赛尔译文 | 从头开始了解Transformer
作者:Peter Bloem
原文:TRANSFORMERS FROM SCRATCH
链接:http://www.peterbloem.nl/blog/transformers
代码:https://github.com/pbloem/former
译者:哈工大SCIR 徐啸,顾宇轩
转载须注明出处:哈工大SCIR
——哈工大SCIR公众号主编 车万翔教授
本文假设读者对于神经网络和反向传播有基本的了解。如果你想要了解,这篇讲座(https://youtu.be/g2lziWxf_9Q)可以提供神经网络的基础知识,同时这篇(https://youtu.be/VZwrbIBNzzA)将解释如何把这些原理应用于现代深度学习系统。
编者注:关于神经网络和反向传播的基础知识,推荐阅读 赛尔译文《神经网络与深度学习》连载 。
读者需要了解Pytorch的工作原理(https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html)来理解编程示例,但也可以放心地跳过这些示例。
Self-attention
任何Transformer架构的基本操作就是self-attention。
我们将在后面解释“self-attention”这个名称的来源,现在不需要纠结于此。
Self-attention是一个序列到序列的操作:一组向量输入,一组向量输出。让我们用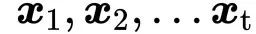
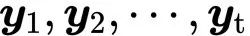
为了产生输出向量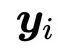
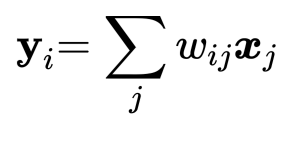
其中 j 是对整个序列的索引,并且其权重总和为1。权重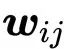
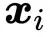
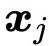
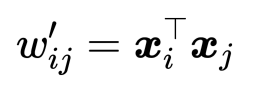
注意,
是与当前输出向量
位置相同的输入向量。对于下一个输出向量,我们使用一系列全新的点积操作,以及不同的加权和。
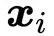 是与当前输出向量
是与当前输出向量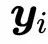 位置相同的输入向量。对于下一个输出向量,我们使用一系列全新的点积操作,以及不同的加权和。
位置相同的输入向量。对于下一个输出向量,我们使用一系列全新的点积操作,以及不同的加权和。点积给出的值在负无穷和正无穷之间,因此我们应用softmax将值映射到 [0,1]并确保它们在整个序列中总和为1:
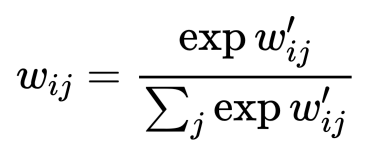
这就是self-attention的基本操作。

基于self-attention的可视化表示。注意未标示出对权重的softmax操作。
完整的Transformer需要一些其他的成分,我们将在之后讨论,但这是基本的操作。更重要的是,这是整个架构中唯一在向量之间传播信息的操作。Transformer中的其余每项操作均应用于输入序列中的各个向量,而不会在向量之间进行交互。
理解为什么self-attention有效
尽管self-attention很简单,但它为何有效并非显而易见。让我们先看看电影推荐任务的标准方法来建立一些直觉。
假设你经营一家电影租赁公司并且有一些电影和一些用户。你希望向你的用户推荐他们可能喜欢的电影。
解决这个问题的一种方法是为电影建立人工特征,例如电影中有多少浪漫成分,以及多少动作成分,然后为用户设计相应的特征:他们喜欢浪漫电影的程度以及他们喜欢动作电影的程度。这样两个特征向量之间的点积将提供电影属性与用户喜好的匹配程度的分数。

如果特征的符号与用户和电影相匹配 — 电影是浪漫的并且用户喜欢浪漫或者电影是不浪漫的并且用户讨厌浪漫 — 那么该特征得到的点积是一个正值。如果符号不匹配 — 电影是浪漫的并且用户讨厌浪漫,反之亦然 — 相应的值是负的。
此外,特征的 数值大小 表明该特征应该对总分有多大贡献:电影可能有点浪漫但是不够明显,或者用户可能是不喜欢浪漫但又有点矛盾。
当然,收集这些特征是不切实际的。对数百万部电影的数据库进行标注是非常昂贵的,并且用喜好程度来标注每一个用户几乎是不可能的。
相反,我们让电影特征和用户特征成为模型的 参数 。然后,我们向用户询问少量他们喜欢的电影,并优化用户特征和电影特征,使它们的点积与已知喜欢的产品相匹配。
即使我们没有告诉模型各个特征的意义,但实际上,经过训练后,这些特征实际上反映了有关电影内容的有意义的信息。

前两个从基本矩阵分解模型中学到的特征。该模型无法访问有关电影内容的任何信息,只有用户喜欢的内容。注意,电影从浅显的到深奥的水平排列,从主流到古怪垂直排列。详见[4]。
有关推荐系统的更多详细信息,请参阅本讲座(https://youtu.be/L2mJ4o7F434)。目前,这足以解释点积如何帮助我们表示对象及其关系。
这是self-attention工作的基本原理。假设我们面对的是一系列单词。为了应用self-attention,我们简单地给词表中的每个单词 t 分配一个嵌入向量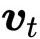
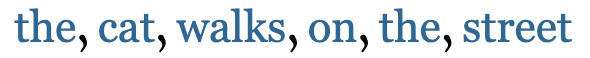
得到向量序列
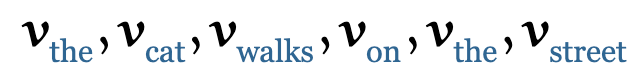
