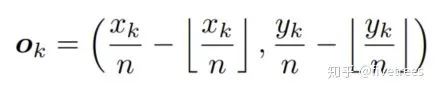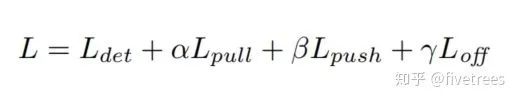来源 | https://zhuanlan.zhihu.com/p/76477248
【导读】目标检测包括目标分类和目标定位 2 个任务,目标定位一般是用一个矩形的边界框来框出物体所在的位置,关于边界框的回归策略,不同算法其回归方法不一。本文主要讲述:1.无 Anchor 的目标检测算法:YOLOv1,CenterNet,CornerNet 的边框回归策略;2.有 Anchor 的目标检测算法:SSD,YOLOv2,Faster R-CNN 的边框回归策略。
无Anchor的目标检测算法边框回归策略
1. YOLOv1
原文链接:
https://pjreddie.com/media/files/papers/yolo.pdf,
解读链接:
https://zhuanlan.zhihu.com/p/75106112
YOLOv1 先将每幅图片 reshape 到 448x448 大小,然后将图片分成 7x7 个单元格,每个格子预测 2 个边界框,而每个边界框的位置坐标有 4 个,分别是 x,y,w,h。
其中 x,y 是边界框相对于其所在单元格的偏移(一般是相对于单元格左上角坐标点的偏移,在这里每个正方形单元格的边长视为 1,故 x,y在 [0,1] 之间);w,h 分别是预测的边界框宽,高相对于整张图片宽,高的比例,也是在 [0,1] 之间。YOLOv1 中回归选用的损失函数是均方差损失函数,
因此我们训练时,有了预测的边界框位置信息,有了gtbbox,有了损失函数就能按照梯度下降法,优化我们网络的参数,使网络预测的边界框更接近与gt_bbox。
![]()
2. CornerNet
原文链接:
https://arxiv.org/pdf/1808.01244.pdf
代码链接:
https://github.com/princeton-vl/CornerNet
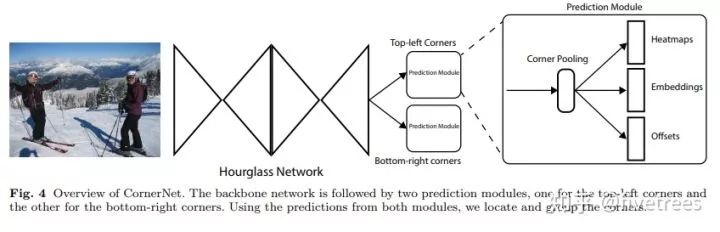
这是在 ECCV2018 发表的一篇文章,文章将目标检测问题当作关键点检测问题来解决,具体来说就是通过检测目标框的左上角和右下角两个关键点得到预测框,因此 CornerNet 算法中也没有 anchor 的概念,在目标检测领域 Anchor 大行其道的时候,这种无 Anchor 的做法在目标检测领域是比较创新的而且取得的效果还很不错。此外,整个检测网络的训练是从头开始的,并没有基于预训练的分类模型,这使得用户能够自由设计特征提取网络,不用受预训练模型的限制。
![]() 首先原图经过 1 个 7×7 的卷积层将输入图像尺寸缩小为原来的 1/4 (论文中输入图像大小是 511×511,缩小后得到 128×128 大小的输出),然后经过特征提取网络 Hourglass network 提取特征,Hourglass module 后会有两个输出分支模块,分别表示左上角点预测分支和右下角点预测分支,每个分支模块经过应该 Corner pooling 层后输出3个信息:
Heatmaps、 Embeddings 和 Offsets。
首先原图经过 1 个 7×7 的卷积层将输入图像尺寸缩小为原来的 1/4 (论文中输入图像大小是 511×511,缩小后得到 128×128 大小的输出),然后经过特征提取网络 Hourglass network 提取特征,Hourglass module 后会有两个输出分支模块,分别表示左上角点预测分支和右下角点预测分支,每个分支模块经过应该 Corner pooling 层后输出3个信息:
Heatmaps、 Embeddings 和 Offsets。
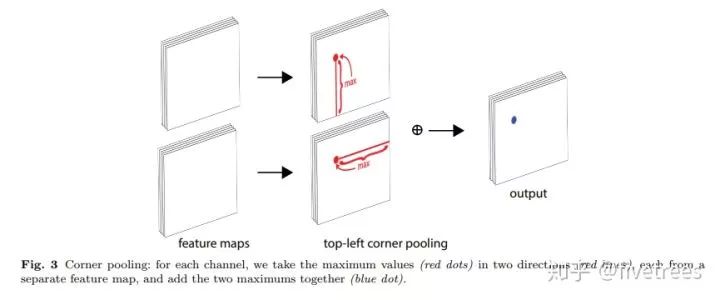
1. Corner pooling:更好的定位角点,一个角点的定位不能只依靠局部信息,Corner pooling 层有两组特征图,相同的像素点,汇集值一个是该像素水平向右的最大值,一个是垂直向下的最大值,之后两组特征图求和;
