分布式优化算法及其在多智能体系统与机器学习中的应用【附PPT与视频资料】

关注文章公众号
回复"张家绮"获取PPT与视频资料
视频资料可点击下方阅读原文在线观看
导读
分布式优化理论和算法近年来在多智能体系统中得到了广泛的发展与应用,目前在机器学习领域也正在受到越来越多的关注。本文主要介绍目前分布式优化算法的分类和研究现状,以及作者在该方向的一些工作。
作者简介
张家绮,清华大学自动化系在读博士,本科毕业于北京交通大学自动化系,目前主要研究方向为分布式优化与学习。

背景介绍
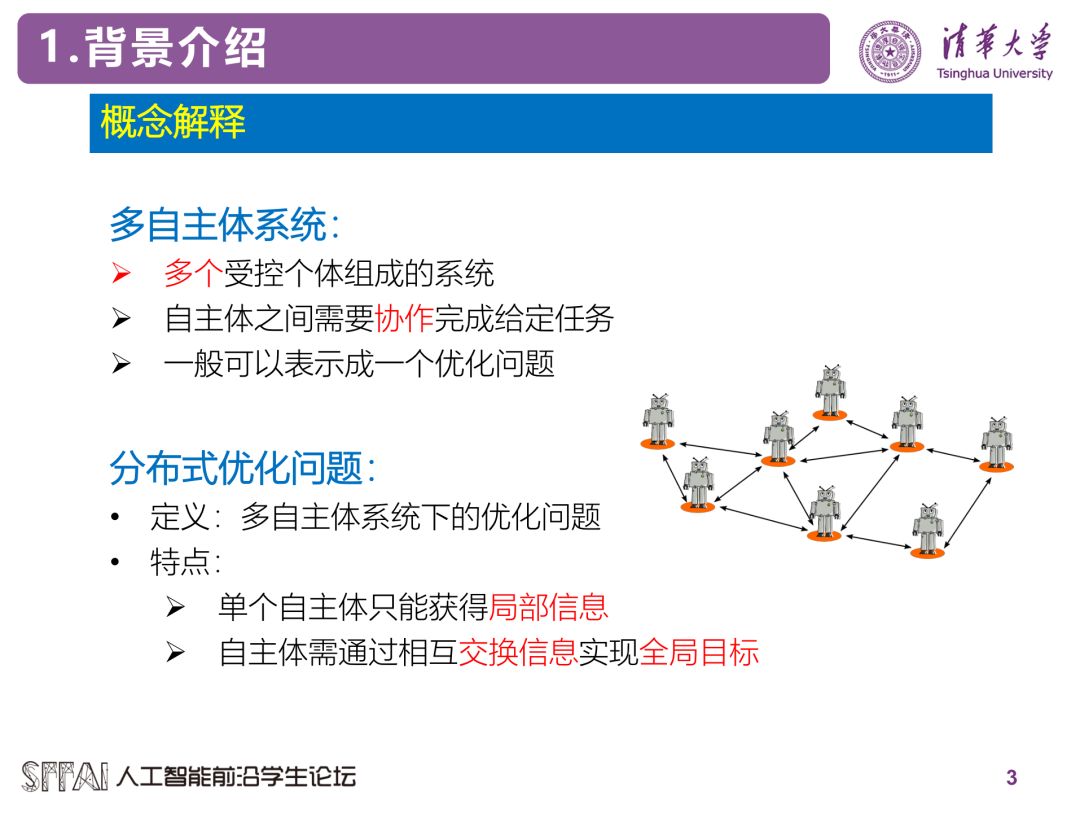
分布式优化问题并没有一个特别明确的定义,根据应用场景的不同具体的形式也有不同,但是主要思想都是采用多个节点来优化全局目标函数。这里的节点可以是CPU, GPU或者服务器,也可以是智能电网中的供电站,无人机编队中的一架无人机,传感器网络中的传感器等。每个节点都有着自己的局部目标函数(损失函数)以及决策变量,而全局目标一般是所有节点上的局部目标函数之和。分布式算法的目标就是通过节点间相互交换信息来使所有节点的决策变量最终收敛于全局目标函数的最小值点。以机器学习为例,分布式优化可以应用于利用多个服务器来优化一个神经网络,其中数据集分布在不同的服务器上,因此每台服务器只能获得一个局部的损失函数。优化算法需要服务器间不断的交换信息。
