机器学习(13)之最大熵模型详解
微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第二
【Python】:排名第三
【算法】:排名第四
前言
最大熵模型(maximum entropy model, MaxEnt)也是很典型的分类算法,和逻辑回归类似,都是属于对数线性分类模型。在损失函数优化的过程中,使用了和支持向量机类似的凸优化技术。理解了最大熵模型,对逻辑回归,支持向量机以及决策树算法都会加深理解。本文就对最大熵模型的原理做一个小结。
熵和条件熵
在(机器学习(9)之ID3算法详解及python实现)一文中,我们已经讲到了熵和条件熵的概念,这里我们对它们做一个简单的回顾。
熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:
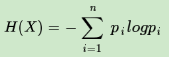
其中n代表X的n种不同的离散取值。而pi代表了X取值为i的概率,log为以2或者e为底的对数。
两个变量X和Y的联合熵表达式:
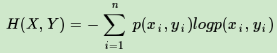
条件熵的表达式H(Y|X),类似于条件概率,它度量了我们的Y在知道X以后剩下的不确定性。表达式如下:
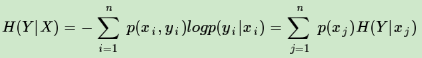
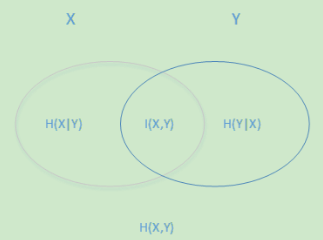
左边的椭圆代表H(X),右边的椭圆代表H(Y),中间重合的部分就是我们的互信息或者信息增益I(X,Y), 左边的椭圆去掉重合部分就是H(X|Y),右边的椭圆去掉重合部分就是H(Y|X)。两个椭圆的并就是H(X,Y)。
最大熵模型的定义
最大熵模型假设分类模型是一个条件概率分布P(Y|X), X为特征,Y为输出。给定一个训练集,(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m)),其中x为n维特征向量,y为类别输出。我们的目标就是用最大熵模型选择一个最好的分类类型。
在给定训练集的情况下,我们可以得到总体联合分布P(X,Y)的经验分布P¯(X,Y)和边缘分布P(X)的经验分布P¯(X)。P¯(X,Y)即为训练集中X,Y同时出现的次数除以样本总数m,P¯(X)即为训练集中X出现的次数除以样本总数m。
用特征函数f(x,y)描述输入x和输出y之间的关系。定义为:

特征函数f(x,y)关于经验分布P¯(X,Y)的期望值,用EP¯(f)表示为:
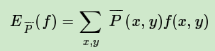
特征函数f(x,y)关于条件分布P(Y|X)和经验分布P¯(X)的期望值,用EP(f)表示为:
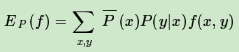
如果模型可以从训练集中学习,我们就可以假设这两个期望相等。即:
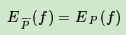
上式就是最大熵模型学习的约束条件,假如我们有M个特征函数fi(x,y)(i=1,2...,M)就有M个约束条件。可以理解为我们如果训练集里有m个样本,就有和这m个样本对应的M个约束条件。
假设满足所有约束条件的模型集合为:
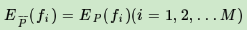
定义在条件概率分布P(Y|X)上的条件熵为:
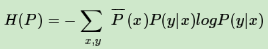
我们的目标是得到使H(P)最大的时候对应的P(y|x),这里可以对H(P)加了个负号求极小值,这样做的目的是为了使−H(P)为凸函数,方便使用凸优化的方法来求极值。
损失函数的优化
它的损失函数−H(P)定义为:
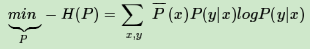
约束条件为:
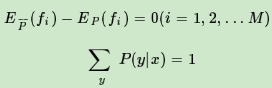
由于它是一个凸函数,同时对应的约束条件为仿射函数,根据凸优化理论,这个优化问题可以用拉格朗日函数将其转化为无约束优化函数,此时损失函数对应的拉格朗日函数L(P,w)定义为:
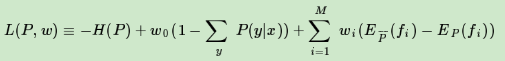
其中wi(i=1,2,...m)为拉格朗日乘子。由于原始问题满足凸优化理论中的KKT条件,因此原始问题的解和对偶问题的解是一致的。这样我们的损失函数的优化变成了拉格朗日对偶问题的优化。min L(P,w)是关于w的函数记为:
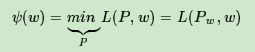
ψ(w)即为对偶函数,将其解记为:
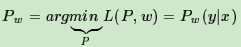
具体的是求L(P,w)关于P(y|x)的偏导数:
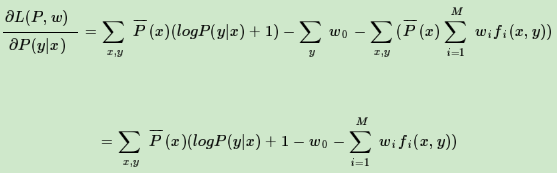
令偏导数为0,可以解出P(y|x)关于w的表达式如下:
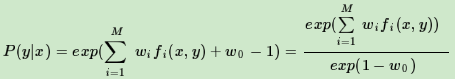
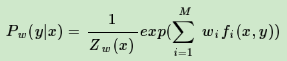
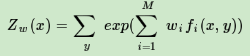
这样我们就得出了P(y|x)和w的关系,从而可以把对偶函数ψ(w)里面的所有的P(y|x)替换成用w表示,这样对偶函数ψ(w)就是全部用w表示了。接着我们对ψ(w)求极大化,就可以得到极大化时对应的w向量的取值,带入P(y|x)和w的关系式, 从而也可以得到P(y|x)的最终结果。
小结
最大熵模型在分类方法里算是比较优的模型,但是由于它的约束函数的数目一般来说会随着样本量的增大而增大,导致样本量很大的时候,对偶函数优化求解的迭代过程非常慢,scikit-learn甚至都没有最大熵模型对应的类库。但是理解它仍然很有意义,尤其是它和很多分类方法都有千丝万缕的联系。
优点
a) 最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型,作为经典的分类模型时准确率较高。
b) 可以灵活地设置约束条件,通过约束条件的多少可以调节模型对未知数据的适应度和对已知数据的拟合程度
缺点
a) 由于约束函数数量和样本数目有关系,导致迭代过程计算量巨大,实际应用比较难。
参考:
1. 周志华《机器学习》
2. 博客园:作者(刘建平)http://www.cnblogs.com/pinard/p/6093948.html
3. 李航 《统计学习方法》



加我微信:guodongwe1991,备注姓名-单位-研究方向(加入微信机器学习交流1群)
招募 志愿者
广告、商业合作
请加QQ:357062955@qq.com

喜欢,别忘关注~
帮助你在AI领域更好的发展,期待与你相遇!





