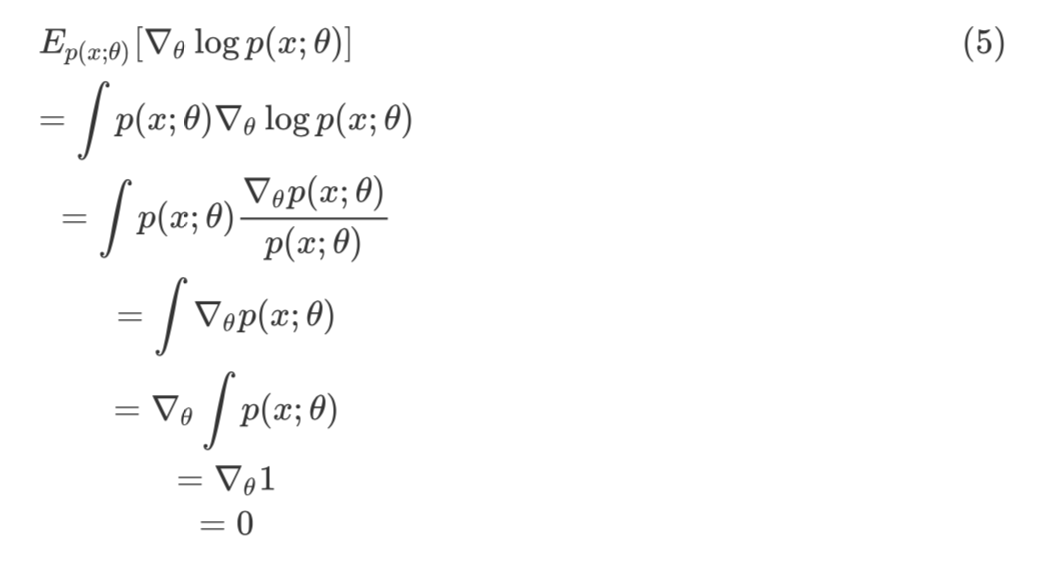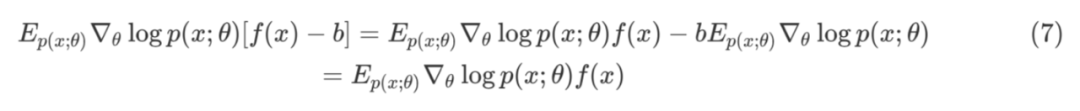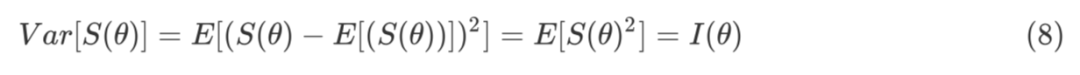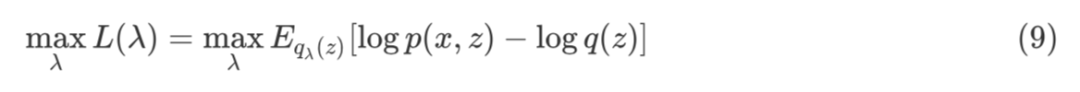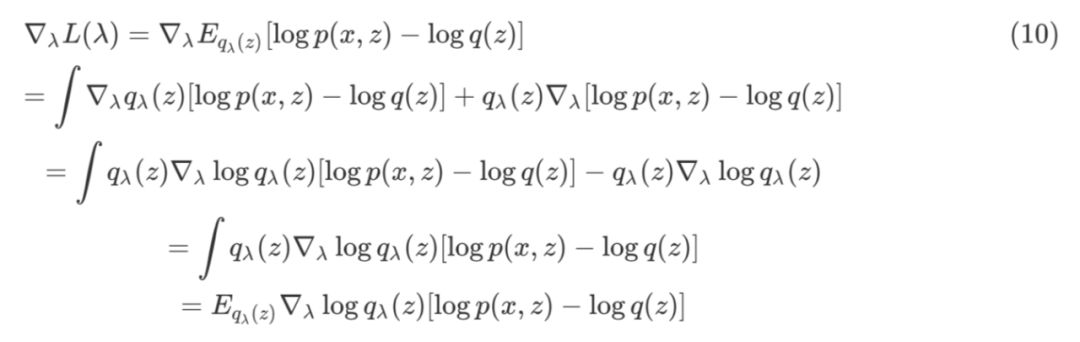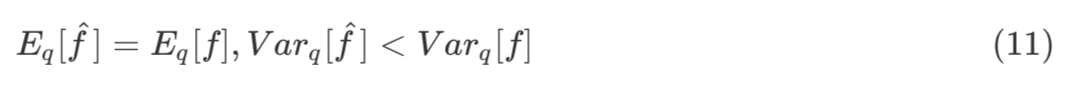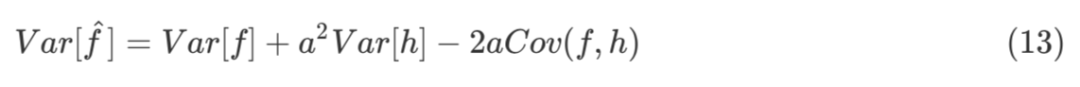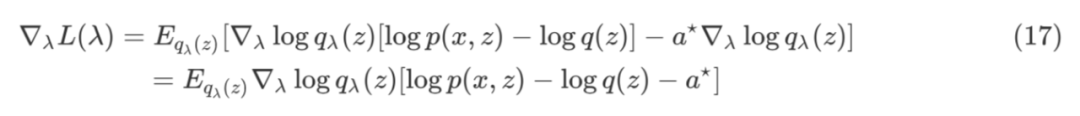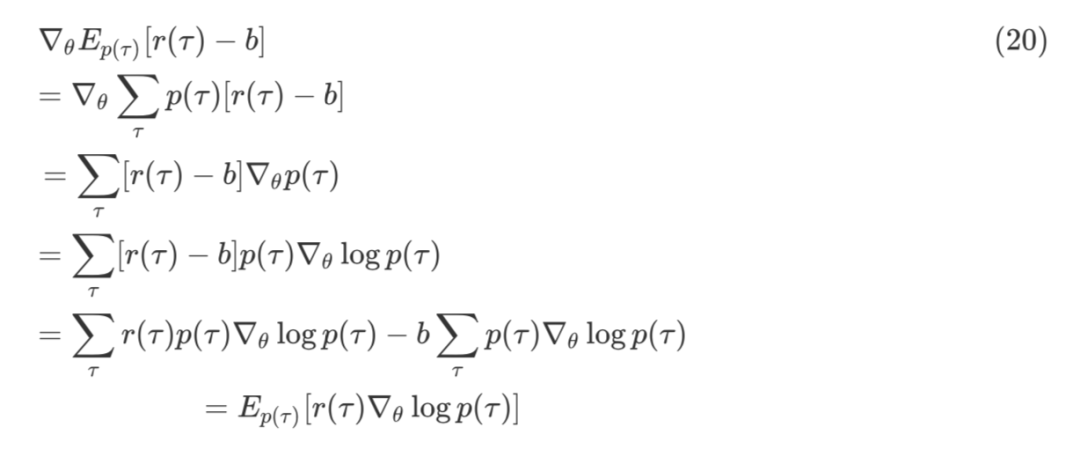引
机器学习中有很多有意思的 Trick,Deepmind 的 Shakir Mohamed (
http://blog.shakirm.com
) 维护了一个高质量的博客,其中写了一系列的机器学习 Trick,包括 Score Function 和 Reparameterisation。
Score Function (SF) 介绍
先从最大似然估计(MLE)说起,在学习统计时,最常见的一个操作是通过 MLE 来估计参数,为方便计算一般都采样对数似然函数(Log Likelihood, LL)作为目标函数,如下:
![]()
记 L(θ)=log p(x;θ),求最优的一个最直接方法就是令其对参数的导数为 0,如下:
![]()
这里 L(θ) 的一阶导数即为Score Function,记为:
![]()
即:求 MLE 相当于求解 Score 方程。如果继续对参数进行求导,会得到另一个非常有价值的量 Fisher Information,如下:
![]()
Fisher Information 经常用来衡量样本信息量,是一个非常有价值的指标(后面专门写一篇介绍 Fisher Information 的文章)。由上式可以看出,Fisher 信息量是 Score Function 的负导数。
SF 之所以在机器学习中非常有用,是因为具有非常好的性质:
![]()
![]()
![]()
这里的 b 是 baseline,在估计梯度时可以起到降低估计方差的作用,具体会在应用中讲到。SF 的方差为 Fisher Information,推导如下:
![]()
用来估计梯度时,可以松弛对代价函数的要求,不必使得代价函数可微,因此可以用来优化很多不可导的目标问题甚至是黑箱问题。
Score Function应用