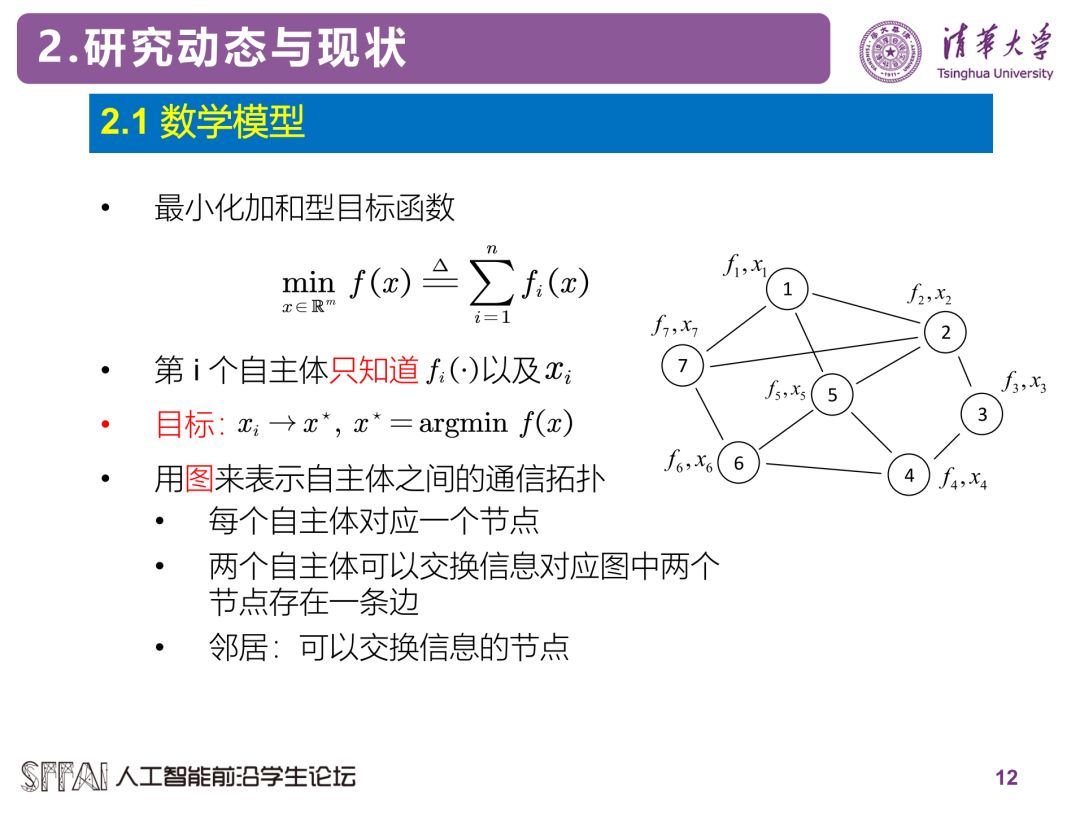
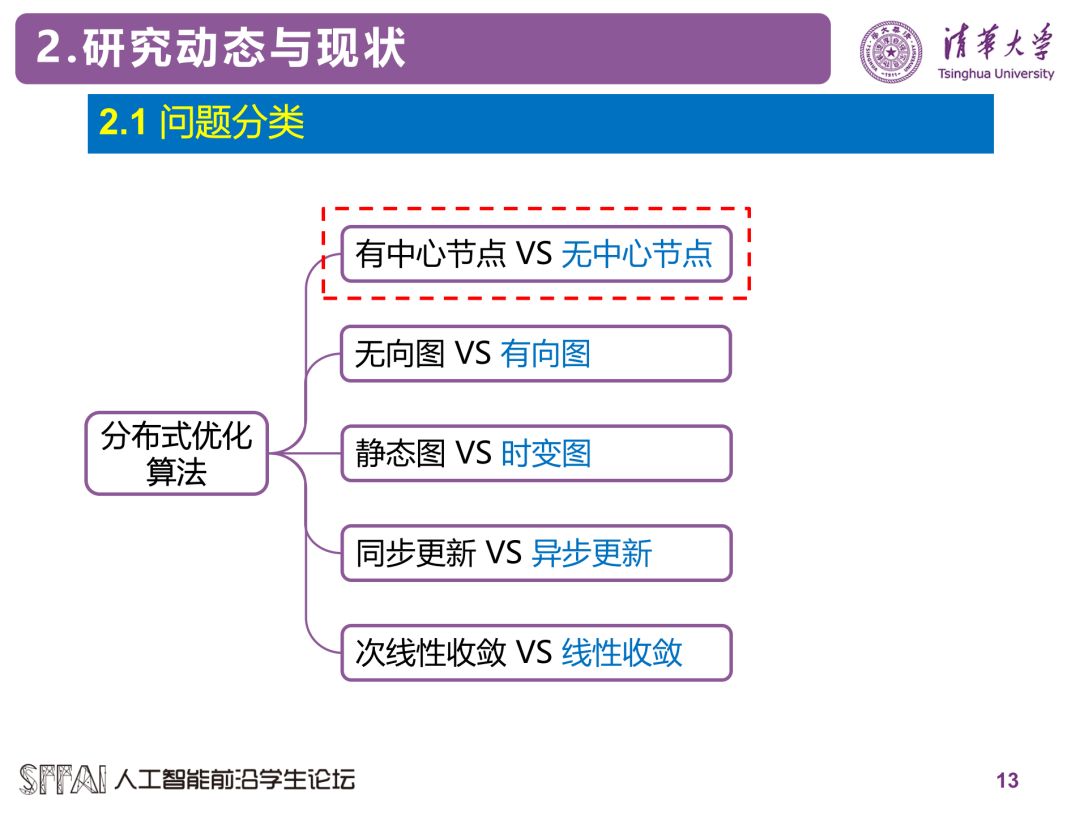
分布式优化方法的大概分类如下所示,这里介绍其中的几种分类方法。
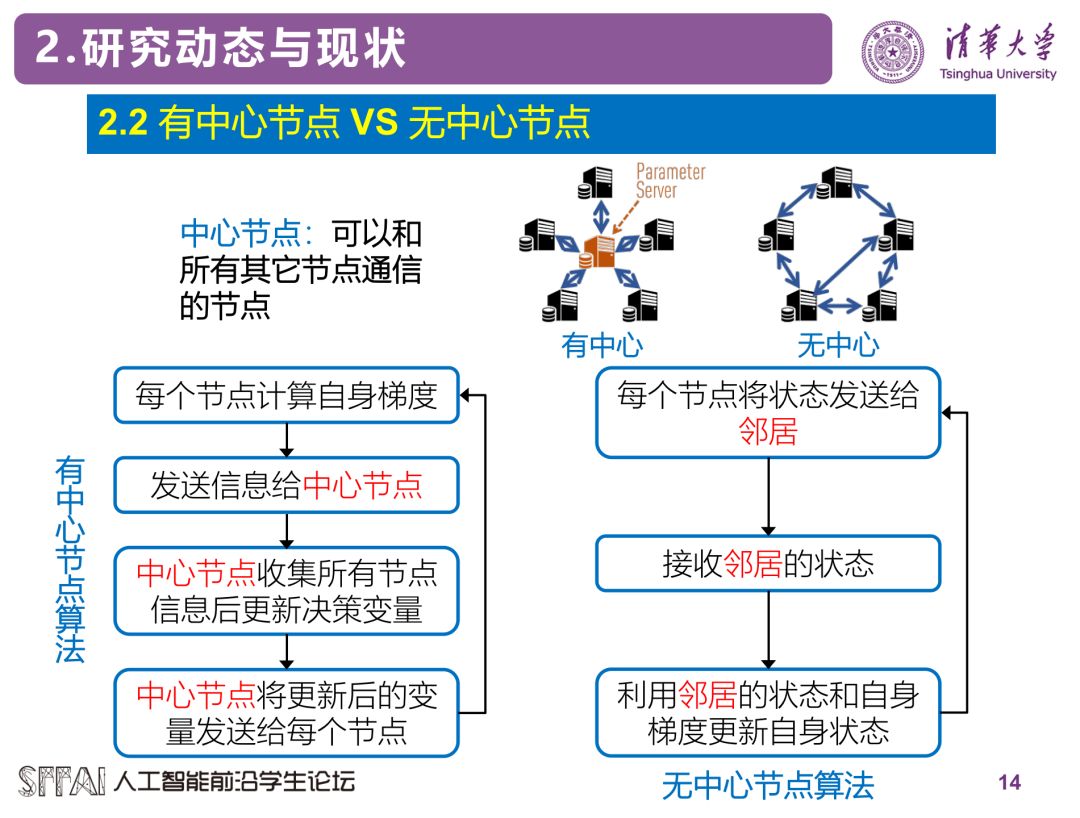
目前很多机器学习上采用的分布式优化方法,包括Tensorflow等框架,采用的都是有中心节点式的分布式算法。而目前无中心节点的算法受到了广泛的关注,它们的关系和区别如下图所示。

可以看出,无中心节点的算法更适用于大规模网络的计算,因此是目前的研究热点。目前比较著名的无中心节点算法有DGD[1], EXTRA[2], Push-DIGing[3], DEXTRA[4], AD-PSGD[5]等。下面介绍的所有方法都是指无中心节点式的算法。
此外,已有的算法大多数为同步更新式的算法,即所有节点需要同时开始一次迭代更新,导致计算快的节点需要等待计算慢的节点。为了解决这个问题,可以考虑采用异步更新式的算法。实际上,目前异步算法的设计和研究受到了广泛的关注。
