【学界】滑动窗口也能用于实例分割,陈鑫磊、何恺明等人提出图像分割新范式
来源:机器之心
滑动窗口在目标检测中非常重要,然而最近何恺明等研究者表明,这个范式同样可以用于实例分割。他们提出一条新的道路,即将密集实例分割看成一个在 4D 张量上进行的预测任务,这也就是 TensorMask 通用框架。
该论文是 FAIR 实验室完成的,除了何恺明外,一作陈鑫磊博士也非常厉害。陈鑫磊本科毕业于浙江大学,博士在 CMU(2012-2018)完成,他从 2011 年开始就在 AAAI、ICCV 和 CVPR 发过 13 篇顶会论文,其中有 8 篇是一作。
为什么需要 TensorMask
滑动窗口范式(sliding-window paradigm)是计算机视觉领域最早、最成功的概念之一,这种技术通过查看一组密集图像上的每个窗口来寻找目标,和卷积神经网络产生了自然的关联。
最近,避开第二阶段的提炼,以直接滑动窗口预测为核心的边界框目标检测器开始复苏,并取得了良好的效果。但相比之下,该领域的密集滑动窗口实例分割并未取得同步的进展。为什么边界框的密集检测发展如此之快,但实例分割却落后了呢?这是一个具有根本科学意义的问题。
该论文的目标就是弥补这一差距并为密集实例分割研究奠定基础,为了这个目标,作者提出了一种名为 TensorMask 的框架。
利用 TensorMask 框架,研究者在 4D 张量的标度索引列表上开发了一个金字塔结构,并将其命名为 tensor bipyramid。
他们的实验表明,TensorMask 可以生成与 Mask R-CNN 相似的结果(见图 1、2)。

图 1:TensorMask 的输出。

图 2:TensorMask 和以 ResNet-101-FPN 为骨干网络的 Mask R-CNN 的示例结果。二者在定性和定量标准上都非常接近。表明这一密集滑动窗口范式在实例分割任务上也可以非常有效。
这些有力的结果表明,TensorMask 框架可以为将来的密集滑动窗口实例分割研究拓宽道路。说不定在挖了全景分割这个坑后,恺明大神又为我们指引了一条新的发展方向。
什么是 TensorMask
研究者认为,目前还缺乏定义密集 Mask 表征的概念以及这些概念在神经网络中的有效实现。边界框有不考虑比例的固定低维表征,但分割 Mask 可以利用更加结构化的丰富表征。例如,每个 Mask 本身都是一个 2D 空间图,较大对象的 Mask 可以从较大空间图的使用中获益。为密集 Mask 开发有效的表征是实现密集实例分割的关键一步。
为了解决这一问题,研究者定义了一组核心概念来表征高维张量 Mask,这使得探索密集 Mask 预测的新型网络成为可能。研究者提出了若干此类网络并利用其进行了实验,以展示所提出的表征方法的优点。TensorMask 框架创建了第一个密集滑动窗口实例分割系统,达到的效果接近 Mask R-CNN。
TensorMask 表征的核心理念是利用结构化的 4D 张量在一个空间域上表征 Mask。这一理念与之前分割与类无关的对象的工作形成了对比,如 DeepMask 和使用结构化 3D 张量的 InstanceFCN,其中的 Mask 被打包到第三个「通道」轴。该通道轴与表征目标位置的通道轴不同,它没有明确的几何意义,因此难以操纵。通过使用一个基本的通道表征,人们错过了从使用结构化数组将 Mask 表征为 2D 实体中获益的机会,类似于表征 2D 图像的 MLP 和 ConvNet 之间的差别。
与这些通道导向的方法不同,本文作者提出利用 4D 形状张量(V, U, H, W),其中的(H, W)表征目标位置,(V, U)表征相关 Mask 位置,它们都是几何子张量,即它们都有与图像相关的单元和几何意义定义完整的轴。这种从非结构化通道轴上的编码 Mask 到使用结构化几何子张量的视角转变,使得定义新的运算和网络体系架构成为可能。这些网络可以直接以几何上有意义的方式在以 (V, U) 子张量上进行运算,包括坐标变换、上/下尺度变换和尺度金字塔的使用。
论文:TensorMask: A Foundation for Dense Object Segmentation