如果我们将该序列输入self-attention层,输出则为另外一列向量
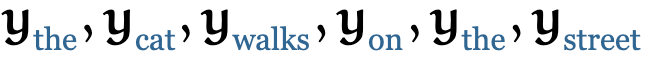
,其中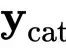
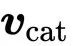
由于我们正在 学习 
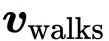
这是self-attention背后的基本直觉。点积表示输入序列中两个向量的由学习任务定义的“相关”程度,并且输出向量是整个输入序列的加权和,其权重由这些点积确定。
在我们继续之前,以下对于序列到序列的操作不常见的特性值得注意:
模型中(目前)没有参数。基本的self-attention实际上完全取决于产生输入序列的任何机制。上游机制,如嵌入层,通过学习特定点积的表示来驱动self-attention(尽管我们稍后会添加一些参数)。
Self-attention将其输入视为一个 集合 ,而不是序列。如果我们置换输入序列,输出序列将完全相同,除了置换之外(即self-attention是 置换等变 的)。当我们构建完整的Transformer时,我们会稍微减弱这一性质,但是self-attention本身实际上 忽略 了输入的顺序性质。
Pytorch实现: 基本的self-attention
正如费曼所说,我不能创造我不理解的东西。随着我们的进展,我们将构建一个简单的Transformer。因此首先需要在Pytorch中实现这个基本的self-attention操作。
我们应该做的第一件事就是弄清楚如何在矩阵乘法中表达self-attention。简单地循环所有向量以计算权重和输出过于缓慢。
我们将维数为 k 的 t 个向量的输入表示为 t * k 的矩阵X。包括一个minibatch维度b,得到一个大小为 (b, t, k) 的输入张量。
所有原始点积的集合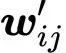
import torch
import torch.nn.functional as F
# assume we have some tensor x with size (b, t, k)
x = ...
raw_weights = torch.bmm(x, x.transpose(1, 2))
# - torch.bmm is a batched matrix multiplication. It
# applies matrix multiplication over batches of
# matrices.然后,为了将原始权重
weights = F.softmax(raw_weights, dim=2)最后,为了计算输出序列,我们只需将权重矩阵乘以X。这产生一批大小为(b, t, e)的输出矩阵Y,其行是对矩阵X的行的加权和。
y = torch.bmm(weights, x)
以上就是通过两个矩阵乘法和一个softmax实现的self-attention。
额外技巧
最新的Transformer中实际使用的self-attention依赖的三个额外技巧。
1) 查询、键和值
每个输入向量
与其余每个向量进行比较以确定其自身输出的权重
将其与其余每个向量进行比较,以确定第 j 个向量
输出的权重
在确定了权重之后被用作加权和的一部分来计算每个输出向量
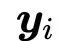
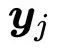 输出的权重
输出的权重这些角色通常称为查询(Query)、键(Key)和值(Value)(我们将在后面解释这些名称的来源)。在我们到目前为止看到的基本self-attention中,每个输入向量必须扮演所有三个角色。通过对原始输入向量应用线性变换,我们能更轻松地为每个角色推导出新的向量。换句话说,我们添加三个 k * k 的权重矩阵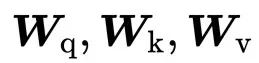
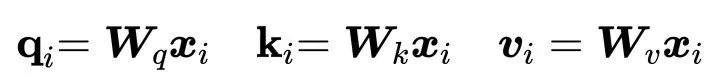
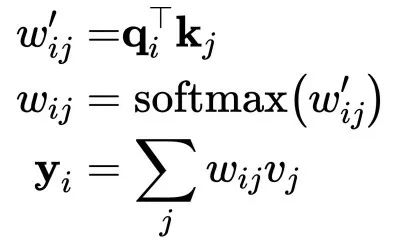
这为self-attention层提供了一些可控参数,并允许它修改传入的向量以适应它们必须扮演的三个角色。

查询、键和值与self-attention的流程图
2) 缩放点积
Softmax函数对非常大的输入值会很敏感。这会导致梯度消失,并减慢学习速度,甚至使其完全停止。由于点积的平均值随着嵌入向量维度 k 的增长而增长,所以将点积的值减小一点有助于防止softmax函数的输入变得过大:
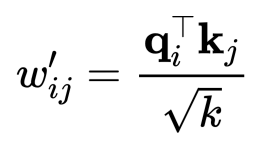
为什么是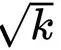
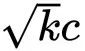
3) Multi-head attention
最后,我们必须考虑到一个词对不同的邻居有不同的意思。考虑以下示例。

我们看到单词gave和句子中的不同部分有不同的关系。mary表示谁正在做给予这件事,而roses表示正在被给予的东西,susan则表示接受者是谁。
在一个简单的self-attention操作中,所有这些信息只被求和到一起。如果susan给了Mary玫瑰花,输出的向量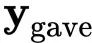
我们可以通过结合几种有不同矩阵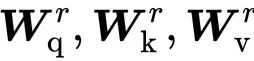
对于输入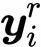