SF 在机器学习中有着广泛的应用,尤其是在变分推断、强化学习中作用巨大。本节将通过详细的推导,对 SF 的应用进行介绍。
![]()
其中,x 是观测变量,z 是隐变量,q(z) 是变分分布,λ 是变分分布的参数。
![]()
公式 (10) 倒数第三行到导数第二行的推导利用了 score function 的期望为 0 这一性质,基于公式 (10) 就可以利用蒙特卡洛采样进行梯度估计,然后利用随机优化算法进行参数的更新。算法流程图如下:
![]()
参数估计除了要保证无偏之外,还希望估计的方差要尽量小。在此基础上,本文介绍一种经典的降低方差的方法 Control Variates,也会用到 score function 的一些性质。
这里,假设一个估计是 f,希望可以找到一个新估计![]() ,使得
:
,使得
:
![]()
![]()
其中,a 是一个标量,h 是一个函数。由公式 (12) 容易得到,f 和![]() 的期望相同,方差如下:
的期望相同,方差如下:
![]()
直观上讲,Cov(f,h) 越大,新估计的方差越小,控制变量效果越好。令:
![]()
![]()
最优参数值是协方差和方差之比。为了方便计算,函数 h(z) 的选择是 score function,即:
![]()
用新的估计![]() 来替换公式 (10) 中的估计 f,如下:
来替换公式 (10) 中的估计 f,如下:
![]()
基于蒙特卡洛采样对梯度进行估计,从上述推导中可以保证新的估计方差会更小。
强化学习中有一类方法是无模型的策略梯度优化算法,本节将从 Score Function 的角度来推导 REINFORCE 及其变种。
![]()
优化目标是一个函数的期望,如果用基于梯度的优化方法,需要对期望的梯度进行估计。其中,γ 是一个 rollout,r(γ) 是该 rollout 的 reward,p(γ) 是这个 rollout 的分布。所以,由 score function 来推导 REINFORCE 如下:
![]()
通过对 rollout 进行采样来估计该期望的梯度,从而进行参数优化。从推导中可以看出,该方法并不要求代价函数可微,这个性质非常好,对于一些不可微的代价函数甚至是一些没有显式函数形式的黑盒函数的期望进行优化。
根据公式 (5) score function 的期望为 0,可推导出加了 baseline 版本的 REINFORCE。
![]()
通过添加 baseline 这一项,参见公式 (17) 可见,选择一个合适的 baseline 可以有效降低梯度估计的方差,提高优化的效率。