链接:https://arxiv.org/pdf/1903.12174.pdf
摘要:在一个密集、规则的网格上生成边界框目标预测的滑动窗口目标检测发展迅速并得到了广泛的应用。相比之下,当下流行的目标分割方法主要是先检测目标边界框,然后裁剪并分割这些区域,如流行的 Mask R-CNN。
在本文中,我们研究了密集滑动窗口实例分割的范式,这一方法目前鲜有人研究。我们认为,这一任务与语义分割、边界框目标检测等其他密集预测任务有着本质上的不同,因为在这一任务中,每个空间位置的输出本身就是一个几何结构,具有自己的空间维度。
为了使其更加清晰,我们将密集实例分割看成一个在 4D 张量上进行的预测任务,提出了 TensorMask 通用框架,这一框架可以显式地捕捉这一几何机构并使得在 4D 张量上的新型操作成为可能。
我们证明了,这一张量视角优于忽略这种结构的基线方法,其结果可媲美 Mask R-CNN。这些有力的结果表明,TensorMask 可以为密集 Mask 预测取得新进展提供基础,有助于我们更全面地理解这一任务。代码将会开源。
Mask 的张量表征
TensorMask 框架的核心概念是使用结构化的高维张量表示密集窗口的图像内容。例如,如果在特征图 W×H 上有一个 V ×U 大小的滑动窗口。那么我们可以使用一个形状为 (C, H, W) 的张量表示所有滑动窗口上的所有 Mask,且每一个 Mask 可以通过 C=V ·U 个像素参数化,这就是 DeepMask 中采用的表征。
实际上,这种表征的潜在观点即使用更高维张量——4D 的 (V, U, H, W)。其中子张量 (V, U) 将一个二维空间实体表示为 Mask。在理解这种张量表征前,我们先要了解 6 个关键概念。
1. 长度的单位(unit of length),每一个空间轴的单位对于理解四维张量都非常重要。直观而言,一个轴的单位定义了对应单个像素的长度,不同的轴有不同的单位。例如,H 和 W 轴的单位表示为σ_HW,它定义为有关输入图像的步辐。
2. 自然表征(Natural Representation),定义单位后,我们就可以描述 (V, U, H, W) 张量的表征意义。在最简单的定义中,它表示 (H, W) 上的滑动窗口,这可以称为自然表征。

3. 对齐表征(Aligned Representation),在自然表征中,位于 (y, x) 的子张量 (V, U) 表示偏移像素 (y+αv, x+αu) 的值,而不是直接表示 (y, x) 的值。在使用卷积计算特征时,保持输入像素和输出像素的对齐能带来很多性能上的提升。

