解密:OpenAI和DeepMind都用的Transformer是如何工作的
选自towardsdatascience
作者:Giuliano Giacaglia
机器之心编译
参与:Geek AI、张倩
Transformer 是一种越来越流行的神经网络架构。最近,OpenAI 将 Transformer 用到了他们的语言模型中, DeepMind 也将其用到了他们为击败顶级职业玩家所设计的 AlphaStar 程序中。本文将详解这一架构的工作原理。
Transformer 是为解决序列转换或神经机器翻译问题而设计的架构,该任务将一个输入序列转化为一个输出序列。 语音识别、文本转语音等问题都属于这类任务。

序列转换。绿色方框代表输入,蓝色矩形代表模型,紫色方框代表输出。
对于执行序列转换任务的模型来说,它们需要某种记忆能力。例如,让我们将下面的句子翻译成另一种语言:
“The Transformers” are a Japanese [[hardcore punk]] band. The band was formed in 1968, during the height of Japanese music history”
在本例中,第二句中的「band」一词指的是第一句中介绍的「The Transformers」乐队。当你在第二句中读到这支乐队时,你知道它指的是「The Transformers」乐队。这对翻译任务可能非常重要。此外,还有很多这样的例子,某句中的某个单词指的是前面句子中的单词。
注意力机制
为了解决这些问题,研究人员创造了一种将注意力分配到特定单词上的技术。