Pytorch实现: 完整的self-attention
现在让我们实现一个详尽的self-attention模块。我们将它打包成Pytorch模块,以便以后重用。
import torch
from torch import nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, k, heads=8):
super().__init__()
self.k, self.heads = k, heads
将三个attention heads组合成一个矩阵(和queries相乘)
我们将h个attention heads视为三个矩阵
# These compute the queries, keys and values for all
# heads (as a single concatenated vector)
self.tokeys = nn.Linear(k, k * heads, bias=False)
self.toqueries = nn.Linear(k, k * heads, bias=False)
self.tovalues = nn.Linear(k, k * heads, bias=False)
# This unifies the outputs of the different heads into
# a single k-vector
self.unifyheads = nn.Linear(heads * k, k)我们现在可以实现self-attention的计算(模块的前向功能)。首先,我们计算查询、键和值:
def forward(self, x):
b, t, k = x.size()
h = self.heads
queries = self.toqueries(x).view(b, t, h, k)
keys = self.tokeys(x) .view(b, t, h, k)
values = self.tovalues(x) .view(b, t, h, k)每个线性模块的输出具有大小 (b,t,h * k),我们简单地重塑为 (b,t,h,k) 给每个head自己的维度。
接下来,我们需要计算点积。这与每个head的操作相同,因此我们将head折叠到batch的维度中。这确保我们可以像以前一样使用torch.bmm(),并且键、查询和值的整个集合将被视为稍微大一些的batch。
由于head和batch的维度不是彼此相邻,我们需要在重塑之前进行转置。(这很昂贵,但似乎是不可避免的。)
# - fold heads into the batch dimension
keys = keys.transpose(1, 2).contiguous().view(b * h, t, k)
queries = queries.transpose(1, 2).contiguous().view(b * h, t, k)
values = values.transpose(1, 2).contiguous().view(b * h, t, k)之前点积可以在单个矩阵乘法中计算,但现在在查询和键之间进行。
在此之前,我们需要将点积的缩放移动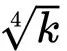
queries = queries / (k ** (1/4))
keys = keys / (k ** (1/4))
# - get dot product of queries and keys, and scale
dot = torch.bmm(queries, keys.transpose(1, 2))
# - dot has size (b*h, t, t) containing raw weights
dot = F.softmax(dot, dim=2)
# - dot now contains row-wise normalized weights我们将self-attention应用于值,从而得到每个attention head的输出。
# apply the self attention to the values
out = torch.bmm(dot, values).view(b, h, t, k)为了统一attention head,我们再次进行转置,使head的维度和嵌入的维度彼此相邻,并重新形成维度为 kh 的拼接向量。之后,我们通过unifyheads层将它们投影回 k 维。
# swap h, t back, unify heads
out = out.transpose(1, 2).contiguous().view(b, t, h * k)
return self.unifyheads(out)现在我们理解了multi-head和scaled dot-product self-attention。你可以在这里(https://github.com/pbloem/former/blob/b438731ceeaf6c468f8b961bb07c2adde3b54a9f/former/modules.py#L10)查看完整的实现。
构建transformers
Transformer不只是一个self-attention层,它是一个架构。目前Transformer的定义还不清楚,但在这里我们将使用以下定义:
任何用于处理连接单元集 (connected units) 的体系结构——例如序列中的标记或图像中的像素——单元之间的唯一交互是通过self-attention。
与其他机制 (例如卷积) 一样,已经出现了或多或少的标准方法,用于如何将self-attention层构建到更大的网络中。第一步是将self-attention包装成一个我们可以重复使用的块。
Transformer块 (block)
