作者希望兼顾速度和特征丰富度。因此,YOLACT 的主干检测器设计遵循了 RetinaNet 的思想,同时更注重速度。 YOLACT 使用 ResNet-101 结合 FPN 作为默认主干网络,默认输入图像尺寸为550×550,如上图所示。使用平滑-L1 loss 训练 bounding box 参数,并且采用和 SSD 相同的 bounding box 参数编码方式。 使用 softmax 交叉熵训练分类部分,共(C+1)个类别。同时,使用 OHEM 方式选取训练样本,正负样本比例设为 1:3. 值得注意的是,没有像 RetinaNet 一样采用 focal loss。
快速 NMS(fast NMS)
a.对每一类的得分前 n 名的框互相计算 IOU,得到 C*n*n 的矩阵X(对角矩阵),对每个类别的框进行降序排列。
b.其次,通过检查是否有任何得分较高的框与其 IOU 大于某个阈值,从而找到要删除的框,通过将 X 的下三角和对角区域设置为 0 实现。这可以在一个批量上三角中实现,之后保留列方向上的最大值,来计算每个检测器的最大 IOU 矩阵 K。
c.最后,利用阈值 t(K<t)来处理矩阵,对每个类别保留最优的检测器。
论文实验
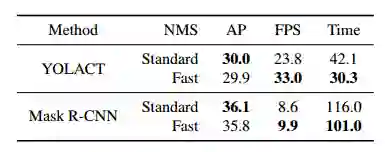
作者在 MS COCO 的 test-dev 数据集上对 YOLACT 和目前最好的方法进行了性能对比。本文的关注点在于速度的提升,且所有实验都是在 Titan Xp 上进行的,故一些结果和原文中的结果可能略有不同。
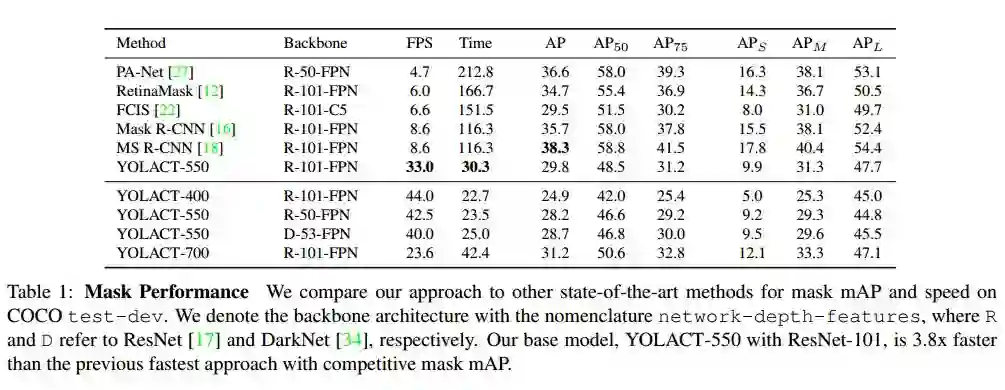
实验来验证本文模型在不同大小输入图像情况下的性能。除了基本的 550×550 模型,还有输入为 400×400 和 700×700 的模型,相应地也调整了 anchor 的尺寸(sx=s550/550*x s)。降低图像大小会导致性能的大幅度下降,这说明越大的图像进行实例分割的性能越好,但提升图像尺寸带来性能提升的同时会降低运行速度。
当然作者还做了关于 Mask 质量与视频动态稳定性相关的对比实验,并详细分析了优劣缘由。详见论文。
总结
YOLACT 网络的优势:快速,高质量的 mask,优良的动态稳定性。
YOLACT 网络的劣势:性能略低于目前最好的实例分割方法,很多由检测引起的错误,分类错误和边界框的位移等。
此外,作者最后还提到了该方法的一些典型错误:
1)定位误差:当场景中一个点上出现多个目标时,网络可能无法在自己的模板中定位到每个对象,此时将会输出一些和前景 mask 相似的物体,而不是在这个集合中实例分割出一些目标。
2)特征泄露(Leakage):网络对预测的集成 mask 进行了裁剪,但并未对输出的结果进行去噪。这样一来,当b-box 准确的时候,没有什么影响,但是当 b-box 不准确的时候,噪声将会被带入实例 mask,造成一些“泄露”。
解读到这里告一段落,感兴趣的小伙伴可以在下方地址中阅读 Paper 原文~
原文地址:
https://arxiv.org/pdf/1904.02689.pdf
代码地址:
https://github.com/dbolya/yolact
(*本文为 AI科技大本营编译文章,转载请微信联系1092722531)
◆
精彩推荐
◆

推荐阅读:
免费GPU哪家强?谷歌Kaggle vs. Colab
高能!8段代码演示Numpy数据运算的神操作
从3年前接触区块链, 到开发出装机量最大客户端Geth, 看看人家的职业发展之路|人物志
互联网大佬高考往事
他是哈佛计算机博士,却成落魄画家,后逆袭为硅谷创业之父 |人物志
Lambda 表达式有何用处?