下图展示了这两种表征:
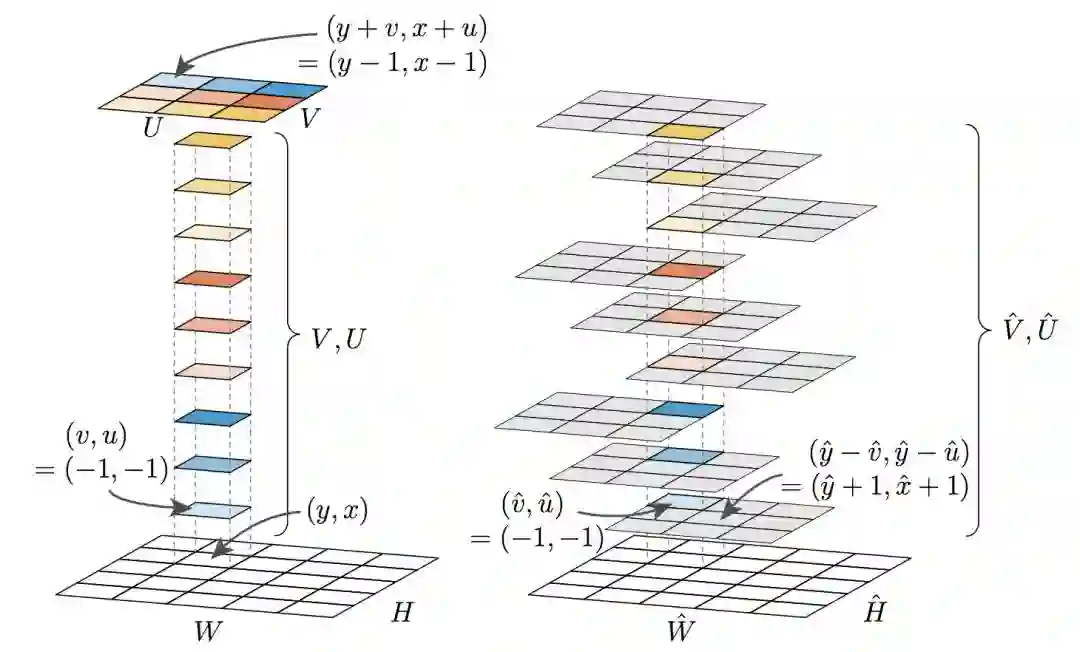
图 3: 左图为自然表征,其中 (V, U) 子张量表示以该像素为中心的窗口。右图为对齐表征,(V hat, U hat) 子张量表示该像素在各窗口的值。
4. 坐标转换(Coordinate Transformation),论文引入了这种方法以在自然表征和为对齐表征之间做转换,这会给设计新架构带来额外的灵活性。
5. 放大转换(Upscaling Transformation),对齐表征允许使用粗粒度的子张量 (V hat, U hat) 创建细粒度的子张量 (V, U)。
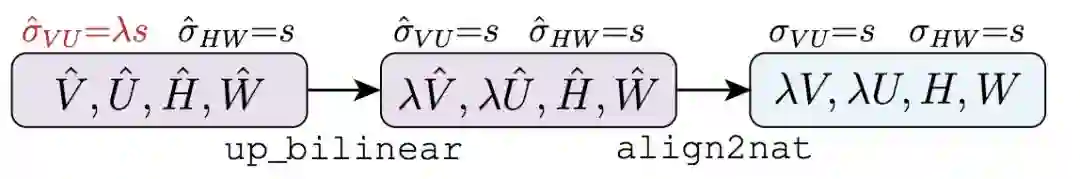
图 4: up align2nat 操作由两个运算组成。
6. 张量 Bipyramid,在目标框检测中,使用特征金字塔非常常见。为此在 Mask 张量中,我们不再使用 V ×U 个单元表示不同尺度的 Mask,我们提出了这种基于尺度来调整 Mask 像素数量的方法。
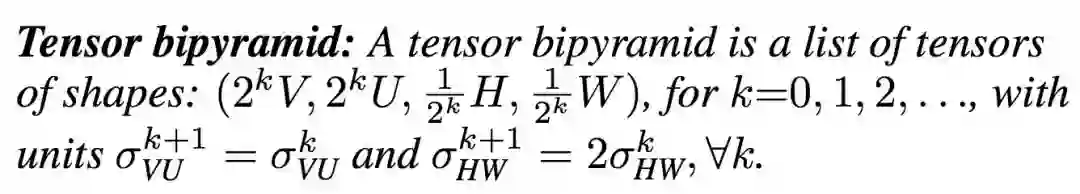
TensorMask 架构