关于如何构建基本的Transformer存在一些变化,但大多数结构大致如下:

也就是说,这一模块依次应用:self-attention层,层归一化(layer normalization)层,前馈层(一个独立地应用于每个向量的 MLP 层),以及另一个归一化层。在归一化之前,在两者之间添加残差连接(Residual connections)。各种组件的顺序不是一成不变的;重要的是将self-attention与本地前馈相结合,并添加归一化和残差连接。
归一化和残差连接是用于帮助深度神经网络训练更快,更准确的标准技巧。归一化层仅作用于嵌入维度。
下面是Transformer在pytorch中的样子
class TransformerBlock(nn.Module):
def __init__(self, k, heads):
super().__init__()
self.attention = SelfAttention(k, heads=heads)
self.norm1 = nn.LayerNorm(k)
self.norm2 = nn.LayerNorm(k)
self.ff = nn.Sequential(
nn.Linear(k, 4 * k),
nn.ReLU(),
nn.Linear(4 * k, k))
def forward(self, x):
attended = self.attention(x)
x = self.norm1(attended + x)
fedforward = self.ff(x)
return self.norm2(fedforward + x)我们做了相对随意的选择,使前馈的隐藏层的隐藏层节点数量成为输入和输出节点数量的 4 倍。较小的值也可以起作用,并节省内存,但它应该大于输入/输出层。
分类Transformer
我们可以构建的最简单的Transformer是序列分类器。我们将使用 IMDb 情绪分类数据集:实例是电影评论,被标记为单词序列,并且分类标签是正面 (positive) 和负面 (negative) 的 (指示评论是关于电影的正面还是负面) 。
该架构的核心只是一大堆的Transformer块。我们需要做的就是弄清楚如何为输入序列提供输入,以及如何将最终输出序列转换为一个单一分类。
我们不会在这篇博客文章中讲解处理数据的事情。按照代码中的链接查看数据的加载和准备方式。整个实验可以在这里找到:https://github.com/pbloem/former/blob/master/experiments/classify.py
输出: 生成分类
从序列到序列层构建序列分类器的最常用方法,是将全局平均池化应用于最终的输出序列,并将结果映射为 softmax 处理后的类别向量。

一个简单的序列分类 Transformer 的概述。对输出序列求平均以产生表示整个序列的单一向量。该向量被投影到一个向量,向量中的每一个元素对应实际的每一个类别,并且使用 softmax 以生成概率。
输入: 使用位置
我们已经讨论了嵌入层的原理。我们使用它来表示单词。
但是,正如我们已经提到的那样,我们堆叠置换等变层,最终的全局平均池化是置换不变的,因此整个网络也是置换不变的。更简单地说:如果我们打乱句子中的单词,无论我们学习到什么权重,我们都会得到完全相同的分类。显然,我们希望我们最先进的语言模型至少对单词顺序有一些敏感性,因此需要修复这一问题。
解决方案很简单:我们创建一个等长的第二个向量,它表示单词在当前句子中的位置,并将其添加到单词嵌入中。这里有两种选择。
位置嵌入 我们只是简单地像创建词嵌入一样,创建了位置的嵌入。就像我们创建嵌入向量

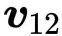
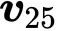
位置编码 位置编码的工作方式与嵌入相同,只是我们不学习位置向量,我们只选择一些函数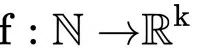
为简单起见,我们将在实现中使用位置嵌入。
Pytorch
这是pytorch中的完整文本分类Transformer。
class Transformer(nn.Module):
def __init__(self, k, heads, depth, seq_length, num_tokens, num_classes):
super().__init__()
self.num_tokens = num_tokens
self.token_emb = nn.Embedding(k, num_tokens)
self.pos_emb = nn.Embedding(k, seq_length)
# The sequence of transformer blocks that does all the
# heavy lifting
tblocks = []
for i in range(depth):
tblocks.append(TransformerBlock(k=k, heads=heads))
self.tblocks = nn.Sequential(*tblocks)
# Maps the final output sequence to class logits
self.toprobs = nn.Linear(k, num_classes)
def forward(self, x):
"""
:param x: A (b, t) tensor of integer values representing
words (in some predetermined vocabulary).
:return: A (b, c) tensor of log-probabilities over the
classes (where c is the nr. of classes).
