多图带你读懂 Transformers 的工作原理

本文为 AI 研习社编译的技术博客,原标题 :
How Transformers Work
作者 | Giuliano Giacaglia
翻译 | 胡瑛皓
校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/transformers-141e32e69591
注:本文的相关链接请访问文末二维码
Transformer是一类神经网络架构,现在越来越受欢迎了。Transformer最近被OpenAI用于训练他们的语言模型,同时也被DeepMind的AlphaStar 采用,用于他们的程序击败那些顶级星际玩家。
Transformer是为了解决序列传导问题或神经网络机器翻译而设计的,意味着任何需要将输入序列转换为输出序列的任务都可以用,包括语音识别和文本到语音转换等。

序列传导。绿色表示输入,蓝色表示模型,紫色表示输出。动图摘自:jalammar.github.io
对于需要进行序列传导的模型,有必要有某种记忆。例如,我们将以下句子翻译到另一种语言(法语):
“The Transformers” are a Japanese [[hardcore punk]] band. The band was formed in 1968, during the height of Japanese music history”
本例中,第二句话中的“the band”一词指代第一句中引入的“The Transformers”。当你读到第二句中的"the band",你知道它指的是“The Transformers” band。这可能对翻译很重要。事实上,后一句话中的某个词指代前几句话中出现的某个词,像这样的例子很多。
翻译这样的句子,模型需要找出之间的依赖和关联。循环神经网络 (RNNs)和卷积神经网络(CNNs)由于其特性已被使用来解决这个问题。 让我们回顾一下这两种架构及其缺点。
循环神经网络
循环神经网络内部有循环,允许信息保存其中。

输入表示为 x_t
如上图所示,我们看到神经网络的一部分A,处理输入x_t,然后输出h_t。A处循环使得信息可从前一步传递至后一步。
可以换一种方式思考这些循环。循环神经网络可认为是同一网络A的多重备份,每个网络将信息传递给其后续网络。看一下如果我们将循环展开会如何:
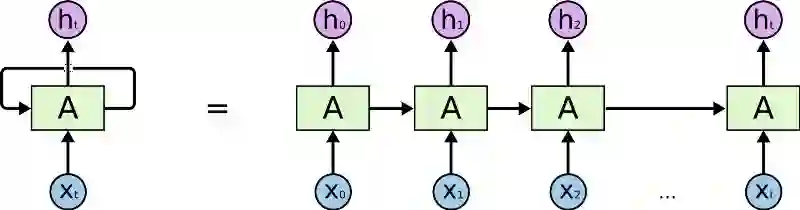
展开的循环神经网络
图中链式本质清楚地表明循环神经网络与序列和列表相关。 如果以这种方式翻译一段文本,需要将文本中的每个单词设置为其输入。循环神经网络将序列中前面的词语的信息传入后一个神经网络,这样便可以利用和处理这些信息。
下图展示了sequence to sequence模型通常是如何用循环神经网络工作的。每个单词被单独处理,然后将编码阶段的隐状态传入解码阶段以生成结果句子,然后这样就产生了输出。
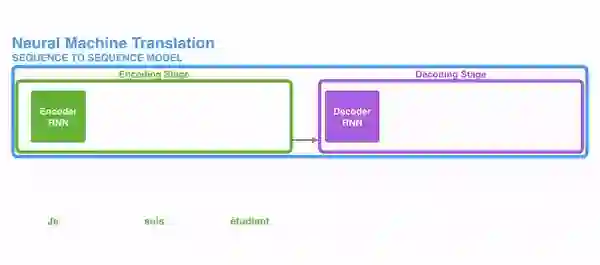
动图摘自此文:jalammar.github.io
长期依赖的问题
考虑一下这类模型,即使用之前看到的单词预测下一个单词。如果我们需要预测这句话“the clouds in the ___”的下一个单词,不需要额外的语境信息,很显然下个单词是“sky”。