在翻译一个句子时,我们会特别注意正在翻译的单词。当转写录音时,我们会仔细聆听正在努力记下来的片段。如果让我描述一下我所在的房间,我会一边说一边环顾我所描述的物体的四周。
神经网络可以使用注意力机制实现相同的行为,将注意力集中在给出了信息的部分上。例如,一个循环神经网络(RNN)可以处理另一个 RNN 的输出。在每一个时间步上,它都会关注另一个 RNN 的输出的不同位置。
为了解决这些问题,神经网络使用了一种名为「注意力机制」的技术。对 RNN 来说,每个单词都有一个对应的隐藏状态,并且被一直传递给解码阶段,而不只是将整个句子编码在一个隐藏状态中。然后,在 RNN 的每一步中都会利用这些隐藏状态进行解码。下面的动图显示了完整的工作流程:

绿色显示的步骤被称为编码阶段,而紫色显示的步骤则是解码阶段。
这样做的理由是,在一个句子中的每个单词都可能有相关的信息。因此,为了让解码更加精确,模型需要使用注意力机制考虑输入的每一个单词。
为了在序列转换任务中将注意力机制引入到 RNN 中,我们将编码和解码分为两个主要步骤。一个步骤用绿色表示,另一个步骤用紫色表示。绿色的步骤被称为编码阶段,紫色的步骤被称为解码阶段。

绿色的步骤负责根据从输入中创建隐藏状态。我们没有像在使用注意力之前那样仅仅向解码器传递一个隐藏状态,而是将句子中每个单词生成的隐藏状态都传递给解码阶段。每一个隐藏状态都会在解码阶段被利用,从而找到神经网络应该施加注意力的地方。
例如,当把句子「Je suis étudiant」翻译成英文时,就需要解码步骤在翻译时关注不同的单词。

这个动图显示了将句子「Je suis étudiant」翻译成英文时,每个隐藏状态被赋予权重的过程。颜色越深,单词的权重就越大。