"""
# generate token embeddings
tokens = self.token_emb(x)
b, t, e = tokens.size()
# generate position embeddings
positions = torch.arange(t)
positions = self.pos_emb(positions)[None, :, :].expand(b, t, e)
x = tokens + positions
x = self.tblocks(x)
# Average-pool over the t dimension and project to class
# probabilities
x = self.toprobs(x.mean(dim=1))
return F.log_softmax(x, dim=1)在深度为6,最大序列长度为 512 时,该Transformer的精度达到约85%,与RNN模型的结果相比更好,并且训练速度更快。为了看到Transformer真正的近人类的表现,我们需要在更多数据上训练更深入的模式。更多关于如何在以后做到这一点。
文本生成Transformer
我们下一个将尝试的技巧是自回归 (autoregressive) 模型。我们将训练一个字符级 Transformer 来预测序列中的下一个字符。训练制度很简单 (并且比 Transformer 的周期长得多(http://karpathy.github.io/2015/05/21/rnn-effectiveness/))。我们向序列到序列模型输入一个序列,并且我们要求它预测序列中每个时间点的下一个字符。换句话说,目标输出是向左移动一个字符的相同序列:

对于 RNN ,这是我们需要做的全部,因为它们无法在输入序列中向前看:输出 i 仅取决于输入 0 到 i 。对Transformer,输出取决于整个输入序列,因此预测下一个字符变得很容易,只需从输入中检索它。
要使用self-attention作为自回归模型,我们需要确保它不能在序列中向前看。我们通过在应用softmax之前,将掩码应用于点积矩阵来实现此目的。该掩码禁用矩阵对角线上方的所有元素。

使用mask的self-attention,确保元素只能处理序列中前面的输入元素。请注意,乘法符号有点误导:我们实际上将屏蔽掉的元素(白色方块)设置为负无穷。
由于我们希望在softmax之后这些元素为零,我们将它们设置为负无穷。下面是 pytorch 中的实现:
dot = torch.bmm(queries, keys.transpose(1, 2))
indices = torch.triu_indices(k, k, offset=0)
dot[:, indices[0], indices[1]] = float('-inf')
dot = F.softmax(dot, dim=2) 在我们像这样阻碍self-attention模块之后,模型不再能够在序列中向前看。
我们在标准 enwik8 数据集上训练 (取自 Hutter 奖(http://prize.hutter1.net/)) ,其中包含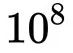
我们使用 12 个Transformer块和嵌入维度为 256 的模型训练长度为 256 的序列。在RTX 2080Ti(大约 170K 个大小为 32 的批次)的大约 24 小时训练之后,我们让模型从一个 256 个字符的种子开始生成:对于每个字符,我们为它提供前面的 256 个字符,并查看它为下一个字符(最后一个输出向量)预测的内容。我们从temperature(https://towardsdatascience.com/how-to-sample-from-language-models-682bceb97277)为 0.5 的样本中进行采样,然后移动到下一个字符。
输出像下面这样:
1228X Human & Rousseau. Because many of his stories were originally published in long-forgotten magazines and journals, there are a number of [[anthology|anthologies]] by different collators each containing a different selection. His original books have been considered an anthologie in the [[Middle Ages]], and were likely to be one of the most common in the [[Indian Ocean]] in the [[1st century]]. As a result of his death, the Bible was recognised as a counter-attack by the [[Gospel of Matthew]] (1177-1133), and the [[Saxony|Saxons]] of the [[Isle of Matthew]] (1100-1138), the third was a topic of the [[Saxony|Saxon]] throne, and the [[Roman Empire|Roman]] troops of [[Antiochia]] (1145-1148). The [[Roman Empire|Romans]] resigned in [[1148]] and [[1148]] began to collapse. The [[Saxony|Saxons]] of the [[Battle of Valasander]] reported the y请注意,这里正确使用了Wikipedia链接标记语法,链接中的文本代表链接的合理主题。最重要的是,请注意有一个粗略的主题一致性;生成的文本在不同地方使用不同的相关术语保持圣经和罗马帝国的主题。虽然这远远不如GPT-2这样的模型的性能,但是相比于RNN模型的优势已经很明显:更快的训练 (类似的RNN模型需要花费很多天训练) 和更好的长期一致性。
如果你很好奇,the Battle of Valasander 似乎是网络的发明。
此时,该模型在验证集上实现每字节 1.343 比特的压缩,这与GPT-2模型 (下面描述) 实现的每字节 0.93 比特的现有技术相差不太远。
设计注意事项
为了理解为什么Transformer以这种方式设置,这有助于理解其中的基本设计注意事项。Transformer的主要目的是克服之前最先进的RNN架构 (通常是LSTM或GRU) 的问题。展开后(https://colah.github.io/posts/2015-08-Understanding-LSTMs/),RNN看起来像这样:

这里最大的弱点是循环连接。虽然这允许信息沿着序列传播,但这也意味着我们无法在时间步骤 i 计算单元,直到我们在时间步长 i-1 计算单元。将此与 1D 卷积进行对比:

在该模型中,每个输出向量可以与其他每个输出向量并行计算。这使得卷积更快。然而,卷积的缺点在于它们在模拟远程依赖方面受到严重限制。在一个卷积层中,只有相距比卷积核大小更小的单词才能相互交互。为了更长的依赖性,我们需要堆叠许多卷积。
Transformer试图吸收两者的优点。它们可以对输入序列的整个范围建立依赖关系,就像它们彼此相邻的单词一样容易 (事实上,没有位置向量,它们甚至无法区分) 。然而,这里没有循环连接,因此可以以非常有效的前馈方式计算整个模型。
Transformer设计的其余部分主要基于一个考虑因素:深度。大多数选择都来自于训练大量Transformer块的愿望。注意,例如Transformer中只有两个位置出现非线性:self-attention中的softmax和前馈层中的ReLU。模型的其余部分完全由线性变换组成,完美地保留了梯度。
我认为层归一化也是非线性的,但这是一个实际上有助于保持梯度在向下传播回网络时,保持稳定的非线性。
历史包袱
如果你已经读过其他Transformer的介绍,你可能已经注意到它们包含了我跳过的一些内容。我认为这些都不是理解最新的Transformer的必要条件。然而,它们有助于理解一些术语和一些关于最新的Transformer的文章。
为什么称作self-attention?