这个例子里,相关信息和需预测单词的距离很近。循环神经网络可以学习前面的信息,并找出句中下一个单词。
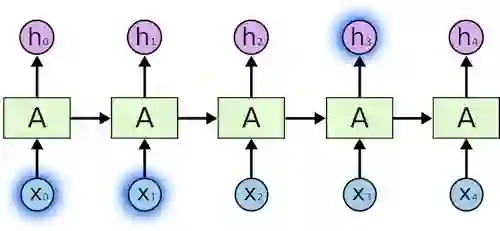
图片摘自此文:colah.github.io
但有些情况我们需要更多语境信息。例如试图预测这句话的最后一个单词: “I grew up in France… I speak fluent ___”。 最靠近这个单词的信息建议这很有可能是一种语言,但当你想确定具体是哪种语言时,我们需要语境信息France,而这出现在较前面的文本中。
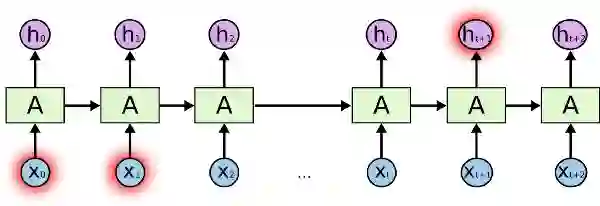
图片摘自此文:colah.github.io
当相关信息和词语之间距离变得很大时,RNN变得非常低效。那是因为,需要翻译的信息经过运算中的每一步,传递链越长,信息就越可能在链中丢失。
理论上RNN可以学习这些长期依赖关系,不过实践表现不佳,学不到这些信息。因而出现了LSTM,一种特殊的RNN,试图解决这类问题。
Long-Short Term Memory (LSTM)
我们平时安排日程时,通常会为不同的约会确定不同的优先级。如果有什么重要行程安排,我们通常会取消一些不那么重要的会议,去参加那些重要的。
RNN不会那么做。无论什么时候都会不断往后面加信息,它通过应用函数转换全部现有信息。在过程中所有信息都被修改了,它不去考虑哪些重要,哪些不重要。
LSTMs在此基础上利用乘法和加法做了一些小改进。在LSTMs里,信息流经一种机制称为细胞状态。LSTM便可以选择性的记忆或遗忘那些重要或不重要的事情了。
LSTM内部看起来像是这样:
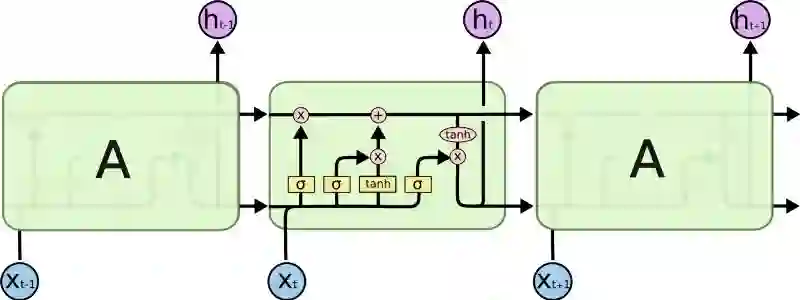
图片摘自此文:colah.github.io
每个细胞的输入为x_t (在句子到句子翻译这类应用中x_t是一个单词), 上一轮细胞状态以及上一轮的输出。模型基于这些输入计算改变其中信息,然后产生新的细胞状态和输出。本文不会详细讲每个细胞的实现机制。如果你想了解这些细胞的运作机制,推荐你看一下Christopher的博客:
Understanding LSTM Networks -- colah's blog
这些循环使得循环神经网络看起来有点神秘。 但如果再细想一下,事实上https://colah.github.io/posts/2015-08-Understanding-LSTMs/
采用细胞状态后,在翻译过程中,句子中对翻译单词重要的信息会被一轮一轮传递下去。
LSTM的问题
总体来说问题LSTM的问题与RNN一样,例如当句子过长LSTM也不能很好的工作。原因在于保持离当前单词较远的上下文的概率以距离的指数衰减。
那意味着当出现长句,模型通常会忘记序列中较远的内容。RNN与LSTM模型的另一个问题,由于不得不逐个单词处理,因此难以并行化处理句子。不仅如此,也没有长短范围依赖的模型。总之,LSTM和RNN模型有三个问题:
顺序计算,不能有效并行化
没有显示的建模长短范围依赖
单词之间的距离是线性的
Attention
为了解决其中部分问题,研究者建立了一项能对特定单词产生注意力的技能。