又或者,当你把句子「L’accord sur la zone économique européenne a été signé en août 1992.」从法文翻译成英文时,每个输入被赋予注意力的程度如下图所示:
将句子「L’accord sur la zone économique européenne a été signé en août 1992.」翻译成英文。
但是使用了注意力机制的 RNN 仍然不能解决一些我们讨论过的问题。例如,并行地处理输入(单词)是不可能的,对于大型的文本语料库来说,这增加了翻译文本要花费的时间。

卷积神经网络
卷积神经网络对解决这些问题有所帮助。通过卷积神经网络,我们可以:
轻松做到并行化处理(在每一层中)
利用局部的依赖
位置之间的距离是对数函数
一些最流行的用于序列转换任务的神经网络架构(如 Wavenet 和 Bytenet)都是基于卷积神经网络的。
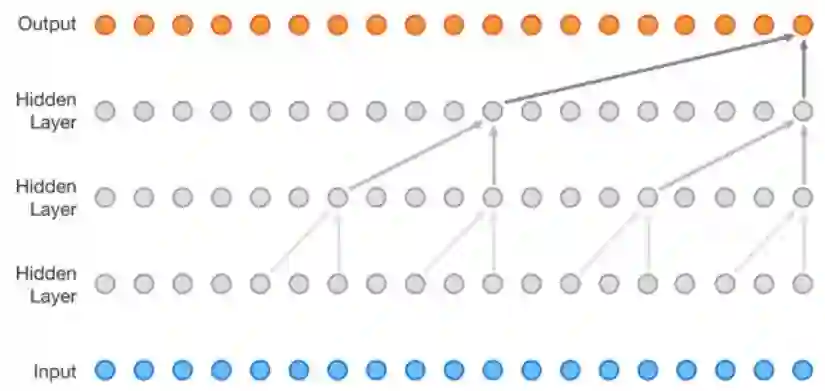
Wavenet 模型是一种卷积神经网络(CNN)。
卷积神经网络能够并行工作的原因是,输入的每个单词都可以被同时处理,而且并不一定需要依赖于之前有待翻译的单词。不仅如此,CNN 的时间复杂度是 log(N)阶的,这是从输出到输入生成的树的高度的大小(如上面的动图所示)。这要比 RNN 的输出到输入之间 N 阶的距离要短得多。
但问题是,卷积神经网络并不一定能够帮助我们解决翻译句子时的依赖关系的问题。这也就是「Transformer」模型被创造出来的原因,它是卷积神经网络和注意力机制的结合。
Transformer
为了解决并行计算的问题,Transformer 试着同时使用卷积神经网络和注意力模型。注意力模型提升了模型将一个序列转换为另一个序列的速度。