2. Heatmaps:预测角点位置信息,一个支路预测左上角,一个支路预测右下角。Heatmaps 可以用维度为 CxHxW 的特征图表示,其中 C 表示目标的类别(不包含背景类),这个特征图的每个通道都是一个 mask,mask 的每个值是 0 到 1 ,表示该点是角点的分数(注意一个通道只预测同一类别的物体的角点信息);
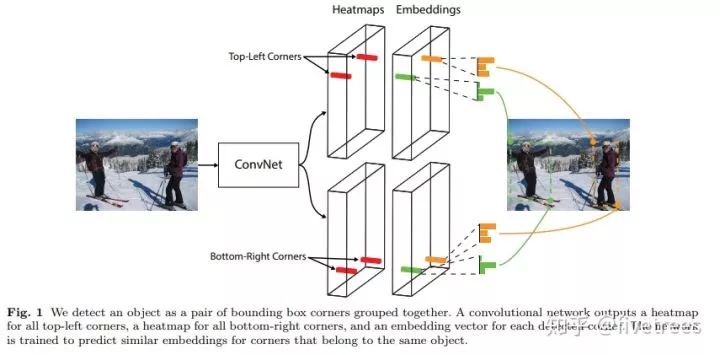
3. Embeddings:用来对预测的角点分组,也就是找到属于同一个目标的左上角角点和右下角角点,同一个预测框的一对角点的角距离短。如下图:
![]()
4. Offsets:调整角点位置,使得获得的边界框更紧密。
![]() 可以看出有了Corner pooling,预测的目标边界框的角点,位置信息更加的精确了。
可以看出有了Corner pooling,预测的目标边界框的角点,位置信息更加的精确了。
![]() 如上图所示,通常一个目标的边界框的角点是不包含该目标的局部特征信息的,那么我们如何判断某一个位置的像素点是否是某一个目标的角点呢?拿左上角点来说,对于左上角点的上边界,我们需要从左往右看寻找目标的特征信息,对于左上角点的左边界,我们需要从上往下看寻找目标的特征信息(比如上图中的第一张图,左上角点的右边有目标顶端的特征信息:第一张图的头顶,左上角点的下边有目标左侧的特征信息:第一张图的手,因此如果左上角点经过池化操作后能有这两个信息,那么就有利于该点的预测,这就是Corner pooling的主要思想)。
如上图所示,通常一个目标的边界框的角点是不包含该目标的局部特征信息的,那么我们如何判断某一个位置的像素点是否是某一个目标的角点呢?拿左上角点来说,对于左上角点的上边界,我们需要从左往右看寻找目标的特征信息,对于左上角点的左边界,我们需要从上往下看寻找目标的特征信息(比如上图中的第一张图,左上角点的右边有目标顶端的特征信息:第一张图的头顶,左上角点的下边有目标左侧的特征信息:第一张图的手,因此如果左上角点经过池化操作后能有这两个信息,那么就有利于该点的预测,这就是Corner pooling的主要思想)。
![]()
![]() 如 Figure3 所示,Corner pooling 层有 2 个输入特征图,特征图的宽高分别用 W 和 H 表示,假设接下来要对图中红色点(坐标假设是(i,j))做 corner pooling,那么首先找到像素点以下(包括本身)即 (i,j) 到 (i,H)(左角点的最下端)这一列中的最大值,然后将这张特征图中 (i,j) 位置的特征值用这个最大值替代,类似于找到 Figure2 中第一张图的左侧手信息;
然后找到 (i,j) 到 (W,j)(左角点的最右端)的最大值,然后将这张特征图中 (i,j) 位置的特征值用这个最大值替代,类似于找到 Figure2 中第一张图的头顶信息,然后将这 2 个特征图中的 (i,j) 位置的特征值相加,也就是将找到的这两个最大值相加得到 (i,j) 点的值
(对应 Figure3 最后一个图的蓝色点)。
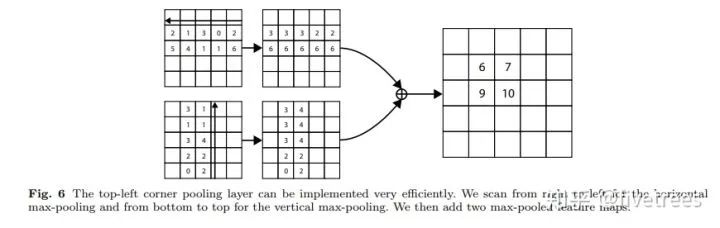
对于右下角点的 Corner pooling 操作类似,只不过找最大值变成从 (i,j) 到 (0,j) 和从 (i,j) 到 (i,0) 中找。比如 Figure6 中,第一张特征图,比如第 2 行的第 1 个点(值为2),其右边同一行的最大值是 3 ,故经过 Corener Pooling 后,其值变为3,其他同理;第 2 张特征图,第 2 列的第一个点为 3,其下面所在列的最大值(包括本身)也是 3,因此经过 Corener pooling 之后,其中也变为 3,最后将 2 张特征图对应位置的点的特征值相加,得到一张特征图。
如 Figure3 所示,Corner pooling 层有 2 个输入特征图,特征图的宽高分别用 W 和 H 表示,假设接下来要对图中红色点(坐标假设是(i,j))做 corner pooling,那么首先找到像素点以下(包括本身)即 (i,j) 到 (i,H)(左角点的最下端)这一列中的最大值,然后将这张特征图中 (i,j) 位置的特征值用这个最大值替代,类似于找到 Figure2 中第一张图的左侧手信息;