当翻译一个句子,我会特别注意我当前正在翻译的单词。当我录制录音时,我会仔细聆听我正在写下的部分。如果你让我描述我所在的房间,当我这样做的时候,我会瞥一眼描述的物体。
神经网络用attention可以做到同样的效果,专注于给出信息的那部分。例如,RNN可注意另一RNN的输出。在每个时点它聚焦于其他RNN不同的位置。
为了解决这些问题,注意力(attention)是一种用于神经网络的技术。 对于RNN模型,与其只编码整个句子的隐状态,我们可以把每个单词的隐状态一起传给解码器阶段。在RNN的每个步骤使用隐藏状态进行解码。详见下面动图
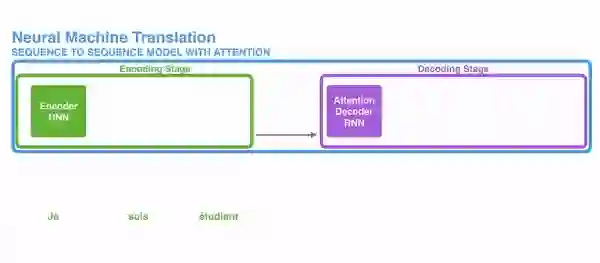
绿色步骤是编码阶段,紫色步骤是解码阶段,动图摘自此文:jalammar.github.io
其背后的想法是句子每个单词都有相关信息。为了精确解码,需要用注意力机制考虑输入的每个单词。
对于要放入序列传导RNN模型的注意力,我们分成编码和解码两步。一步以绿色表示另一步以紫色表示。绿色步骤称为编码阶段紫色步骤称为解码阶段。

动图摘自此文:jalammar.github.io
绿色步骤负责由输入建立隐状态。我们把句子中每个单词产生的所有隐状态传入解码阶段,而不是和过去的attention一样,仅传递一个隐状态给解码器。每个隐状态都会在解码阶段被使用,去找出网络应该注意的地方。
比如,当我们翻译这句 “Je suis étudiant”法语句子到英语时,需要在翻译时解码步骤去查不同的单词。

此动图展示当翻译“Je suis étudiant”至英语时,如何给每个隐状态赋予权重。颜色越深对于每个单词的权重越大。动图摘自此文:jalammar.github.io
或再比如,当你将“L’accord sur la zone économique européenne a été signé en août 1992.” 法语翻译成英语,下图展示了需要对每个输入赋予多少注意力。

翻译 “L’accord sur la zone économique européenne a été signé en août 1992.”法语句子到英文。图片摘自此文:jalammar.github.io
不过我们前面讨论的一些问题,用带attention的RNN仍然无法解决。比如,不可能并行处理输入的单词。对较大的文本语料,增加了翻译文本的用时。
卷积神经网络
卷积神经网络可以帮助解决这些问题,可以做到:
并行化 (按层)
利用局部依赖
位置间的距离是对数级的
一些最流行的序列传导网络, 例如 Wavenet和Bytenet就采用卷积神经网络。
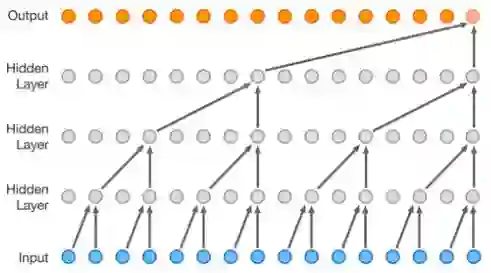
【注】查看本动图,请点击文末“阅读原文“
Wavenet, 模型采用卷积神经网络 (CNN). 动图摘自此文
卷积神经网络可并行处理是因为,输入的每个单词可被同时处理并不必依赖于前一个单词翻译的结果。不仅如此,输出单词与任何CNN输入的单词的“距离”是log(N) 数量级— — 即输入单词到输出单词连线形成的树的高度 (如上面动图所示)。 这比RNN输出到其输入的距离要好很多,因为其距离是N数量级。
问题在于卷积神经网络在翻译句子过程中不一定有助于解决依赖问题。这就是transformers被创造出来的原因,它结合了CNN和attention机制.