接下来,让我们看看 Transformer 是如何工作的吧。Transformer 是一类使用注意力机制加速运算的模型。更确切地说,Transformer 使用的是「自注意力机制」。
Transformer 的示意图。
在内部, Transformer 具有与前面的模型类似的架构。但是 Transformer 是由 6 个编码器和 6 个解码器组成的。

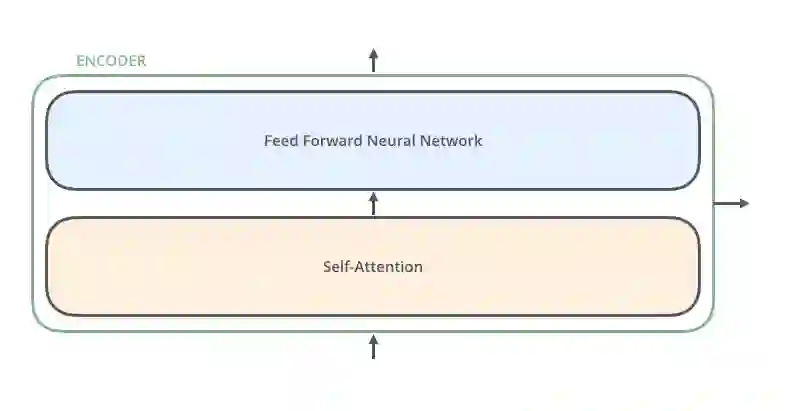
每个编码器互相之间都是类似的。所有的编码器都有相同的架构。解码器也都具有相同的特性,即解码器互相之间也很类似。每个编码器由一个「自注意力层」和一个「前馈神经网络」组成。

编码器的输入首先会流经一个「自注意力」层。它会帮编码器在对特定的单词进行编码时关注输入句子中其它的单词。解码器也有这两层,但解码器中的自注意力层和前馈神经网络层之间还有一个注意力层,该层会帮助解码器关注输入的句子中相关的部分。

自注意力机制
注:这一节摘选自 Jay Allamar 的博文(http://jalammar.github.io/illustrated-transformer/)。
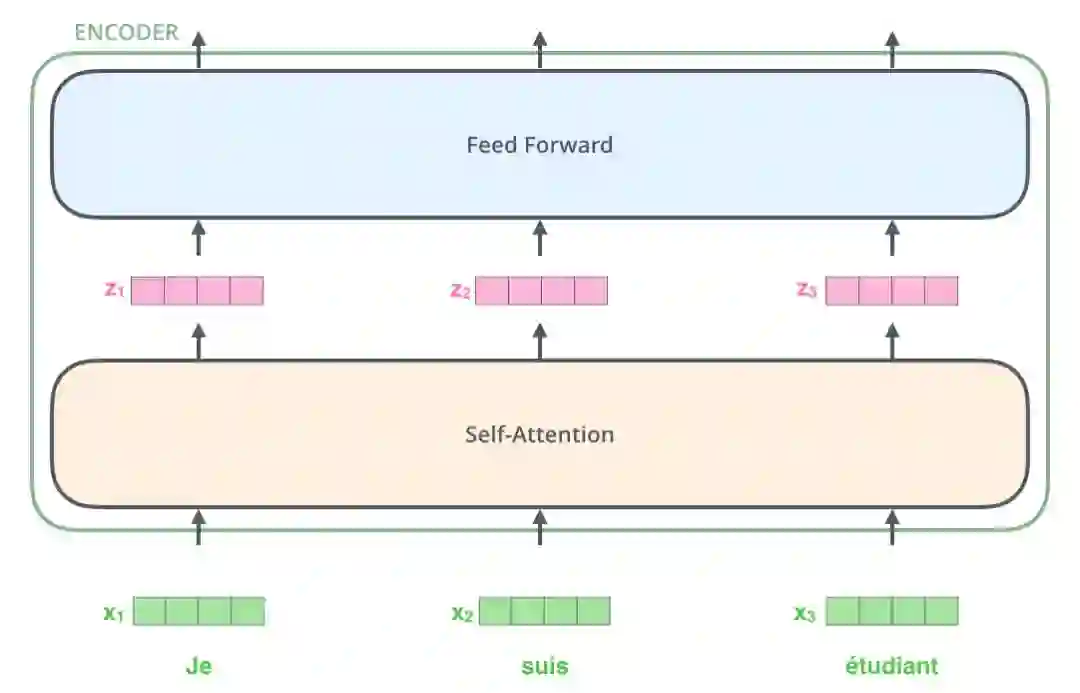
首先让我们来看看各种向量/张量,以及它们如何在这些组件之间流动,将一个训练过的模型的输入转化成输出。与一般的自然语言处理应用程序一样,我们首先将使用一个嵌入算法将每个输入的单词转换为向量形式。

每个单词都被嵌入到了一个 512 维的向量中。在本文中,我们将这些向量表示为上图中这样的简单的方框。