然后找到 (i,j) 到 (W,j)(左角点的最右端)的最大值,然后将这张特征图中 (i,j) 位置的特征值用这个最大值替代,类似于找到 Figure2 中第一张图的头顶信息,然后将这 2 个特征图中的 (i,j) 位置的特征值相加,也就是将找到的这两个最大值相加得到 (i,j) 点的值
(对应 Figure3 最后一个图的蓝色点)。
对于右下角点的 Corner pooling 操作类似,只不过找最大值变成从 (i,j) 到 (0,j) 和从 (i,j) 到 (i,0) 中找。比如 Figure6 中,第一张特征图,比如第 2 行的第 1 个点(值为2),其右边同一行的最大值是 3 ,故经过 Corener Pooling 后,其值变为3,其他同理;第 2 张特征图,第 2 列的第一个点为 3,其下面所在列的最大值(包括本身)也是 3,因此经过 Corener pooling 之后,其中也变为 3,最后将 2 张特征图对应位置的点的特征值相加,得到一张特征图。
CornerNet 的第一个输出是 headmaps,网络一共输出 2 组 Heatmap,一组预测左上角点,一组预测右下角点。每组 Heatmap 有 C 个通道,代表 C 类。每个角点,只要 ground truth处的点为postive,其余位置为negative,因为在 ground-truth 附近的负样本也可以得到 overlap 较大的box ,满足要求。因此,不同负样本的点的损失函数权重不是相等的,而是在以 ground-truth 为中心圆内呈非归一化高斯分布,圆半径以在圆内的点形成的 box 与 ground-truth 的 IoU 不小于 t(t=0.7) 为标准,如下图所示:
![]()
![]() 上图是针对角点预测(headmaps)的损失函数,整体上是改良版的 Focal loss 。几个参数的含义:
N 为整张图片中目标的数量,
上图是针对角点预测(headmaps)的损失函数,整体上是改良版的 Focal loss 。几个参数的含义:
N 为整张图片中目标的数量,![]() 为控制每个点的权重的超参数,具体来说,α 参数用来控制难易分类样本的损失权重(在文章中
为控制每个点的权重的超参数,具体来说,α 参数用来控制难易分类样本的损失权重(在文章中![]() 为 2,
为 2, ![]() 为 4),pcij 表示预测的 heatmaps 在第 c 个通道(类别 c )的 (i,j) 位置的值,ycij 表示对应位置的 ground truth,ycij=1 时候的损失函数就是 focal loss;ycij 等于其他值时表示 (i,j) 点不是类别 c 的目标角点,照理说此时 ycij 应该是 0(大部分算法都是这样处理的),但是这里 ycij 不是0,而是用基于 ground truth 角点的高斯分布计算得到,因此距离 ground truth 比较近的 (i,j) 点的 ycij 值接近 1,这部分通过 β 参数控制权重,这是和Focal loss 的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近 ground truth 的误检角点组成的预测框仍会和 ground truth 有较大的重叠面积。
为 4),pcij 表示预测的 heatmaps 在第 c 个通道(类别 c )的 (i,j) 位置的值,ycij 表示对应位置的 ground truth,ycij=1 时候的损失函数就是 focal loss;ycij 等于其他值时表示 (i,j) 点不是类别 c 的目标角点,照理说此时 ycij 应该是 0(大部分算法都是这样处理的),但是这里 ycij 不是0,而是用基于 ground truth 角点的高斯分布计算得到,因此距离 ground truth 比较近的 (i,j) 点的 ycij 值接近 1,这部分通过 β 参数控制权重,这是和Focal loss 的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近 ground truth 的误检角点组成的预测框仍会和 ground truth 有较大的重叠面积。