在首次提出self-attention之前,序列模型主要包括堆叠在一起的循环网络或卷积。实验表明有些时候通过添加注意力机制能够提升模型性能:引入了一个中间机制而不是将前一层的输出序列直接输送到下一层。
一般机制如下。我们将输入称为值 (value) 。一些 (可训练的) 机制为每个值分配一个键 (key) 。然后,对于每个输出,一些其他机制指定一个查询 (query) 。
这些名称源自键值存储的数据结构。在这种情况下,我们希望我们存储中只有一个项目具有与查询匹配的密钥,该查询在执行查询时返回。注意力是一个更宽松的版本:对于任一查询而言,存储中的每个键都在某种程度上与该查询相关。我们返回所有键与该查询匹配程度的结果并且进行加权求和。
self-attention 的重大突破是,注意力本身就是一个足够强大的机制来完成所有的学习。正如作者所说, Attention is all you need(https://arxiv.org/abs/1706.03762)。键、查询和值都是相同的向量(具有轻微的线性变换)。它们关注自己,堆叠这种self-attention提供了足够的非线性和表示能力来学习非常复杂的函数。
最初的Transformer: 编码器和解码器
但作者并没有免除当代序列建模的所有复杂性。过去,序列到序列模型的标准结构是编码器 - 解码器架构,使用教师强制(teacher forcing)(https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html)。

编码器获取输入序列并将其映射到表示整个序列的单个潜在向量。然后将该向量传递给解码器,解码器将其取出到所需的目标序列 (例如,另一种语言的同一句话) 。
教师强制指的是也允许解码器访问输入句子的技术,但是是以自回归方式。也就是说,解码器基于潜在向量和它已经生成的单词生成逐字输出语句。这消除了潜在表示的一些压力:解码器可以使用逐字逐句采样来处理句法和语法等低级结构,并使用潜在向量来捕获更高级别的语义结构。理想情况下,使用相同的潜在向量解码两次将给出两个具有相同含义的不同句子。
在后来的Transformer中,如BERT和GPT-2,完全省去了编码器/解码器配置。发现一堆简单的Transformer块足以在许多基于序列的任务中实现现有技术水平。
这有时被称为decoder-only Transformer (用于自回归模型) 或encoder-only Transformer (用于没有掩码的模型) 。
最新的Transformers
这里有一些最新的Transformer及其最具特色的细节。
BERT
https://arxiv.org/abs/1810.04805
BERT是最早的模型之一,表明Transformer可以在各种基于语言的任务上达到人类水平的表现:问答,情感分类或分类两个句子是否自然地接续。
BERT由一组简单的Transformer块组成,我们上面描述的类型。该结构是在大型通用域语料库上预先训练的,该语料库包括来自英语书籍的 800M 单词 (现代作品,来自未发表的作者) 和来自英语维基百科文章的 2.5B 单词 (没有标记) 。
预训练是通过两个任务完成的:
Masking 对输入序列中的部分单词进行以下任一操作:屏蔽掉、用随机单词替换或按原样保存。然后要求该模型根据这些单词预测原始单词是什么。需要注意的是,模型不需要预测整个去噪的句子(即masking之前的原始输入),只需要恢复已被masking修改的单词。由于模型不知道将询问哪些单词,因此它会学习序列中每个单词的表示。
Next sequence classification 对两个约 256 个单词的序列进行采样,其中 (a) 直接在语料库中相互接续,或者 (b) 都取自随机位置。然后,模型必须预测情况是 a 还是 b 。
BERT使用 WordPiece 标记化,它位于字级和字符级序列之间。它将像 walking 这样的单词分解为标记 walk 和 ##ing。这允许模型基于单词结构做出一些推断:以 -ing 结尾的两个动词具有相似的语法功能,并且两个以 walk- 开始的动词具有相似的语义功能。
输入前面带有一个特殊的 <cls> 标记。对应于该标记的输出向量用作序列分类任务中的句子表示,如下一句子分类 (与我们在上面的分类模型中使用的所有向量的全局平均池化相对) 。
在预训练之后,在Transformer的主体之后放置一个单一任务特定层,其将通用表示映射到任务特定输出。对于分类任务,这只是将第一个输出标记映射到类上的softmax概率。对于更复杂的任务,最终的序列到序列层是专门为该任务设计的。
然后重新训练整个模型,以针对手头的特定任务微调模型。