词嵌入过程仅仅发生在最底部的编码器中。所有的编码器所共有的抽象输入形式是,他们会接受一个 512 维的向量的列表。
在底部的编码器中,这种输入是词嵌入,而在其他的编码器中,输入则是紧接着的下一层编码器的输出。在对我们输入序列中的单词进行嵌入后,每个向量都会流经编码器的两层。
编码器内部结构示意图
这里将开始介绍 Transformer 的一个关键属性:每个位置的单词都会沿着各自的路径流经编码器。在自注意力层中,这些路径之间有相互依赖关系。然而在前馈层中则没有这样的依赖关系,因此可以在流经前馈层时并行处理各种路径。
接下来,我们使用一个更短的句子作为例子,看看每个子层中发生了什么。
自注意力
首先,让我们来看看如何使用向量计算自注意力,然后进一步看看这是如何使用矩阵来实现的。
找出一个句子中各单词之间的关系,为其赋予正确的注意力。
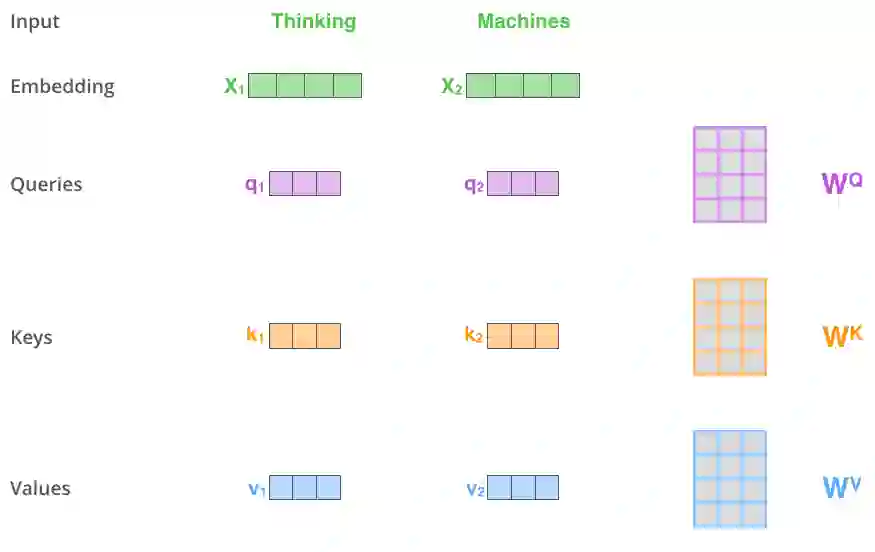
计算自注意力的第一步是根据每个编码器的输入向量(在本例中,是每个单词的嵌入)创建三个向量。因此,对于每个单词,我们会创建一个查询向量、一个键向量和一个值向量。这些向量是通过将嵌入乘以我们在训练过程中训练出的三个矩阵得到的。
请注意,这些新向量的维度比嵌入向量小。其维数为 64,而嵌入和编码器的输入/输出向量的维度为 512。这三个向量不必更短小,这种架构选择可以使多头注意力的计算过程(大部分)保持不变。
将 x1 与权值矩阵 WQ 相乘得到与该单词相关的「查询向量」 q1。我们最终为输入句子中的每个单词创建了一个「查询」、「键」和「值」的投影。
什么是「查询向量」、「键向量」和「值向量」?
这三个向量是对注意力进行计算和思考时非常有用的抽象概念。阅读下面关于注意力计算方法的有关内容,你就会对这些向量的作用有一个很好的认识。