从 heatmap 层回到 input image 会有精度损失(不一定整除存在取整),对小目标影响大,因此预测 location offset ,调整 corner 位置。
损失函数如下:
![]()
![]() Xk,Yk 是角点的坐标,n 为下采样的倍数,公式中符合为向下取整。
O^k 代表 Offsets 的 predicted offset;Ok 代表 gt 的 offset。
负责检测哪个 top-left corner 和哪个 bottom-right corner 是一对,组成一个 box,同一个 box 的 corner 距离短。top-left 和 bottom-right corner 各预测一个 embedding vector,距离小的 corner 构成一个 box
(一个图多个目标,多对点,因此确定 group 是必要的)embedding 这部分的训练是通过两个损失函数实现的,如下图:
Xk,Yk 是角点的坐标,n 为下采样的倍数,公式中符合为向下取整。
O^k 代表 Offsets 的 predicted offset;Ok 代表 gt 的 offset。
负责检测哪个 top-left corner 和哪个 bottom-right corner 是一对,组成一个 box,同一个 box 的 corner 距离短。top-left 和 bottom-right corner 各预测一个 embedding vector,距离小的 corner 构成一个 box
(一个图多个目标,多对点,因此确定 group 是必要的)embedding 这部分的训练是通过两个损失函数实现的,如下图:
![]() etk 表示第 k 个目标的左上角角点的 embedding vector,ebk 表示第 k 个目标的右下角角点的 embedding vector,ek 表示 etk 和 ebk 的均值。
公式 4 用来缩小属于同一个目标(第 k 个目标)的两个角点的 embedding vector( etk 和 ebk )距离。公式 5 用来扩大不属于同一个目标的两个角点的 embedding vector 距离。
Pull loss 越小,则同一 object 的左上角和右下角的 embedding 得分距离越小;Push loss 越小,则不同 object 的左上角和右下角的 embedding 得分距离越大。
etk 表示第 k 个目标的左上角角点的 embedding vector,ebk 表示第 k 个目标的右下角角点的 embedding vector,ek 表示 etk 和 ebk 的均值。
公式 4 用来缩小属于同一个目标(第 k 个目标)的两个角点的 embedding vector( etk 和 ebk )距离。公式 5 用来扩大不属于同一个目标的两个角点的 embedding vector 距离。
Pull loss 越小,则同一 object 的左上角和右下角的 embedding 得分距离越小;Push loss 越小,则不同 object 的左上角和右下角的 embedding 得分距离越大。
![]() 其中,α, β, γ 是超参数,分别取 0.1, 0.1, 1。
说了那么多,CornerNet 主要是通过预测目标的左上角点和右下角点,来完全目标的边界框预测。Corner pooling 负责更好的找到角点位置,headmaps输出角点位置信息,Embeddings 负责找到同一个目标的一组角点,Offsets 用于对角点微调,使预测框更加精准。
CornerNet 通过检测物体的左上角点和右下角点来确定目标,但在确定目标的过程中,无法有效利用物体的内部的特征,即无法感知物体内部的信息,因为在判断两个角点是否属于同一物体时,缺乏全局信息的辅助,因此很容易把原本不是同一物体的两个角点看成是一对角点,因此产生了很多错误目标框,另外,角点的特征对边缘比较敏感,这导致很多角点同样对背景的边缘很敏感,因此在背景处也检测到了错误的角点从而导致该类方法产生了很多误检 (错误目标框)。