在消融实验中,作者表明,与之前的模型相比,最大的改进来自BERT的双向性质。也就是说,像GPT这样的先前模型使用了自回归掩码,只允许注意以前的标记。在BERT中,所有注意力都集中在整个序列上是提高性能的主要原因。
这就是为什么 BERT 中的 B 代表“双向”的原因。
最大的BERT模型使用 24 个Transformer模块,嵌入尺寸为 1024 和 16 个注意头,产生 340M 参数。
GPT-2
https://openai.com/blog/better-language-models/
GPT-2是实际上第一个成为主流新闻的Transformer模型,此前OpenAI公司决定不发布完整模型。
因为 GPT-2 可以产生足够可信的文本,单凭一己之力便可生成像2016年美国总统大选时所见到的那样多的假新闻。
GPT-2的作者使用的第一个技巧是创建一个新的高质量数据集。虽然BERT使用高质量的数据 (精心制作的书籍和精心编辑的维基百科文章) ,但这导致其在写作风格上有一定程度的欠缺。为了在不牺牲质量的情况下收集更多不同的数据,作者使用社交媒体网站Reddit找到的一大堆具有一定最低社会支持度的文本 (在 Reddit 上称作 karma ) 。
GPT-2基本上是一种语言生成模型,因此它像我们在上面的模型中所做的那样使用了masked self-attention。它使用byte-pair编码来对语言进行标记,这与WordPiece编码一样,将单词分解为比单个字符略大但小于整个单词的标记。
GPT-2的构建与上面的文本生成模型非常相似,只是在各层顺序之间有微小的差异,另外也增加了一些深层网络训练的技巧。GPT-2最大的型号使用48个Transformer块,其中序列长度为1024,嵌入尺寸为1600,总共有1.5B参数。
它们在许多任务中表现出最先进的性能。例如我们上面尝试的维基百科压缩任务中,它们每字节达到0.93位。
Transformer-XL
https://arxiv.org/abs/1901.02860
虽然Transformer代表了远程依赖建模的巨大飞跃,但到目前为止我们看到的模型仍然基本上受到输入大小的限制。由于点积矩阵的大小在序列长度上呈二次方式增长,因此当我们尝试扩展输入序列的长度时,这很快成为瓶颈。Transformer-XL是首批成功解决此问题的Transformer模型之一。
在训练期间,一长串文本 (比模型可以处理的更长) 被分解为更短的片段。每个片段按顺序处理,在当前片段和前一片段中的标记上计算self-attention。仅在当前段上计算梯度,但是当段窗口在文本中移动时,信息仍会传播。理论上,窗口在第n层时只会使用n层之前的信息。
RNN训练中的类似技巧称为随时间截断的反向传播。我们为模型提供了一个很长的序列,但只反向传播它的一部分。序列中第一个没有计算梯度的部分仍然影响它们所在部分中隐藏状态的值。
为了使这个方法有效,作者不得不放弃标准位置编码/嵌入方案。由于位置编码是绝对的,因此每个片段的编码都会改变,从而导致整个序列的位置嵌入不一致。相反,他们使用相对编码。对于每个输出向量,使用不同的位置向量序列,其表示的不是绝对位置,而是到当前输出的距离。
这需要将位置编码移动到注意机制中。一个好处是产生的Transformer可能会更好地推广到看不见长度的序列。
稀疏(Sparse) Transformer
https://openai.com/blog/sparse-transformer/
稀疏Transformer正面解决了使用二次方存储空间的问题。它们不是计算密集的注意力矩阵 (它们以二次方式增长) ,而是仅为特定的输入标记对计算self-attention,从而产生稀疏的注意力矩阵,只有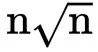
这允许模型处理规模非常大的上下文,例如对于图像的生成建模,在像素之间具有大的依赖性。这里需要权衡的问题是稀疏结构是不可学习的,既然选择了稀疏矩阵,我们将无法使用一些可能有用的输入token之间的交互信息。然而,两个不直接相关的单元仍然可以在Transformer的较高层中相互作用 (类似于卷积神经网络用更多卷积层构建更大的接收场) 。
除了能训练具有处理长序列能力的Transformer的简单好处之外,稀疏Transformer还允许以非常优雅的方式设计归纳偏差。我们将一系列单位的集合 (例如:单词,字符,图像中的像素,图中的节点) 作为输入,并通过注意矩阵的稀疏性指定我们认为相关的单位。剩下要做的就是将Transformer建造得尽可能深,再看看训练效果如何。
更进一步
训练Transformer的一大瓶颈是self-attention的点积矩阵。对于序列长度t ,这是包含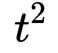