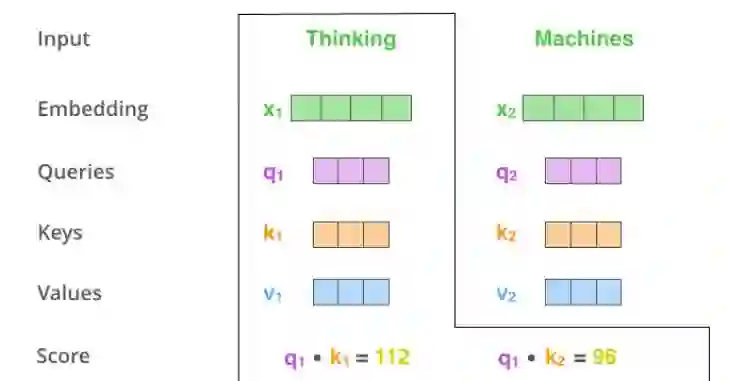
计算自注意力的第二步是计算出(某个单词的查询向量与其它单词的键向量相乘)的得分。假设我们正在计算本例中第一个单词「Thinking」的自注意力。我们需要计算出输入句子中每一个单词对于「Thinking」的打分。在我们对某个特定位置上的单词进行编码时,该得分决定了我们应该对输入句子中其它的部分施以多少关注。
该得分是通过将查询向量分别和我们正在打分的单词的键向量做点乘得到的。所以,假设我们正在计算位置 #1 的自注意力,第一个得分就是 q1 和 k1 的点积。第二个分数就是 q1 和 k2 的点积。
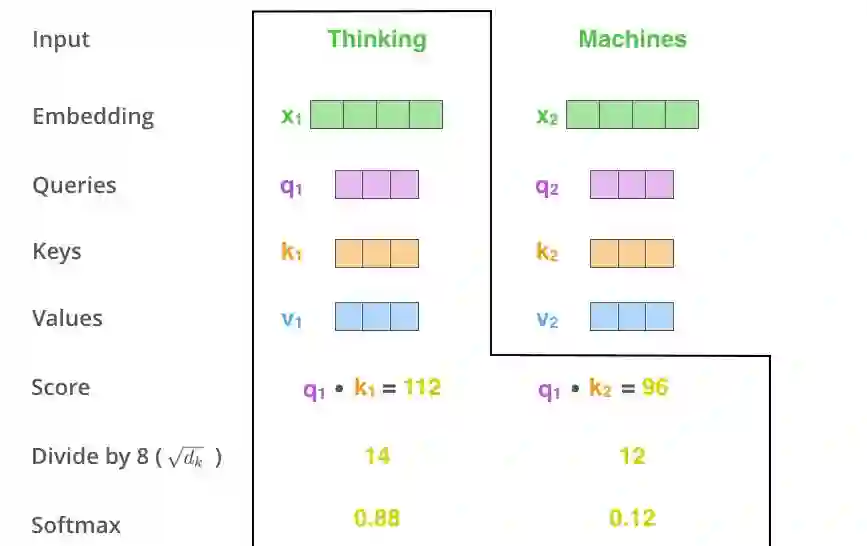
第三步和第四步是将第二步得到的得分除以 8(文中使用的键向量的维度(64)的平方根。这会让我们得到更稳定的梯度。这里也可以除以其它的值,但本文给出的是默认情况),然后将做除法的结果传递给 softmax 运算。Softmax 会将这些分数进行归一化,使它们都为正值,而且加起来等于 1。
这个 softmax 处理后的得分决定了每个单词在这个位置上被「表达」的程度。显然,该位置上本身存在的单词会得到最高的 softmax 值,但是有时关注与当前编码单词相关的另一个单词是很有用的。
第五步是将每个值向量与 softmax 得分相乘(为对其求和做准备)。这里的直观理解是,将我们想要关注的单词的值维持在较高水平,并且忽略那些不相关的单词(例如,通过将它们的值与 0.001 这样极小的数字相乘)。
第六步是对加权值后的值向量求和。该步骤将生成当前编码位置上(第一个单词)的自注意力层的输出。