其实不光是基于关键点的 one-stage 方法无法感知物体内部信息,几乎所有的 one-stage 方法都存在这一问题。
与下面介绍的CenterNet同名的还有一篇文章,文章主要基于CorenNet出现的误检问题,作了改进,文章除了预测左上角点和右下角点外,还额外预测了目标的中心点,用三个关键点而不是两个点来确定一个目标,
使网络花费了很小的代价便具备了感知物体内部信息的能力,从而能有效抑制误检。大家可以参考以下资料:
https://arxiv.org/pdf/1904.08189.pdf
https://zhuanlan.zhihu.com/p/62789701
https://github.com/Duankaiwen/CenterNet
其中,α, β, γ 是超参数,分别取 0.1, 0.1, 1。
说了那么多,CornerNet 主要是通过预测目标的左上角点和右下角点,来完全目标的边界框预测。Corner pooling 负责更好的找到角点位置,headmaps输出角点位置信息,Embeddings 负责找到同一个目标的一组角点,Offsets 用于对角点微调,使预测框更加精准。
CornerNet 通过检测物体的左上角点和右下角点来确定目标,但在确定目标的过程中,无法有效利用物体的内部的特征,即无法感知物体内部的信息,因为在判断两个角点是否属于同一物体时,缺乏全局信息的辅助,因此很容易把原本不是同一物体的两个角点看成是一对角点,因此产生了很多错误目标框,另外,角点的特征对边缘比较敏感,这导致很多角点同样对背景的边缘很敏感,因此在背景处也检测到了错误的角点从而导致该类方法产生了很多误检 (错误目标框)。
其实不光是基于关键点的 one-stage 方法无法感知物体内部信息,几乎所有的 one-stage 方法都存在这一问题。
与下面介绍的CenterNet同名的还有一篇文章,文章主要基于CorenNet出现的误检问题,作了改进,文章除了预测左上角点和右下角点外,还额外预测了目标的中心点,用三个关键点而不是两个点来确定一个目标,
使网络花费了很小的代价便具备了感知物体内部信息的能力,从而能有效抑制误检。大家可以参考以下资料:
https://arxiv.org/pdf/1904.08189.pdf
https://zhuanlan.zhihu.com/p/62789701
https://github.com/Duankaiwen/CenterNet
3. CenterNet
论文链接:
https://arxiv.org/pdf/1904.07850.pdf
代码链接:
https://github.com/xingyizhou/CenterNet
这里区别一下呀,今年好像有 2 篇称 CenterNet 的论文,我要介绍的这篇名为“Objects as Points”
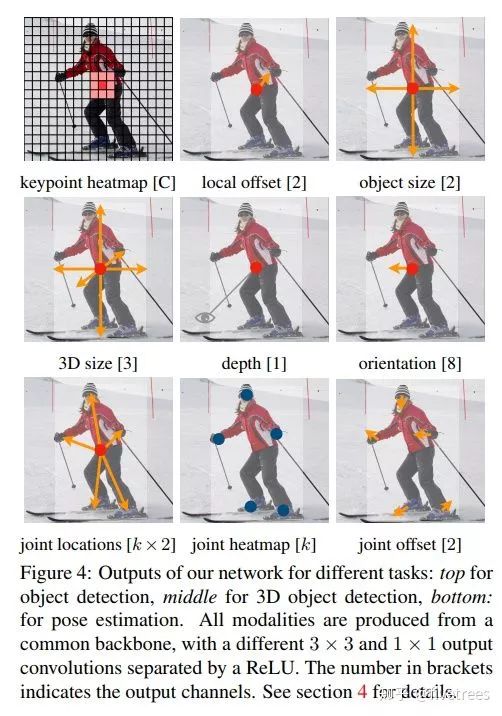
,另外一篇就是上面提到的中科院牛津华为诺亚提出的,名为“CenterNet: Keypoint Triplets for Object Detection”是基于CornerNet 作的改进。这篇 CenterNet 算法也是 anchor-free 类型的目标检测算法,基于点的思想和 CornerNet 是相似的,方法上做了较大的调整,与 Corenet 不同的是,CenterNet 预测的是目标的中心点,然后再预测目标框的宽和高,来生成预测框。此外此网络还能作 3D 目标检测和人体姿态估计。
![]()
1. CenterNet,
从算法名也可以看出这个算法要预测的是目标的中心点,而不再是 CornerNet 中的 2 个角点;
相同点是都采用热力图(heatmap)来实现,都引入了预测点的高斯分布区域计算真实预测值,同时损失函数一样(修改版 Focal loss,网络输出的热力图也将先经过 sigmod 函数归一化成 0 到 1 后再传给损失函数)。
另外 CenterNet 也不包含 corner pooling 等操作,因为一般目标框的中心点落在目标上的概率还是比较大的,因此常规的池化操作能够提取到有效的特征,这是其一。
2.