Transformers
Transformers模型试图结合卷积神经网络和attention机制解决并行化问题。attention机制提升模型从一个序列转换为另一个序列的速度。
我们来看一下Transformer是如何工作的。Transformer是一类用attention来提速的模型,具体来说使用的是self-attention。

Transformer, 图片摘自此文:jalammar.github.io
从内部来看Transformer与之前模型架构相似,只是Transformer由6个编码器和6个解码器组成。
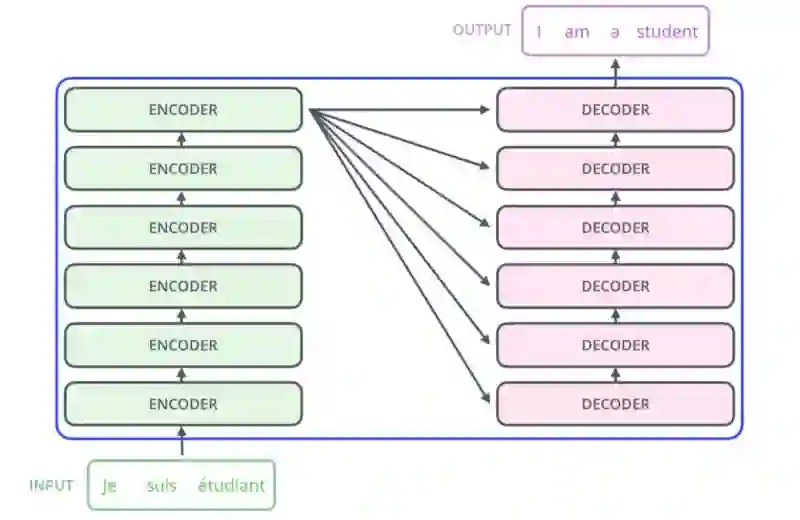
图片摘自此文:jalammar.github.io
编码器非常相似,所有编码器都具有相同的架构。解码器也有相同的属性诸如互相之间非常相似。编码器有两层: self-attention层和前馈神经网络层。
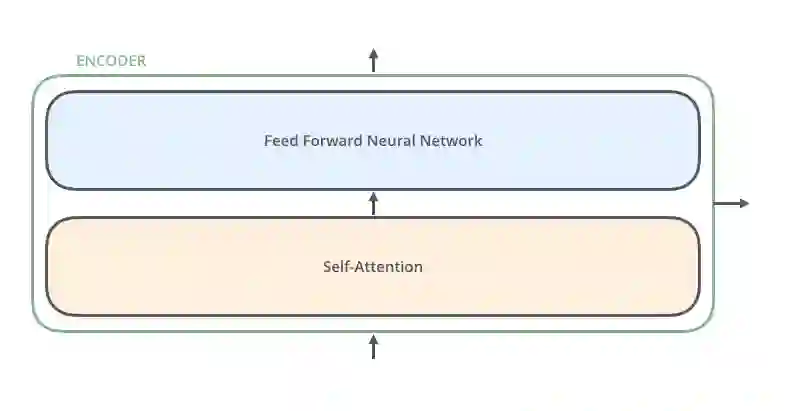
图片摘自此文:jalammar.github.io
编码器的输入先进入self-attention层,有助于编码器在编码句中特定单词时可参考输入句子中其他单词。解码器也包含这两层,不过在两层中间增加了attention层,以帮助解码器聚焦到输入句子的相关部分。
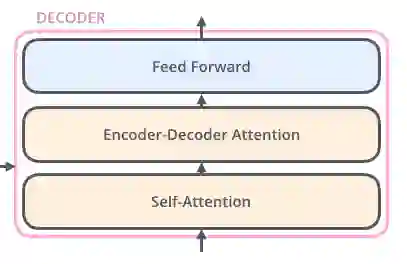
图片摘自此文:jalammar.github.io
Self-Attention
注: 这部分转自Jay Allamar的博文 https://jalammar.github.io/illustrated-transformer/