然而,文献中报道的模型包含的序列长度超过 12000,具有 48 层Transformer(https://openai.com/blog/sparse-transformer/),使用密集点积矩阵。当然,这些模型在集群上进行训练,但仍然需要单个GPU来执行单个前向/后向传播。我们如何将这些巨大的Transformer装入 12Gb 的内存中?有三个主要技巧:
半精度 在现代GPU和TPU上,张量计算可以在 16 位浮点张量上有效地完成。这并不像将张量的 dtype 设置为 torch.float16 那么简单。对于网络的某些部分,如损失,需要 32 位精度。但是现有的库(https://github.com/NVIDIA/apex)可以相对轻松地处理大部分内容。实际上,这会使你的有效内存加倍。
梯度积累 对于大型模型,我们可能只能在单个实例上执行前向/后向传播。批量大小为 1 时不太能进行稳定的学习。幸运的是,我们可以在更大的批次中为每个实例执行单个前进/后退,并简单地加和我们得到的梯度 (这是多变量链规则的结果(https://youtu.be/VZwrbIBNzzA?t=1562)) 。当我们处理完该批次时,执行单步的梯度下降,并将梯度归零。在Pytorch中,这很容易:你觉得你的训练循环中的 optimizer.zero_grad() 调用似乎是多余的吗?如果你不进行该调用,新的梯度会被简单地添加到旧梯度中。
设置梯度检查点 如果你的模型太大,即使单个前进/后退内存也会溢出,你可以为了内存效率权衡更多的计算。在梯度检查点中,将模型分成几个部分。对于每个部分,可以单独向前/向后计算梯度,而不保留其余部分的中间值。Pytorch有特殊的设置梯度检查点的功能(https://pytorch.org/docs/stable/checkpoint.html)。
有关如何执行此操作的详细信息,请参阅此博客帖子(https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255)。
结论
几十年来,Transformer可能是最简单的机器学习架构。如果还没有关注它们的话,现在你有充分的理由了。
首先,当前的性能限制纯粹是在硬件中。与卷积或LSTMs不同,当前对它们 能力的限制完全取决于我们可以在GPU内存中放置的模型有多大以及我们可以在一段可靠的时间内推送多少数据。我毫不怀疑,我们最终会达到更多层次和更多数据不再有用的程度,但目前似乎还有远未达到。
其次,Transformer非常通用。到目前为止,Transformer在语言建模方面以及图像和音乐分析方面取得了巨大成功,但其普遍性还有待探索。基本的Transformer是一种set-to-set的模型。只要你的数据是一组单位,就可以应用Transformer。你可以通过添加位置嵌入或通过修改注意力矩阵的结构 (使其稀疏或掩盖部分) 来添加任何有关数据的额外信息(例如局部结构)。
这在多模态学习中特别有用。我们可以轻松地将标题图像组合成一组像素和字符,并设计一些巧妙的嵌入和稀疏结构,以帮助模型找出如何组合和对齐两者。如果将我们领域的全部知识结合到相关结构中,如多模态知识图 (如[3]中所讨论的) ,就可以使用简单的Transformer块在多模态单元之间传播信息,并将使它们与稀疏结构对齐,从而控制哪些单元直接相互作用。
到目前为止,Transformer仍然主要被视为语言模型。我希望在不久后,我们会看到它们在其他领域被更多的采用,不仅仅是为了提高性能,而是为了简化现有模型,并允许从业者更直观地控制模型的归纳偏差。
参考文献
[1] The illustrated transformer. Jay Allamar.
[2] The annotated transformer. Alexander Rush.
[3] The knowledge graph as the default data model for learning on heterogeneous knowledge. Xander Wilcke, Peter Bloem, Victor de Boer.
[4] Matrix factorization techniques for recommender systems. Yehuda Koren et al.
延伸阅读
本期责任编辑:张伟男
本期编辑:顾宇轩
“哈工大SCIR”公众号
主编:车万翔
副主编:张伟男,丁效
执行编辑:李家琦
责任编辑:张伟男,丁效,崔一鸣,李忠阳
编辑:赖勇魁,李照鹏,冯梓娴,王若珂,顾宇轩
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号:”哈工大SCIR” 。