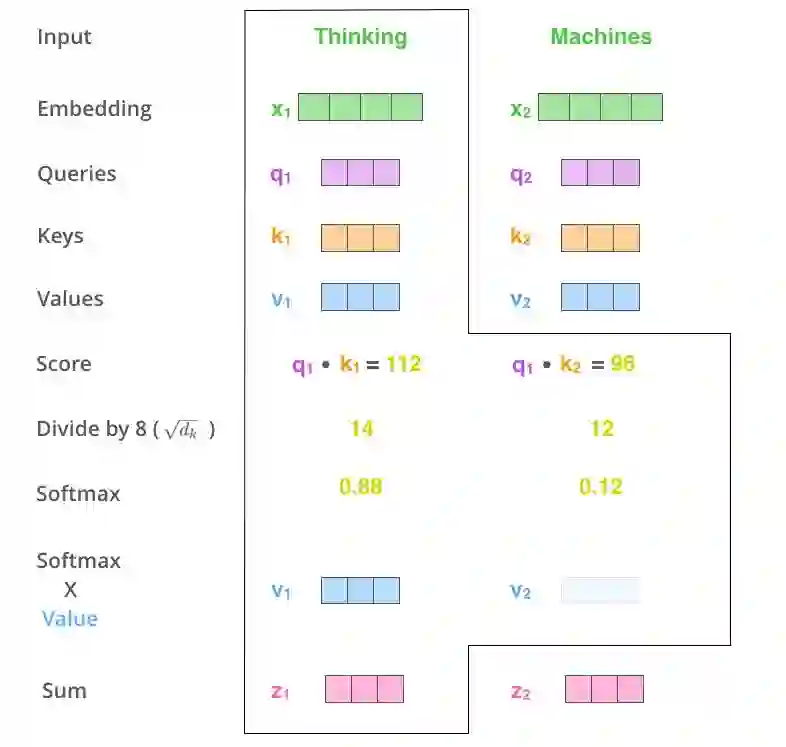
这就是自注意力机制计算过程得到的结果。我们可以将最终得到的向量传递给前馈神经网络。然而,在实际的实现中,为了加快处理速度,这种计算是以矩阵的形式进行的。
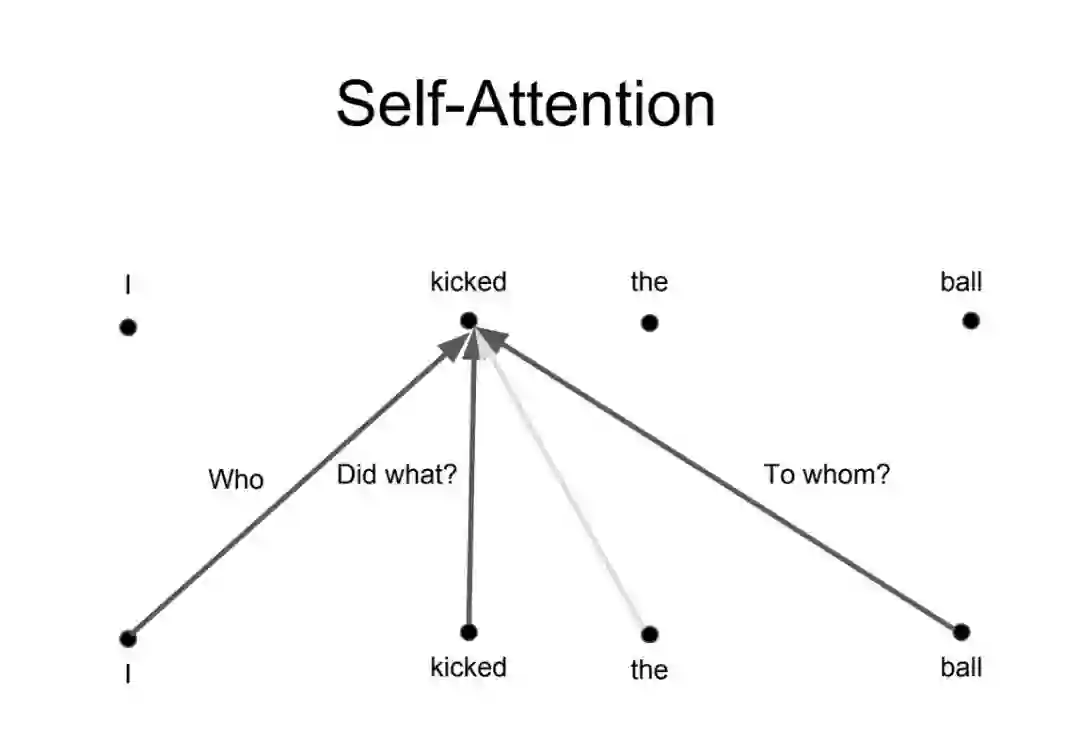
多头注意力
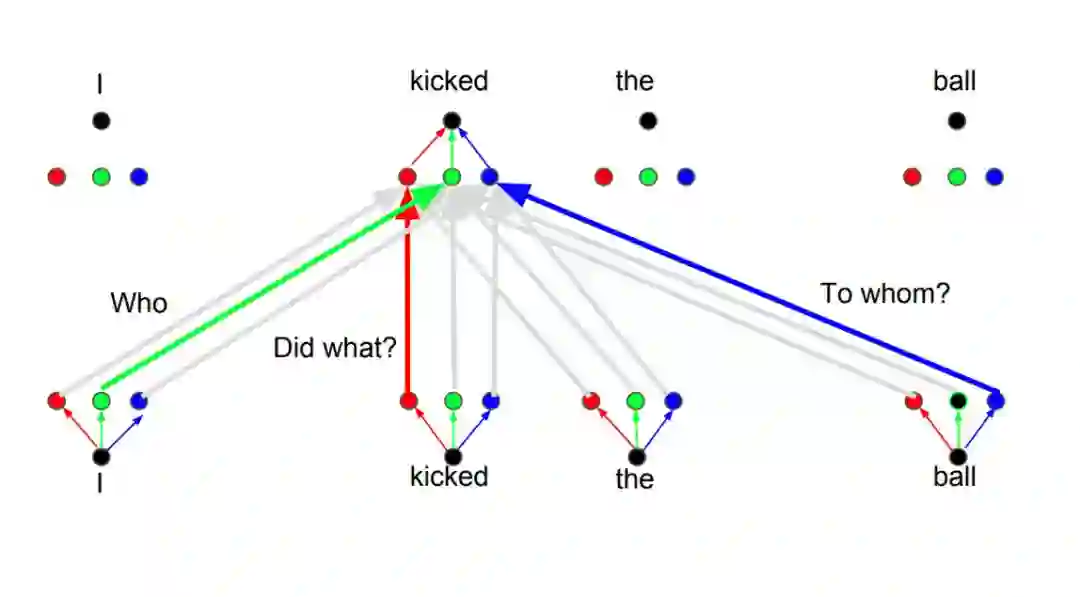
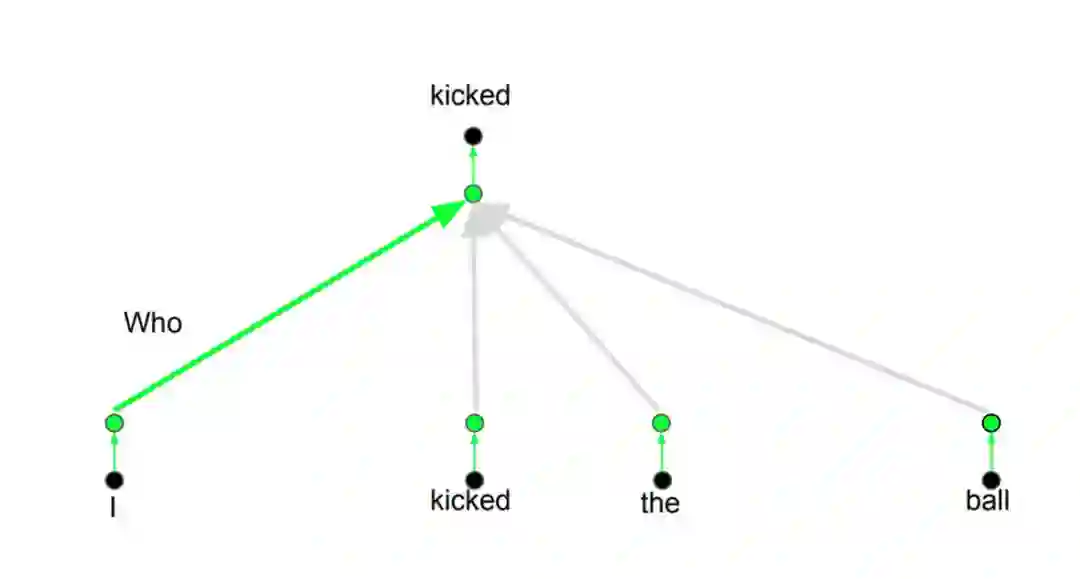
基本上,Transformer 就是这样工作的。但还有一些小的细节可以让它们工作地更好。例如,Transformer 使用了多头注意力机制的概念,而不是仅仅在一个维度上让单词彼此关注。
多头注意力机制背后的想法是,每当你翻译一个单词时,你可能会基于你所问的问题的类型对每个单词赋予不同的注意力。下图对这种想法的意义进行了说明。例如,当你翻译句子「I kicked the ball」(我踢了球)时,你可能会问「是谁踢了?」而根据答案的不同 ,将该单词翻译成另一种语言的结果可能会有所变化。或者你也可能会问其它的问题,例如「做了什么?」等等。

位置编码
Transformer 中另一个重要的步骤就是在对每个单词进行编码的时候加入了位置编码。对每个单词的编码之间都是相互关联的,因为每个单词的位置与其翻译结果相关。

原文链接:https://towardsdatascience.com/transformers-141e32e69591
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