我们来看一下模型中各种不同的向量/张量,它们在已训练模型组件中如何流转,从而把输入转化成输出的。 由于这是一个NLP应用实例,我们先用词嵌入算法把每个输入的词语转换为词向量。

图片摘自此文:jalammar.github.io
每个单词被转换为一个长度512的向量。图中我们用这些简单的方块表示这些向量。
仅在最底层的解码器处进行词嵌入转换。对于所有编码器,它们都接收大小为512的向量列表
最底层的编码器接收的是词嵌入,但其他编码器接收的输入是其下一层的直接输出。当输入序列中的单词做词嵌入转换后,数据就按顺序流经各层编码器的2层结构。
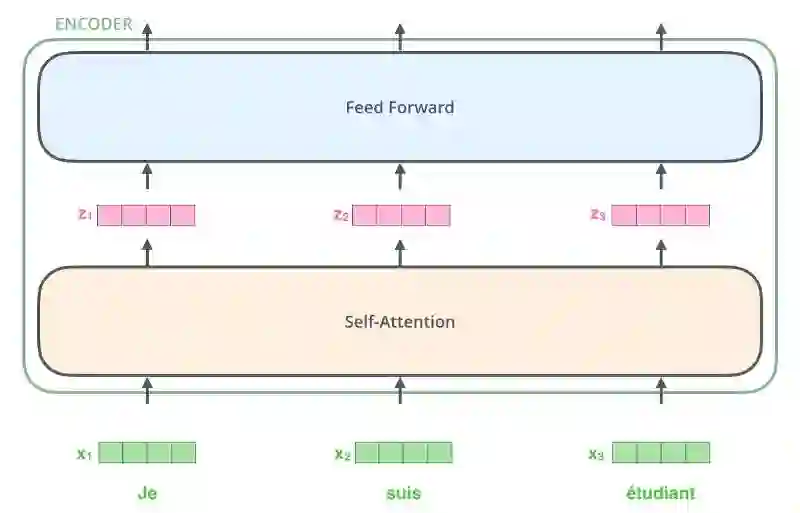
图片摘自此文:jalammar.github.io
此处我们开始看到Transformer的一个重要特性,每个位置上的单词在编码器中流经自己的路径。在self-attention层处理这些路径的依赖关系。前馈神经网络不处理这些依赖关系。这样当数据流经前馈神经网络时,不同的路径可被并行执行。
接下来,我们将切换到一句短句实例,看一下在编码器的子层里会发生什么。
Self-Attention
首先让我们来看一下如何用向量计算self-attention,然后再看一下利用矩阵运算的实现方式。
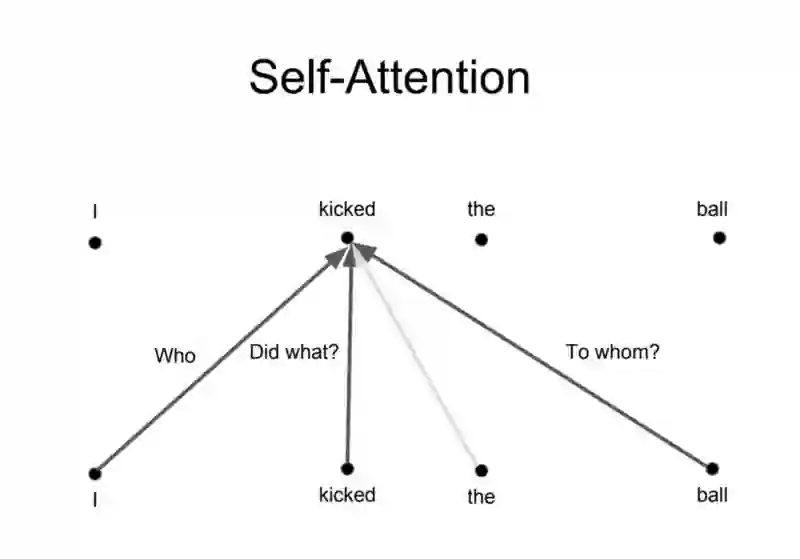
找出句中单词之间的关系并给出正确的注意力。图片摘自此文:http://web.stanford.edu
self-attention计算的第一步是通过编码器的输入向量 (本例中是每个单词的词嵌入向量) 建立Query, Key和Value三个向量,我们通过输入的词嵌入向量乘以之前训练完成的三个矩阵得到。
注意,这些新向量的长度小于词嵌入向量的长度。这里取64,而词嵌入向量及编码器的输入输出长度为512。这是一个架构性选择,向量长度不需要变得更小,使得多头注意力(multiheaded attention)计算基本稳定。
