
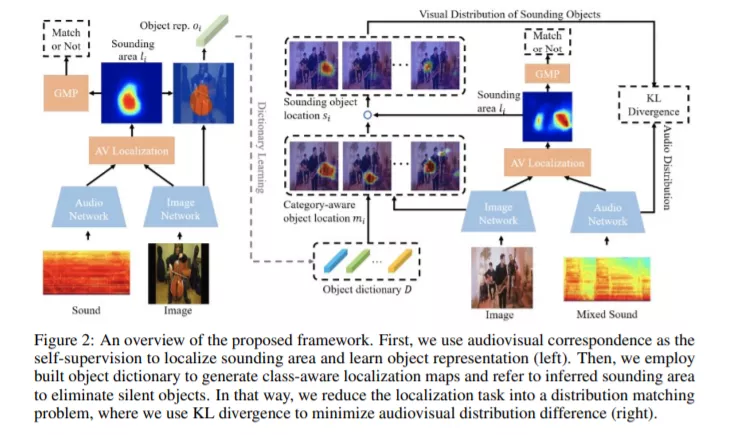
如何在具有多种声源的『鸡尾酒会』中区分不同的声音对象,这对人类来说是一项基本能力,但对当前的机器而言却仍然极具挑战!为此,本文提出一种基于课程学习策略的两阶段框架,实现了自监督下不同发声物体的判别性感知与定位。首先,我们提出在单声源场景中聚合候选声音定位结果以学习鲁棒的物体表征。进而在鸡尾酒会情景中,参考先期课程学习到的物体知识以生成不同物体的语义判别性定位图,通过将视音一致性视为自监督信息,匹配视音类别分布以滤除无声物体和选择发声对象。大量基于合成和真实多声源场景的实验表明,本文所提模型能够实现在无语义类别标注情形下,同时滤除无声物体和指出发声物体的明确位置并判定其类别属性,这在视觉多声源定位上尚属首次。
https://www.zhuanzhi.ai/paper/a3e7afb0a5c86f35871aa5269f7668ae
成为VIP会员查看完整内容
相关内容
Arxiv
3+阅读 · 2018年3月4日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年3月4日