这些模型有一个预测 Mask 的 Head,它在滑动窗口中生成 Mask;同时也有一个进行分类的 Head,它可以预测目标类别。它们类似于滑动窗口目标检测器中的边界框回归和分类分支。边界框预测对于 TensorMask 模型并不是必要的,但可以便捷地包含进来。
如下图 6 所示,我们考虑了四个基线 Head。每一个 Head 接受一张输入特征图 (C, H, W)。
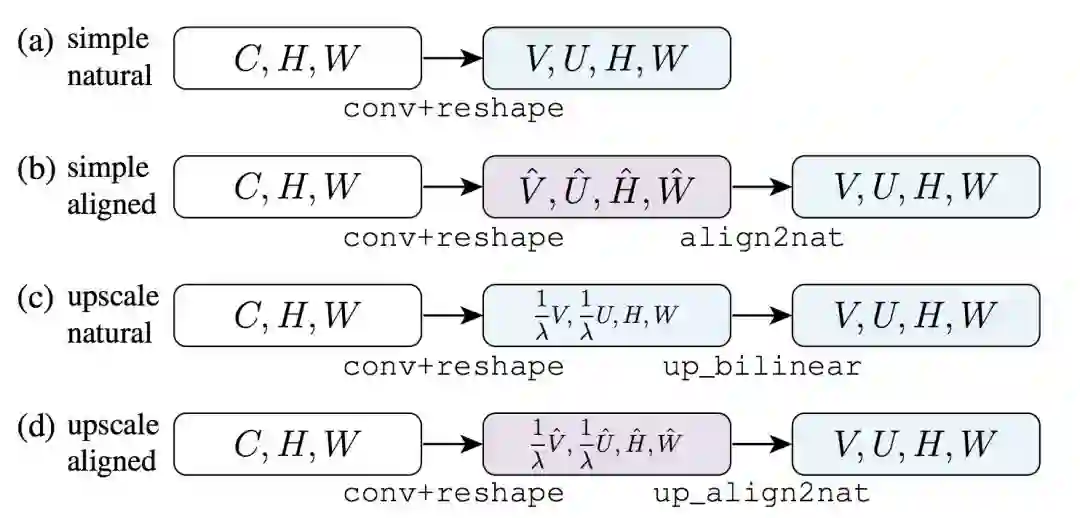
图 6: 基线 Mask 预测 Head,这四种 Head 都从通道为 C 的特征图开始。
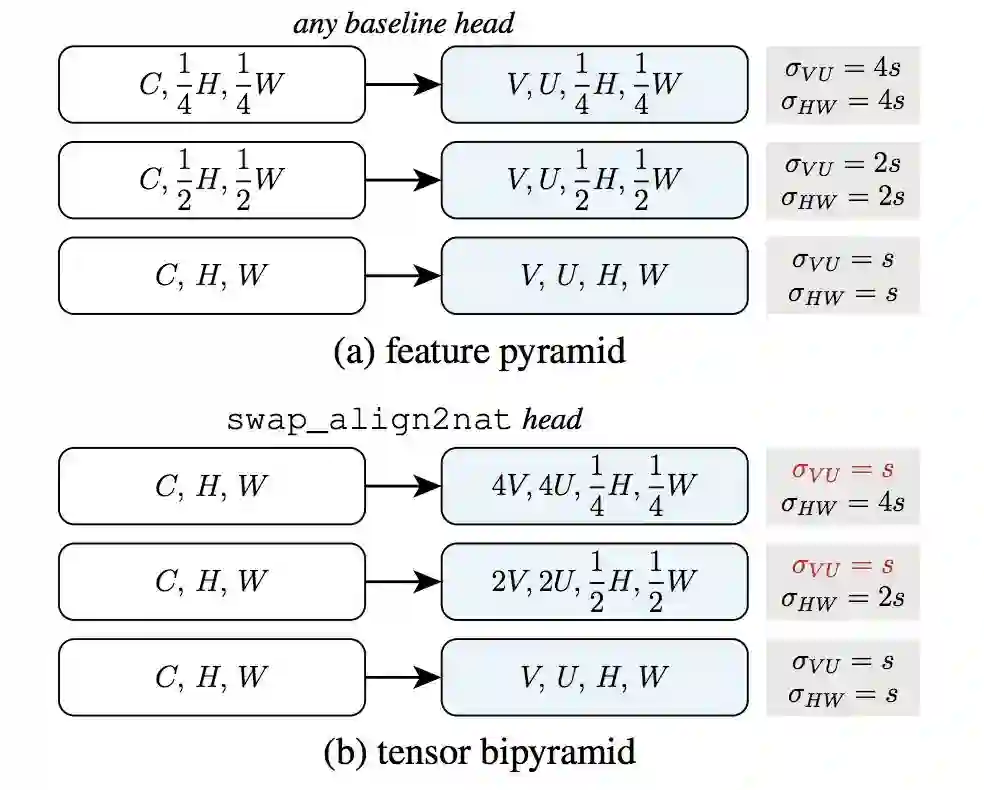
图 7: 使用基线 Head 的特征金字塔,与 Tensor Bipyramid 的对比。
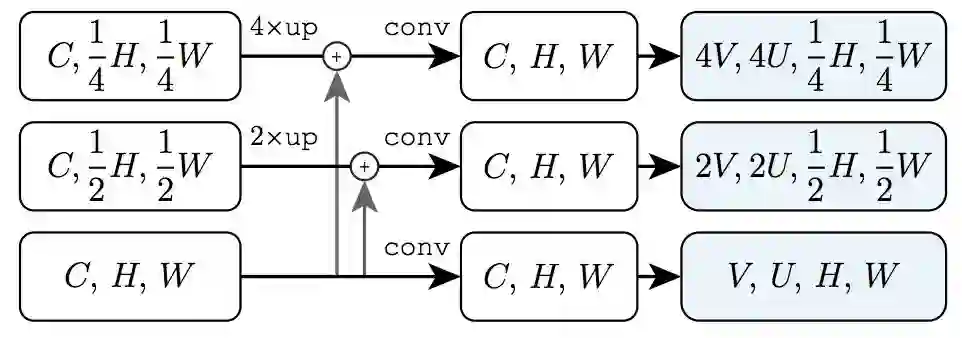
图 8:使用 Tensor Bipyramid 将 FPN 特征图从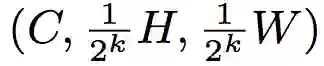
实验
表 3 总结了测试-开发集上的最好 TensorMask 模型,并与当前 COCO 实例分割的主流模型 Mask RCNN 进行了对比。

表 3:在 COCO 测试-开发集上与 Mask R-CNN 实例分割对比

☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得