CerterNet 中也采用了和 CornerNet 一样的偏置(offset)预测,这个偏置表示的是标注信息从输入图像映射到输出特征图时由于取整操作带来的坐标误差,只不过 CornerNet 中计算的是 2 个角点的 offset,而 CenterNet计算的是中心点的 offset 。
这部分还有一个不同点:
损失函数,在CornerNet 中采用 SmoothL1 损失函数来监督回归值的计算,但是在CenterNet 中发现用 L1 损失函数的效果要更好,差异这么大是有点意外的,这是其二。
3、
CenterNet 直接回归目标框尺寸,最后基于目标框尺寸和目标框的中心点位置就能得到预测框,这部分和 CornerNet 是不一样的,因为 CornerNet 是预测 2 个角点,所以需要判断哪些角点是属于同一个目标的过程,在CornerNet 中通过增加一个 corner group 任务预测 embedding vector,最后基于 embedding vector 判断哪些角点是属于同一个框。
而 CenterNet 是预测目标的中心点,所以将 CornerNet 中的 corner group 操作替换成预测目标框的 size(宽和高),这样一来结合中心点位置就能确定目标框的位置和大小了,这部分的损失函数依然采用 L1 损失,这是其三。
CenterNet 对目标框的回归策略,采用先预测目标的中心点位置,然后再预测目标框的宽和高来达到目标检测。预测中心点的偏移采用修改版的 Focal loss,对于热力图中中心点到原图映射的偏差,采样 L1 损失函数,对于目标框宽和高的预测也是采用 L1 损失函数。
有 Anchor 的目标检测算法边框回归策略
1. Faster R-CNN
关于论文和解读,网上有很多大佬讲的很好(https://zhuanlan.zhihu.com/p/31426458),这里其他方面我就不说了,主要谈一下,Faster R-CNN 的回归策略。
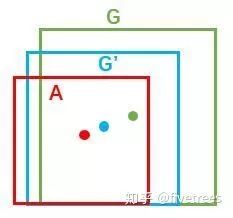
![]()
![]()
X 为预测框的中心点坐标,Xa 为 Anchor 的中心点坐标,X 为 gt_bbox 的中心点坐标( y,w,h 同理),目标是使变换因子 tx 跟 tx* 差距最小,损失函数为 Smooth L1 损失函数。
2. YOLOv2
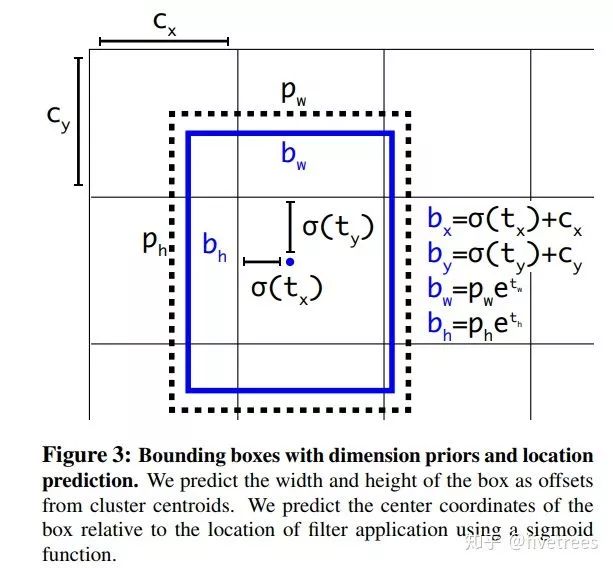
YOLOv2 中作者引入了 Faster R-CNN 中类似的 anchor,但是回归策略不同,对 bbox 中心坐标的预测不是基于 anchor 坐标的偏移量得到的,而是采用了 v1 中预测 anchor 中心点相对于对于单元格左上角位置的偏移,如下图
![]() 上图中 tx,ty,tw,th 为坐标变换系数,Cx,Cy 为 Anchor 中心的坐标,Pw,Ph 为 Anchor 的宽和高,tx 和 tw 是 Anchor 中心点相对于其所在单元格左上角点坐标的偏移,在这里作者说之所以没有采样 Faster R-CNN 中的回归策略是因为 Faster R-CNN 对于预测框中心点的回归太不稳定了,而YOLOv2 将中心点能够固定在单元格范围之内。损失函数采样的是 MSE 均方差损失函数,回归损失函数输入的参数分别是 Anchor 到预测框的坐标变换系数和 Anchor 到 gt_bbox 的坐标变换系数。
上图中 tx,ty,tw,th 为坐标变换系数,Cx,Cy 为 Anchor 中心的坐标,Pw,Ph 为 Anchor 的宽和高,tx 和 tw 是 Anchor 中心点相对于其所在单元格左上角点坐标的偏移,在这里作者说之所以没有采样 Faster R-CNN 中的回归策略是因为 Faster R-CNN 对于预测框中心点的回归太不稳定了,而YOLOv2 将中心点能够固定在单元格范围之内。损失函数采样的是 MSE 均方差损失函数,回归损失函数输入的参数分别是 Anchor 到预测框的坐标变换系数和 Anchor 到 gt_bbox 的坐标变换系数。