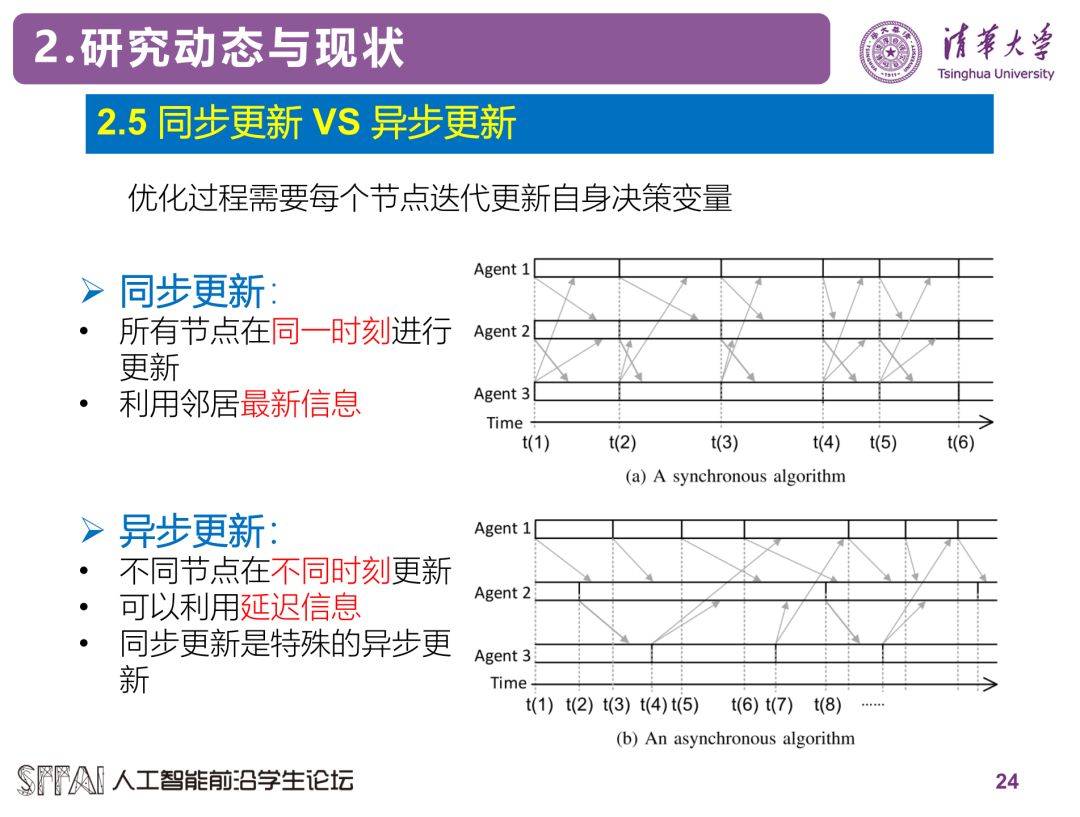

异步算法实施起来更为方便,且由于减少了节点的闲置时间,实际中收敛速度往往更快。但是,由于异步算法中节点更新节奏不一致,信息之前存在延迟,算法的收敛性往往很难分析。实际上,虽然在实际中经常直接异步式的应用同步算法,并且有时候能够有不错的效果,但是理论上这样的异步算法可能并不能收敛。我们最近提出了一种异步式的分布式算法——AsySPA [7],它具有理论上的收敛性,是一个完全异步实施的算法,并且理论上的收敛速度不会慢于相应的同步算法,感兴趣的同学可以参考文献[7]。

最后,算法的收敛速度始终是优化算法非常关心的一个问题,下图列出了目前最好的集中式优化算法和分布式优化算法的收敛速度比较。
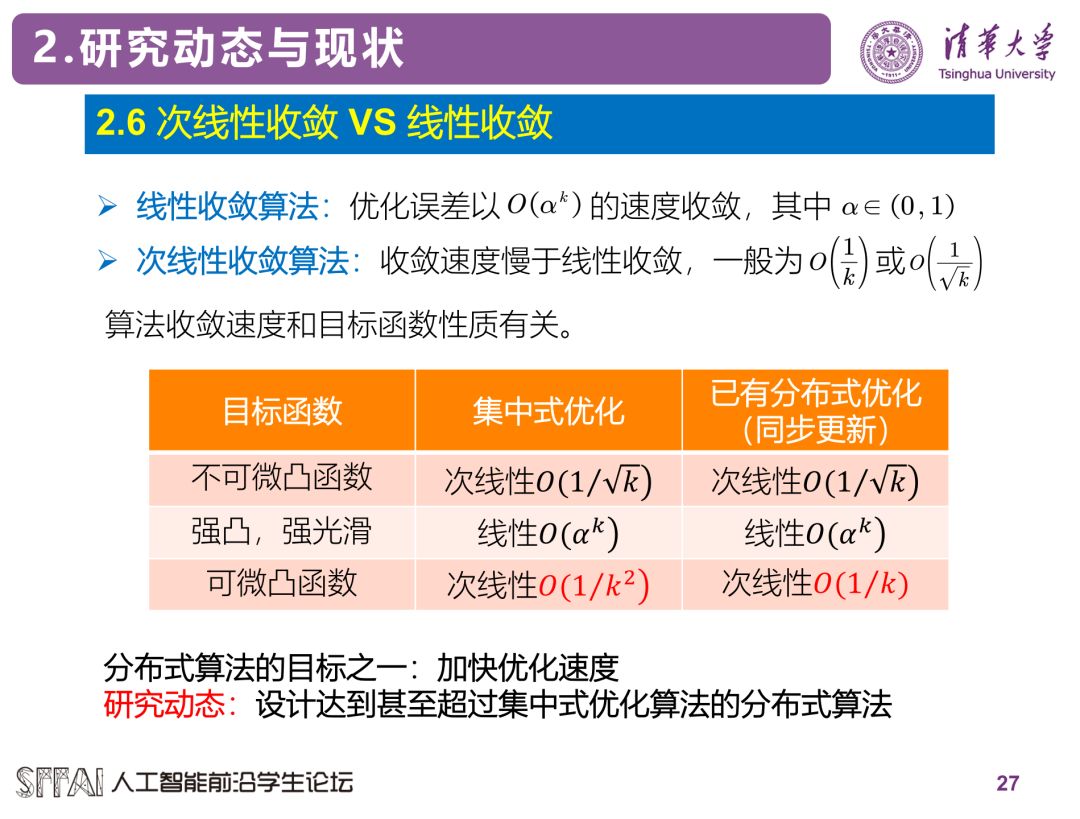
以上这些算法采用的都是目标函数或者局部目标函数的梯度信息。在机器学习中更常用的做法是采用随机梯度信息。一般来讲,随机梯度方法的收敛速度要慢于梯度下降法,因为传统随机梯度法往往需要采用衰减的步长,而梯度下降法在一定条件下可以采用常数步长。