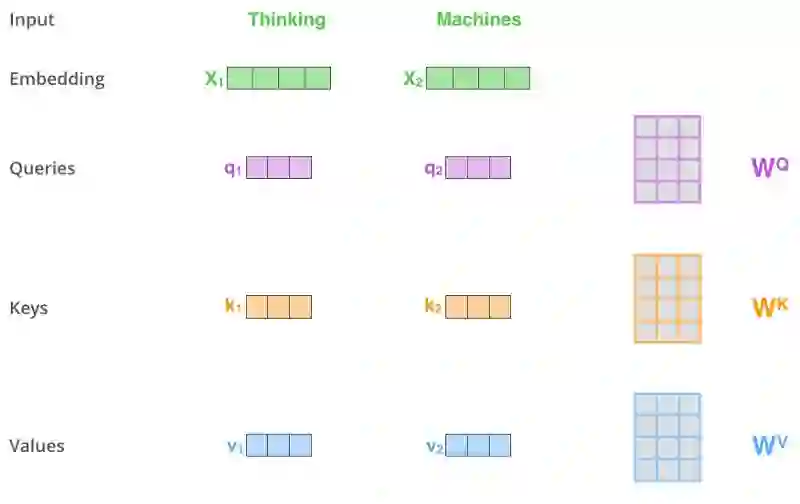
图片摘自此文:jalammar.github.io
将词向量x1乘以权重矩阵WQ得到q1,即与这个单词关联的“query”向量。这样,我们最终分别得到输入句子里每个单词的“query”,“key”和“value”投射。
那“query”, “key”和“value”向量是什么?
它们是一种抽象,在计算和考虑注意力时会被用到。如果你读了下文里关于注意力的计算方法,你就差不多明白各向量的角色。
计算self-attention的第二步是计算一项得分(score)。我们以计算句中第一个单词Thinking的self-attention为例。我们需要计算句中每个单词针对这个词的得分。当我们在特定的位置编码一个单词时,该得分决定了在输入句子的其他部分需要放多少焦点。
得分等于当前词的query向量与需评分词语的key向量的点积。因此,如果需要计算#1位置处单词的self-attention,第一个得分是q1与k1的点积,第二个得分就是q1和k2的点积。
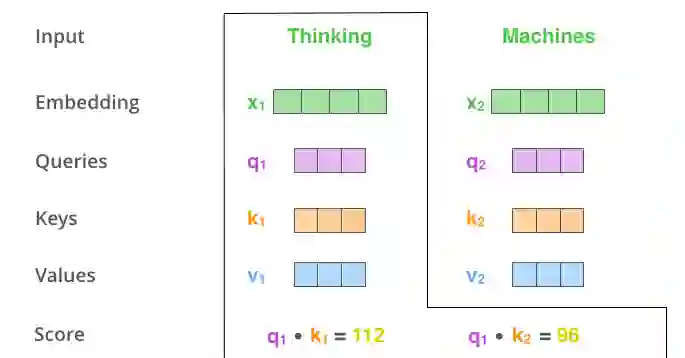
图片摘自此文:jalammar.github.io
第三第四步是将所有得分除以8(论文中取的是向量维数开根号— — 64,这样会得到更稳定的梯度。当然也可以用其他值,不过这是默认值),然后将结果放入一个softmax操作. softmax方法正则化这些得分,使它们都大于0且加和为1。
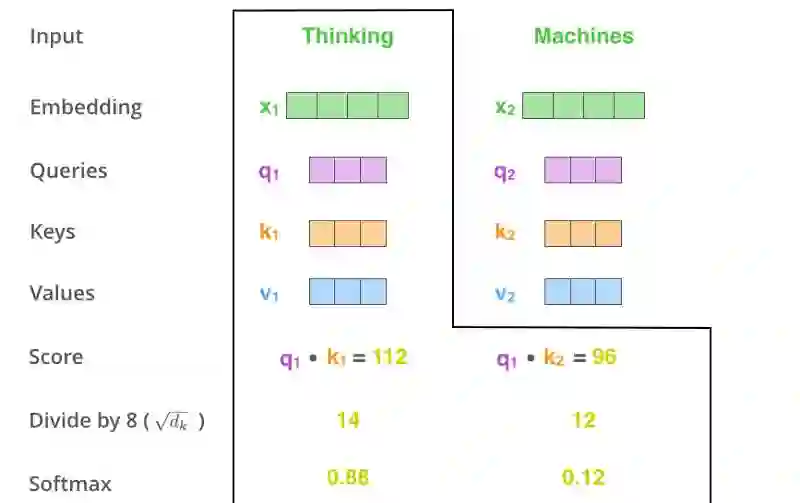
图片摘自此文:jalammar.github.io