这里简单介绍了利用 score function 的性质来推导 REINFORCE 以及加了 baseline 的版本,对于随机优化问题来说,还有很多地方值得研究,比如估计梯度时的采样分布并不方便采样,可以借助重采样进行采样;比如为了保证收敛效果,可以考虑增加一些相应的约束条件;比如除了 score function 之外,pathwise derivative 也是一个常用的梯度估计方法。
Policy Gradient 有一系列的方法,这类基于优化来做的方法,都有一定的共性,后面会抽空来写一个 Policy Gradient 的小综述,从最基础的 REINFORCE 开始,到最新的一些方法。具体会参考下图:
![]()
总结
score function 是一个非常有用的 trick,在梯度估计和方差降低两个基础问题中作用明显。在很多研究中 score function 还有一些其他名字,如:Likelihood Ratio,Automated Variational Inference,REINFORCE,Policy Gradients 等。
由上述两个应用可以看出,做函数期望的优化问题时,核心思路是通过一些 trick 将期望的梯度变成梯度的期望,从而利用蒙特卡洛采样对期望进行估计,然后利用随机优化算法,对所优化参数进行更新。梯度估计的方差越小,估计就越准确,优化求解效率就会越高。
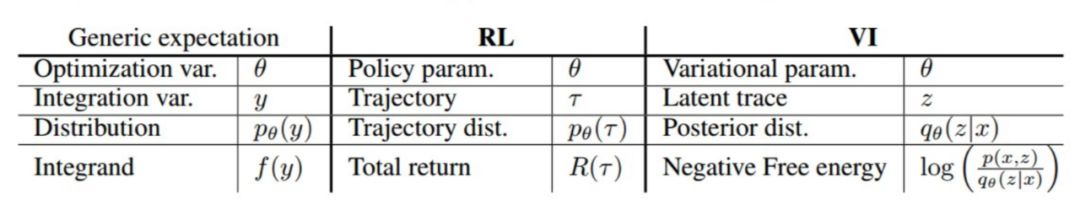
从核心计算问题上来看,变分推断和强化学习是可以统一起来的,下图可以看出,从期望梯度估计问题出发,变分推断和强化学习两个领域中的一些概念可以完全映射起来,两个问题完全可以协同着进行研究,其中一个领域诞生的新计算方法都可以在另一个领域进行尝试。
![]()
参考文献
[1] Ranganath, R., Gerrish, S., & Blei, D. M. (2014). Black Box Variational Inference. In Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics (pp. 814–822).
[2] http://blog.shakirm.com
[3] https://lilianweng.github.io
[4] Weber, T., Heess, N., Eslami, A., Schulman, J., Wingate, D., & Silver, D. (2015). Reinforced Variational Inference. In NIPS ABIW 2015 (2015).