3. SSD
论文链接:
https://arxiv.org/pdf/1512.02325.pdf
![]()
回归策略基本和 Faster R-CNN 中一致,对边界框的回归的损失函数也是采样的 Smooth L1 损失函数,不过这里的先验框名字叫 Default Box 和 Faster R-CNN 中的 Anchor 叫法不一样。
参考文献
https://arxiv.org/pdf/1512.02325.pdf
https://arxiv.org/pdf/1808.01244.pdf
https://arxiv.org/pdf/1506.01497.pdf
https://blog.csdn.net/u014380165/article/details/92801206
https://blog.csdn.net/u014380165/article/details/83032273
https://zhuanlan.zhihu.com/p/62789701
(*本文为AI科技大本营转载文章,转载请联系作者)
距离大会参与通道关闭还有 1 天,扫描下方二维码或点击阅读原文,马上参与!(学生票特享 598 元,团购票每人立减优惠,倒计时 1 天!)
推荐阅读





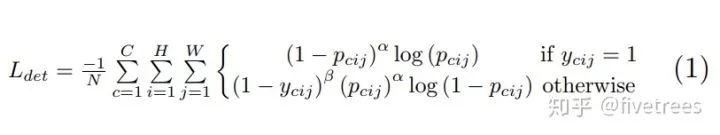
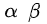 为控制每个点的权重的超参数,具体来说,α 参数用来控制难易分类样本的损失权重(在文章中
为控制每个点的权重的超参数,具体来说,α 参数用来控制难易分类样本的损失权重(在文章中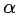 为 2,
为 2, 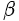 为 4),pcij 表示预测的 heatmaps 在第 c 个通道(类别 c )的 (i,j) 位置的值,ycij 表示对应位置的 ground truth,ycij=1 时候的损失函数就是 focal loss;ycij 等于其他值时表示 (i,j) 点不是类别 c 的目标角点,照理说此时 ycij 应该是 0(大部分算法都是这样处理的),但是这里 ycij 不是0,而是用基于 ground truth 角点的高斯分布计算得到,因此距离 ground truth 比较近的 (i,j) 点的 ycij 值接近 1,这部分通过 β 参数控制权重,这是和Focal loss 的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近 ground truth 的误检角点组成的预测框仍会和 ground truth 有较大的重叠面积。
为 4),pcij 表示预测的 heatmaps 在第 c 个通道(类别 c )的 (i,j) 位置的值,ycij 表示对应位置的 ground truth,ycij=1 时候的损失函数就是 focal loss;ycij 等于其他值时表示 (i,j) 点不是类别 c 的目标角点,照理说此时 ycij 应该是 0(大部分算法都是这样处理的),但是这里 ycij 不是0,而是用基于 ground truth 角点的高斯分布计算得到,因此距离 ground truth 比较近的 (i,j) 点的 ycij 值接近 1,这部分通过 β 参数控制权重,这是和Focal loss 的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近 ground truth 的误检角点组成的预测框仍会和 ground truth 有较大的重叠面积。