这个经过softmax的score决定了该单词在这个位置表达了多少。很显然当前位置所在的单词会得到最高的softmax得分,不过有时候有助于算法注意到其他与当前单词相关的单词。
第五步,将每个value向量乘以softmax得分 (准备对它们求和)。这里的意图是保持需要聚焦的单词的value,并且去除不相关的单词(乘以一个很小的数字比如0.001)。
第六步,求和加权后的value向量。这就产生了(对于第一个单词)在self-attention层上此位置的输出。
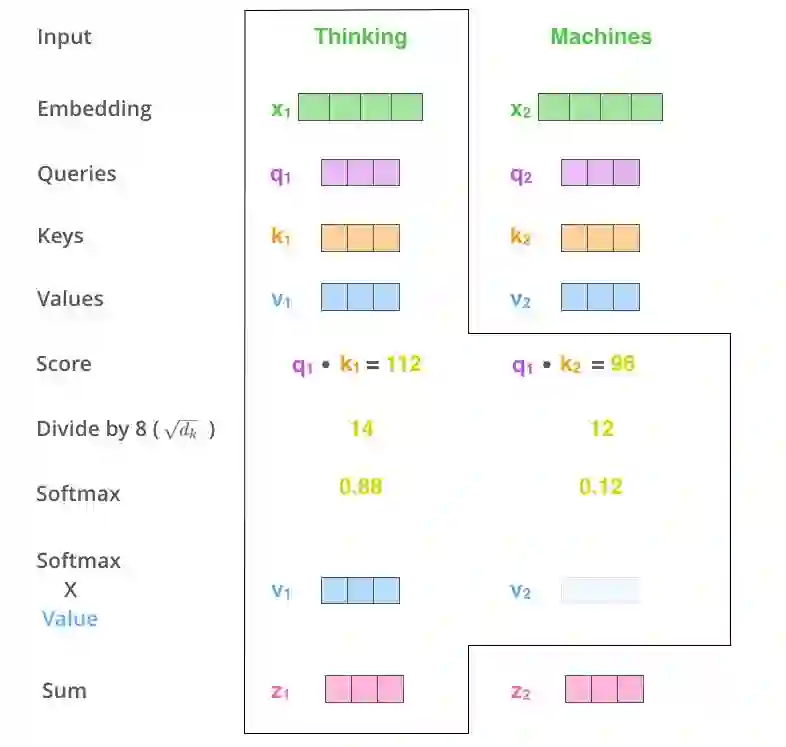
图片摘自此文:jalammar.github.io
这样self-attention计算就结束了。结果向量就可以拿来作为前馈神经网络的输入。不过实际实现中,考虑到性能该计算由矩阵形式运算完成。我们现在看一下,我们已经知道如何在词级别计算了。
Multihead attention
Transformer基本上就是这么工作的。此外还有一些其他细节使其工作得更好。比如,实现中使用了多头注意力的概念,而不是只在一个维度上计算注意力。
其背后的想法是,当你翻译一个单词时,基于不同的问题,会对于同一个单词产生不同的注意力,如下图所示。比如说当你在翻译“I kicked the ball”句中的“kicked”时,你会问“Who kicked”。由于问题不同,当翻译成另一种语言时结果可能改变。或者问了其他问题,比如“Did what?”,等…
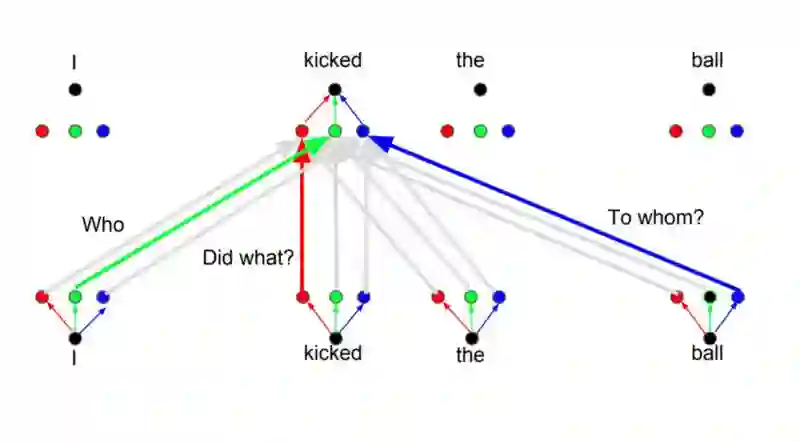
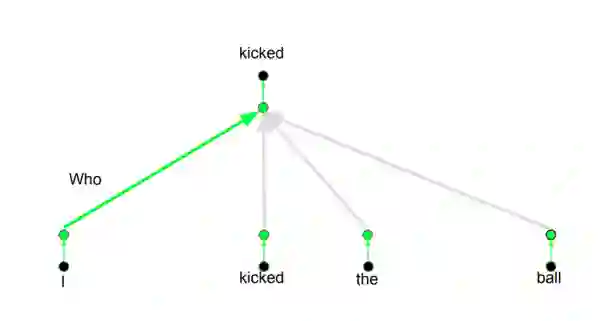
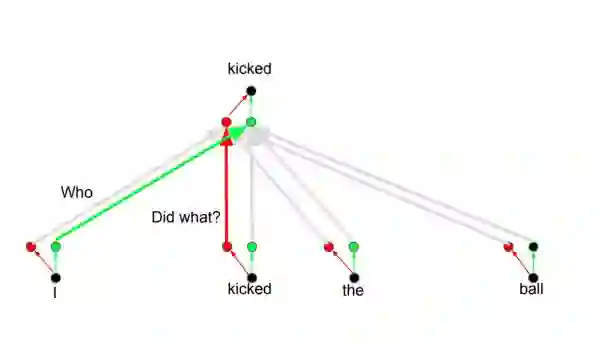
图片摘自此文:http://web.stanford.edu
Positional Encoding
Transfomer的另一个重要步骤是为每个词增加了位置编码。由于每个单词的位置与翻译相关,所以编码每个单词的位置是有用的。
总结
本文概述transformers是怎么工作的,以及在序列传导问题中使用的原因。如果你希望更深入的理解模型运作的原理及相关差异。推荐阅读以下帖子、文章和视频资料。
The Unreasonable Effectiveness of Recurrent Neural Networks
Understanding LSTM Networks
Visualizing A Neural Machine Translation Model
The Illustrated Transformer
The Transformer — Attention is all you need
The Annotated Transformer
Attention is all you need attentional neural network models
Self-Attention For Generative Models
OpenAI GPT-2: Understanding Language Generation through Visualization
WaveNet: A Generative Model for Raw Audio
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】或长按下方地址/二维码访问:
https://ai.yanxishe.com/page/TextTranslation/1558

AI求职百题斩 · 每日一题
每天进步一点点,扫码参与每日一题!

点击阅读原文,查看更多内容↙