目前也有一些利用Variance reduction机制的改进随机梯度法能在理论上达到线性的收敛速度,如SAG, SVRG [6], SAGA等。

如何将这些方法扩展成分布式算法也是目前的一个研究热点。
总结
分布式优化算法是目前的一个研究热点,且随着单硬件计算能力发展放缓,采用多硬件加速网络的训练会越来越成为以后的主流。在这种情况下,如何设计分布式的算法,保障其收敛性,加快其收敛速度,是一个值得研究的理论问题。本文介绍了目前分布式算法的一些基本概念和研究现状,以及我们提出的一种异步算法AsySPA。总之,分布式优化目前还有很多理论问题需要研究,并且如何跟具体的应用问题结合也是一个重点和难点。
参考文献
[1] A. Nedić and A. Ozdaglar, “Distributed subgradient methods for multi-agent optimization,” IEEE Trans. Autom.Control, vol. 54, no. 1, pp. 48–61, 2009.
[2] W. Shi, Q. Ling, G. Wu, and W.Yin, “Extra: An exact first-order algorithm for decentralized consensusoptimization,” SIAM J. Optim., vol. 25, no. 2, pp. 944– 966, 2015.
[3] A. Nedić, A. Olshevsky, and W. Shi, “Achieving geometric convergence for distributed optimizationover time-varying graphs,” SIAM J. Optim., vol. 27, no. 4, pp. 2597–2633, 2017.
[4] C. Xi and U. A. Khan, “DEXTRA:A fast algorithm for optimization over directed graphs,” IEEE Trans. Autom.Control, vol. 62, no. 10, pp. 4980–4993, 2017.
[5] X. Lian, W. Zhang, C. Zhang,and J. Liu, “Asynchronous Decentralized Parallel Stochastic Gradient Descent,”in Proceedings of the 35th Conference on Machine Learning, 2018, pp. 3049–3058.
[6] Johnson, Rie, and Tong Zhang."Accelerating stochastic gradient descent using predictive variancereduction." Advances in neural information processing systems. 2013.
[7] J. Zhang and K. You, “AsySPA:An Exact Asynchronous Algorithm for Convex Optimization Over Digraphs”. arXivpreprint arXiv:1808.04118, 2018.
SFFAI讲者招募
为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!
有意加入者请与我们联系:wangxl@mustedu.cn


历史文章推荐:


