CenterNet:目标即点(代码已开源)
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
TeddyZhang:上海大学研究生在读,研究方向是图像分类、目标检测以及人脸检测与识别
近些天,目标检测领域掀起了一股Anchor-Free的潮流,即不去生成预选框,也不用额外耗费资源去计算预选框和真实框的IOU。在此之前很多成功的检测器会产生一系列位置坐标,然后用于坐标回归和分类预测,而这篇文章很有意思,将目标当做一个独立的点(也就是目标边框的中心点)。

论文地址:https://arxiv.org/pdf/1904.07850.pdf
算法总览
本篇文章的核心就是使用关键点检测的方法去预测目标边框的中心点,然后回归出目标的其他属性,例如大小、3D 位置、方向甚至是其姿态。而且这个方向相比之前的目标检测器,实现起来更加简单,推理速度更快,精度更高!在COCO数据集上达到了最好的speed-accuracy的trade-off。
提起速度和精度的trade-off,大家可能都会想起来YOLO-V3,这个算法在笔者心中也是很高的地位,也是做一些目标检测工程项目首先考虑的一个算法,那么本篇论文提出的算法与其比较如何呢?相信大家看完,就更加有兴趣来阅读了,并且本篇文章作者Xingyi Zhou也是另一篇ExtremeNet的第一作者,代码均已开源!
开源地址:
https://github.com/xingyizhou/CenterNet
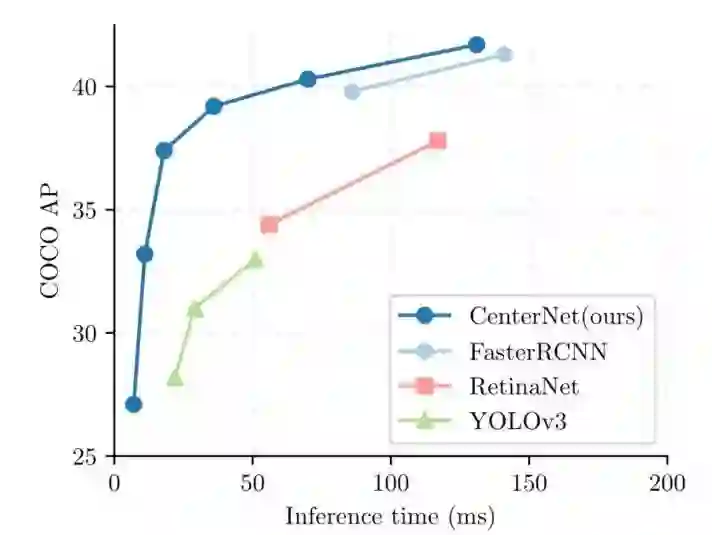
COCO验证集结果
作者认为如果把每个目标都使用一个关键点进行表达,那么目标检测问题其实质就是一个关键点检测的问题,假设我们简单的把一幅图片喂到一个全卷积网络中,那么就会产生一个热图,而热图上的点和目标的边框有关,接着在这个点对应的图像特征去直接预测边框的长和宽,那么我们就可以简化这个检测问题。并且在测试时候,由于每个目标只有一个点,那么就不会存在多个预测框相互重叠的情况,也就没有必要使用NMS算法来去重!

除此之外,这个思路可以很好的扩展到其他任务,如3D目标检测和姿态估计的问题,是不是听起来耳目一新?这个就可以更好的扩展这个算法到不同的任务中,其方法就是在每个预测点要回归出目标的其他属性,例如目标检测需要回归边框的长和宽,3D目标检测就需要回归更多的参量,如目标深度,3D边框维度和目标方向。而对于姿态估计,我们将每个关节点相对于中心点的偏移作为回归目标,直接回归。非常Nice and Simple的思路!
其算法不仅思路简单,而且具有很高的速度和精度,当使用简单的ResNet18和反卷积,其可以跑出142FPS,COCO准确率为28.1%,如果使用精心设计的姿态估计网络DLA-34,那么可以达到37.4%的准确率,速度为52FPS,最后作者还使用了SOTA的关键点检测的网络Hourglass-104,可以达到45.1%的COCO AP。真的很强大,同一算法可以在不同应用目的下进行适当改变,这不是我们一直在追求的么?
与Anchor-based的区别
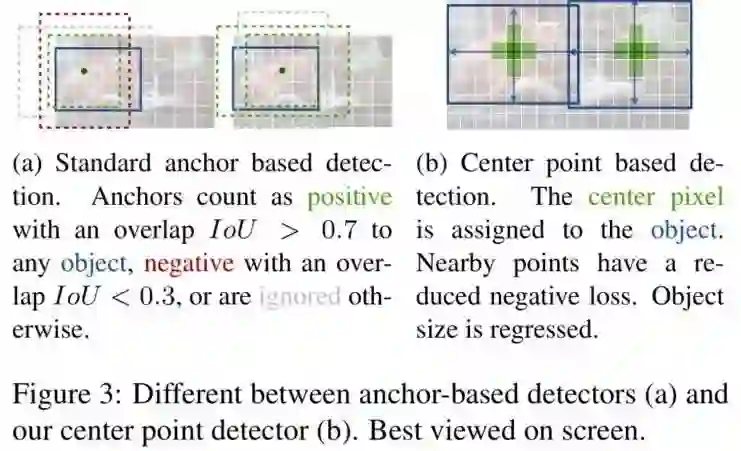
Anchor-based的很经典的代表Faster-RCNN,它在一个低分辨率的网格中采样一系列固定尺度的anchors,并分为前景和背景,标准是anchor和真实框的IOU,如果大于0.7,那么为正样本,如果小于0.3为负样本,其他的则忽略。而本文提出的CenterNet比较接近之前的单阶段Anchor-based的网络,但是有些是不一样的,首先,CneterNet中的“anchor”是以确定坐标为基础的,而不是边框重叠,对于前景和背景并没有对应的阈值设定。然后,对于每一个目标只有一个正样本“anchor”,因此测试时不需要NMS算法。最后,CenterNet使用了更大的输入分辨率(stride为4),而传统的检测器一般stride为16。但由于不用计算IOU,所以就算使用了很大的分辨率,速度仍然是很快的!
Preliminary
首先我们输入一幅图像I,经过全卷积网络产生关键点热图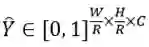
在训练时遵循关键点检测的一些策略,首先计算低分辨率特征图 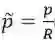
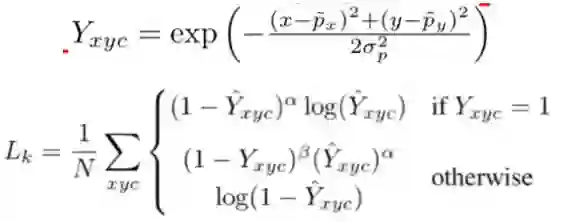
其中和为focal loss的超参数,N为所有正样本实例的个数,从而将loss归一化。根据前人经验focal loss的超参数分别设置为2和4.
为了消除因stride=4而产生的位置偏差,我们附加的会预测一个偏移量 
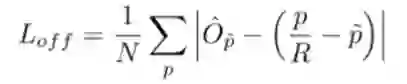
Objects as Points
在这里我们主要讲解如何将点预测扩展到目标检测中的边框预测,在论文中作者还详细讲解了怎么将这个思路扩展到3D目标检测和姿态估计中,其原理都是类似的!
首先我们定义 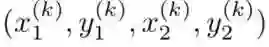
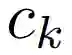
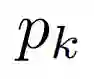

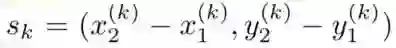
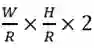
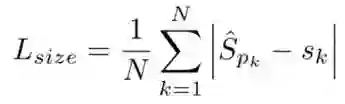
那么总的损失函数我们就得到了,一共是三个损失函数的结合:
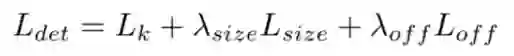
其中 
在测试阶段,我们首先提取出来每个类别在热图中的点,在8邻域中检测所有的响应并保存前100个点,然后每个关键点位置通过高斯函数可以计算出Y值用来度量这个点的置信度。然后通过下面变换公式产生边框坐标:
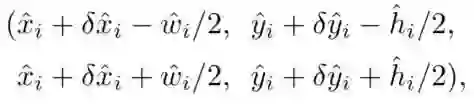
其中为其回归预测,并且不需要进行NMS或者其他的post-processing策略,其中8邻域检测最大值可以高效的使用3x3max pooling来代替。
根据这个思路,作者还将这个算法扩展到其他任务中,只需要更改或添加回归目标即可!如下图所示:
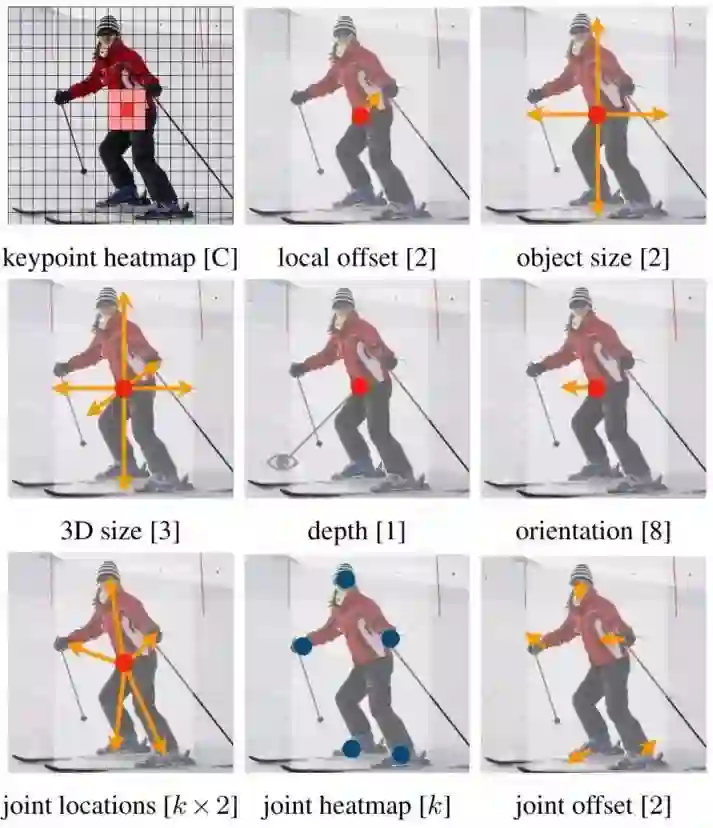
可以看到第一行就是刚才讲的三个损失函数,包括分类损失,偏差损失和size损失。而第二行为3D目标检测中的一些回归目标,第三行为姿态估计的一些回归目标!思路都大致相同,就不再一一赘述了!
实验结果
作者试验了4中网络框架,分别为ResNet-18,ResNet-101,DLA-34和Hourglass-104。并且在实验中分为了没有使用test augmentation,翻转操作,多尺度增强三种测试方案,用于检测模型的稳定性和泛化能力!

可以看到,不同网络提取特征能力不同,对检测精度的结果也是有很大的影响的。但这些结果也充分可能了这种策略的成功,在实际工程中,我们可以使用不同的网络来进行检测,从而满足我们的需求,有些场合,我们不需要精度太高,但需要实时性!
与其他模型相比,CenterNet也具有很好的性能,由于它也是一种类似单阶段算法的模型,所以作者主要和单阶段算法进行比较,但也比较了几个two-stage的算法。

其中表格的上半部为two-stage的算法,而下半部为One-Stage的算法,并且在One-Stage算法中分为单尺度/多尺度测试,当然也有FPS用来表征模型的速度,可以看到CenterNet在速度和精度达到了最后的trade-off。
前面说到了,CenterNet在测试阶段不使用NMS算法或其他post-processing,这样合理么?作者也做了实验进行比对,对DLA-34(flip-test)进行加或者不加NMS发现,使用NMS算法其AP从39.2%提高到39.7%。而对于Hourglass-104,其AP没有变化,还是42.2%,为了更高的效率,决定不使用NMS算法。
其他任务的实验结果
3D目标检测

在KITTI数据集的验证结果
姿态估计

在COCO姿态估计的test-dev结果
效果展示

这么强的效果,大家还不赶紧尝试一波去!!!
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~


